Topic modeling of tweets
Analyzing Social Media Data in R

Vivek Vijayaraghavan
Data Science Coach
Topic and Document

Topic and Document

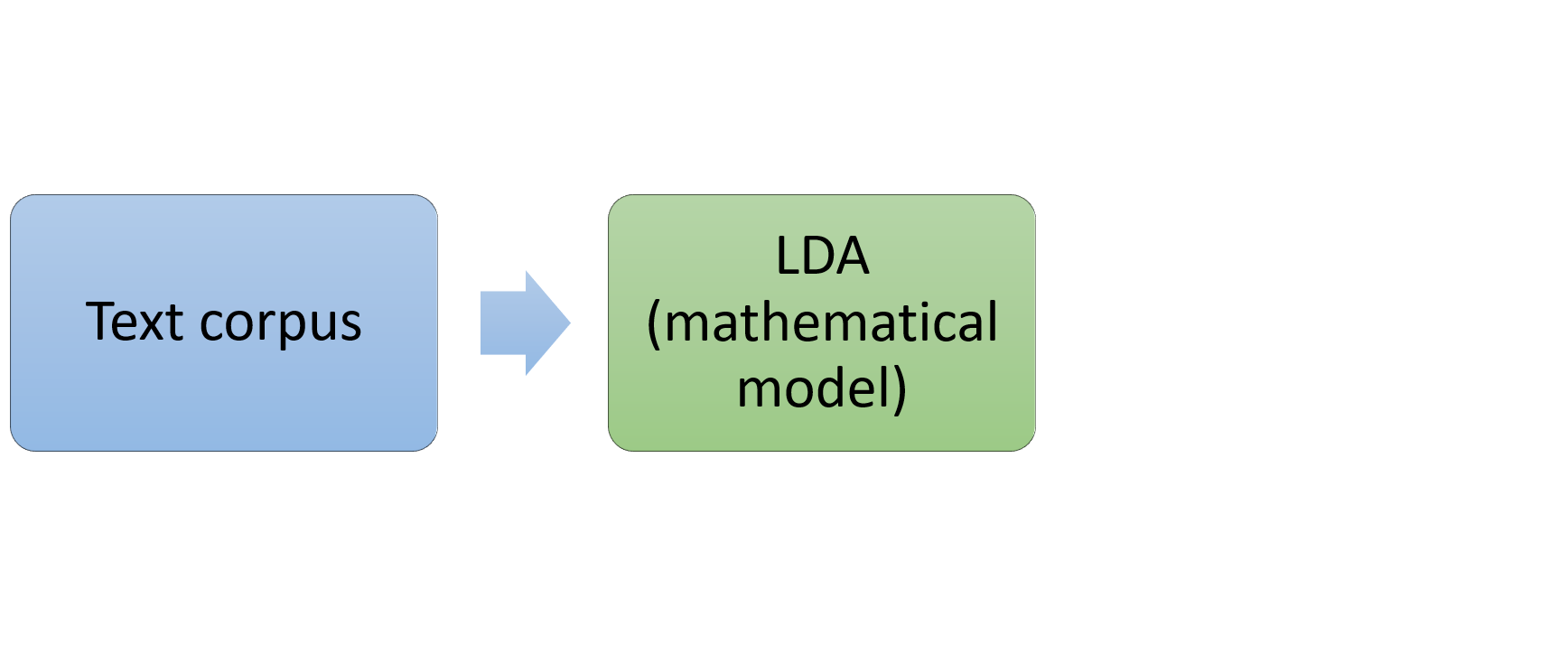
