Standardizing features
Predicting CTR with Machine Learning in Python

Kevin Huo
Instructor
Scaling data
- Standard scaling converts all features to have mean of 0 and standard deviation of 1
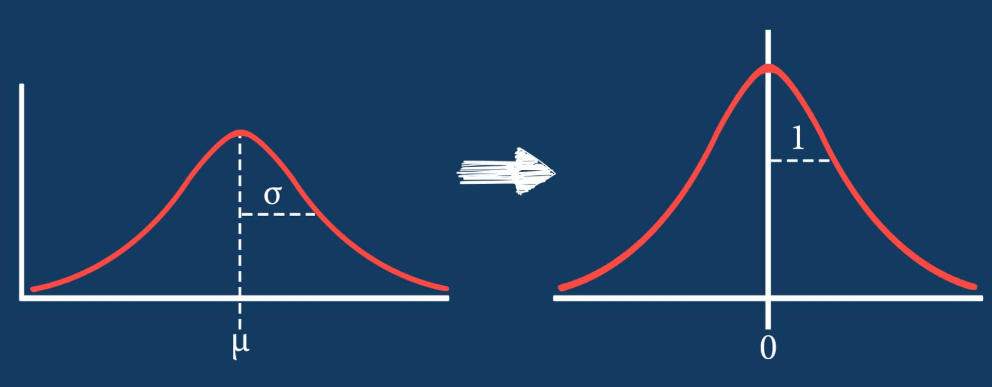
- Generally a good practice for machine learning models
Predicting CTR with Machine Learning in Python
Kevin Huo
Instructor

