Processing twitter text
Analyzing Social Media Data in R

Vivek Vijayaraghavan
Data Science Coach
Steps in text processing

Steps in text processing

Steps in text processing
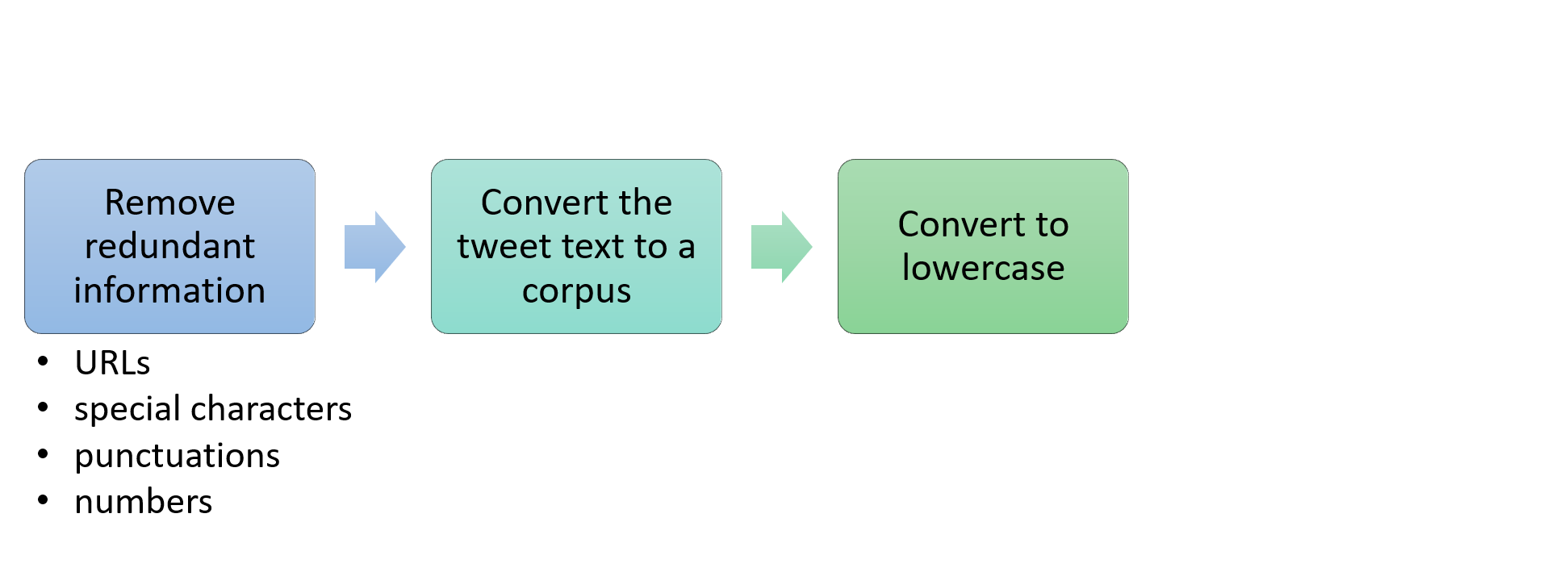
Steps in text processing
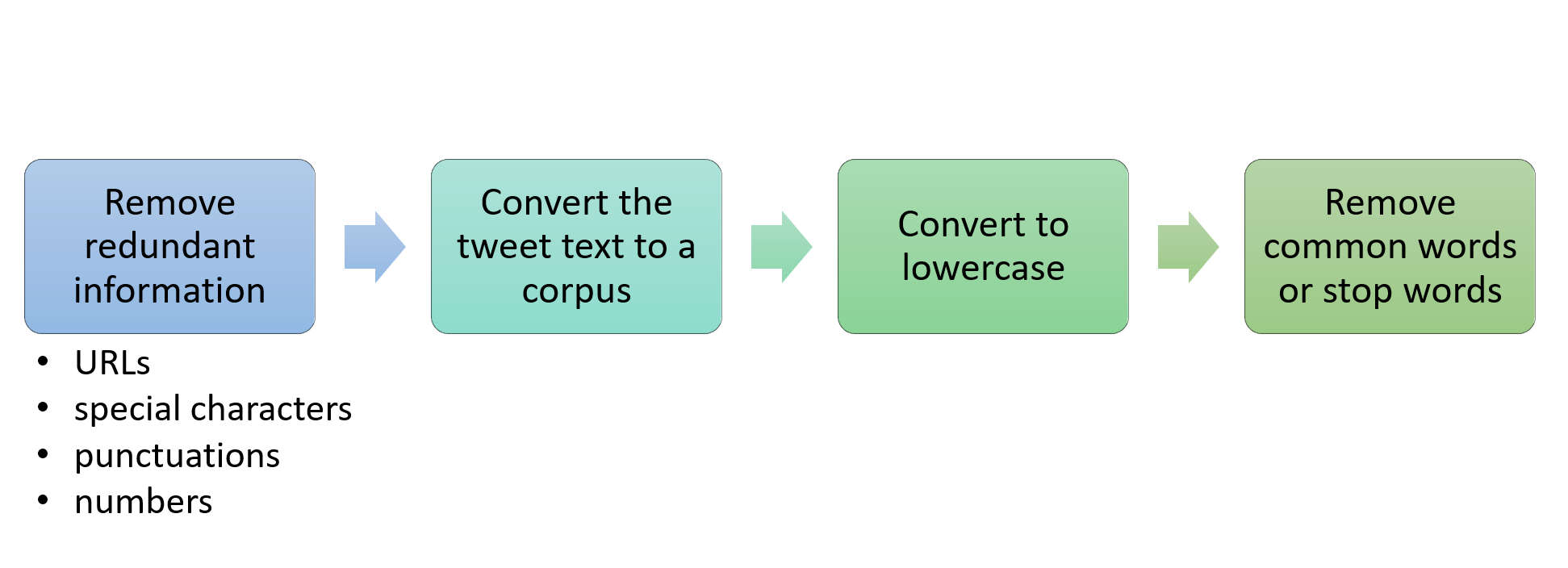
What are stop words?
- Stop words are commonly used words like a, an, and but
# Common stop words in English
stopwords("english")