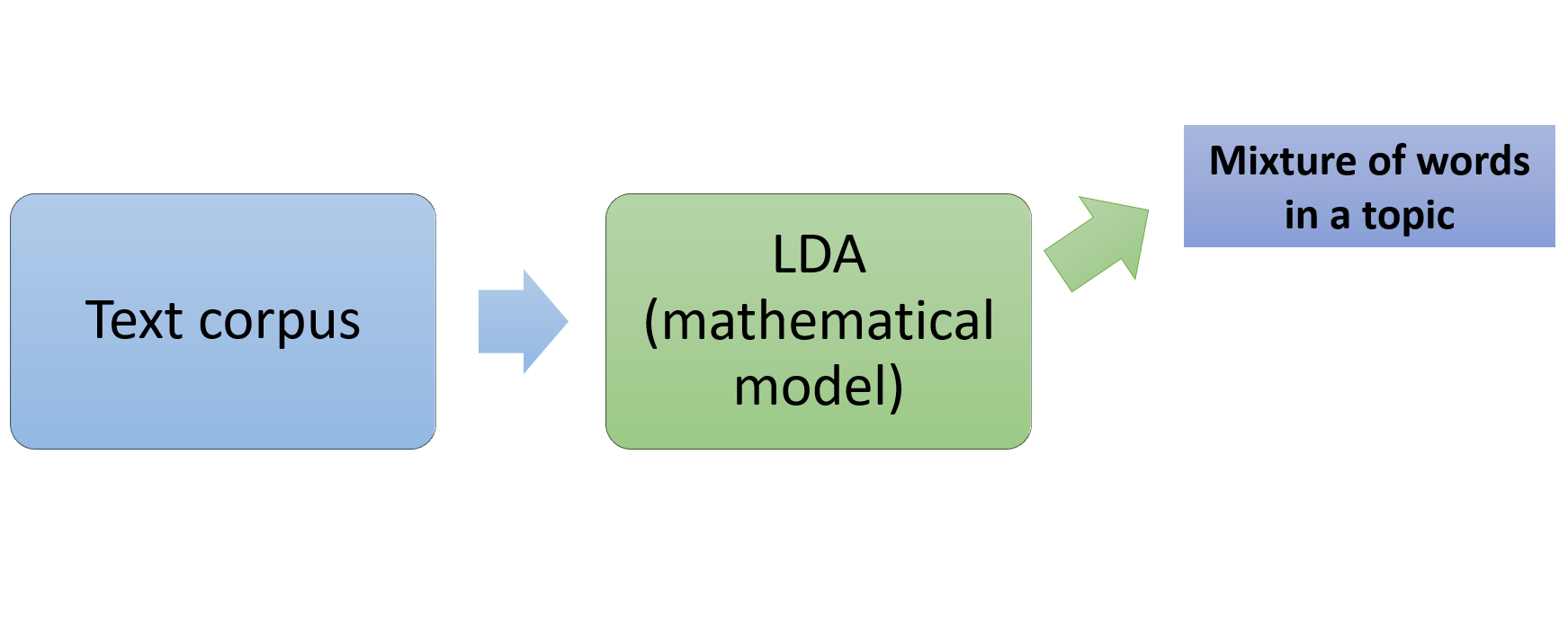
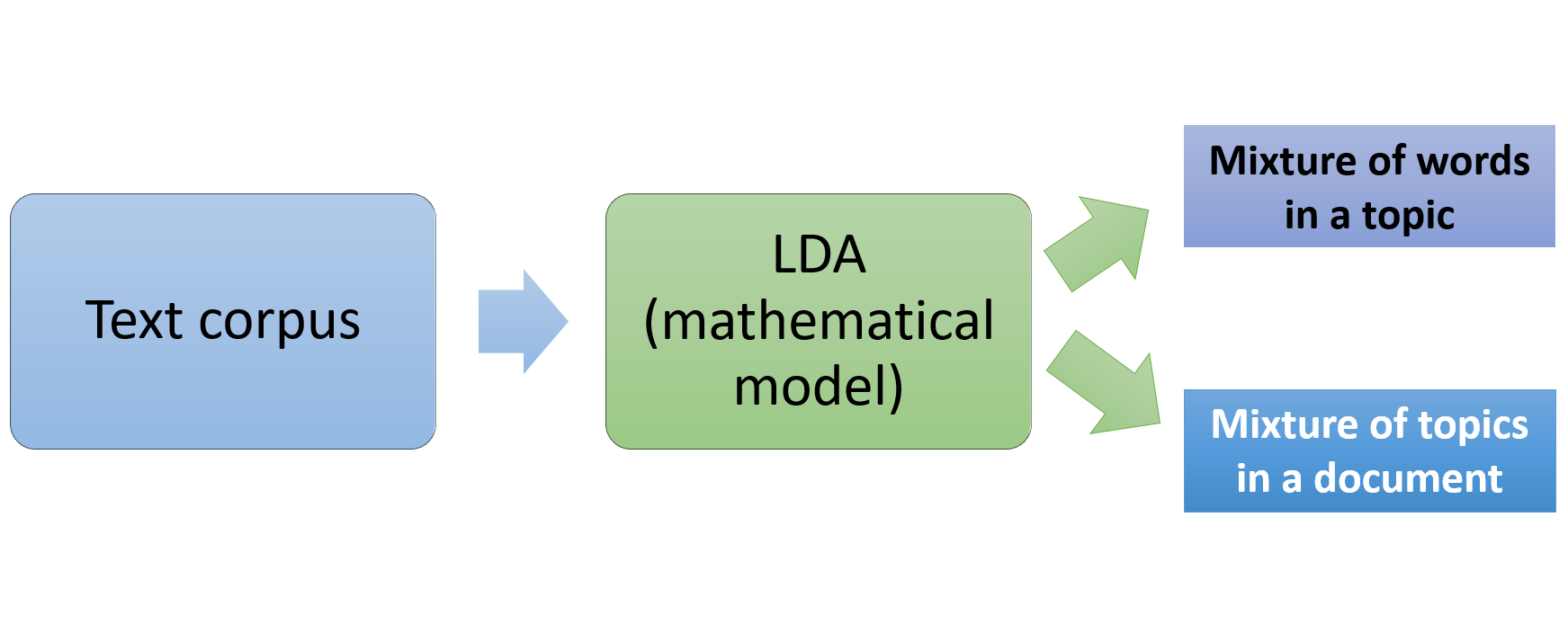
How LDA works
- Latent Dirichlet Allocation algorithm for topic modeling
How LDA works
How LDA works
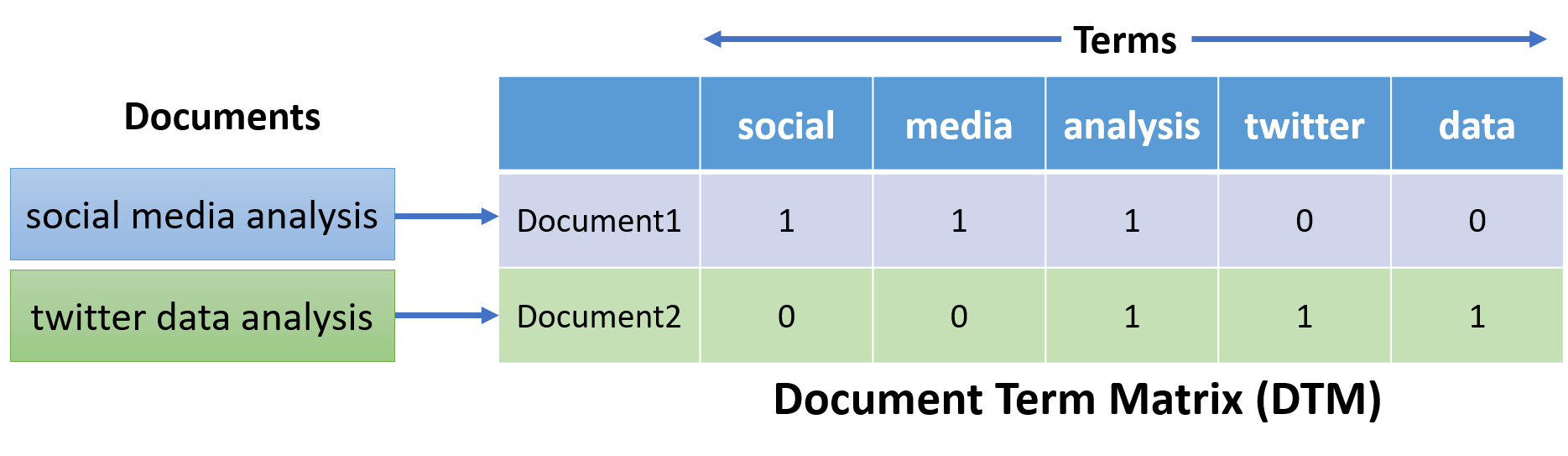
Document term matrix (DTM)
- Create a document term matrix
- DTM is a matrix representation of a corpus
- Documents are rows and words or terms are columns