Mean imputation
Handling Missing Data with Imputations in R

Michal Oleszak
Machine Learning Engineer
Mean imputation
Mean imputation works well for time-series data that randomly fluctuate around a long-term average.
For cross-sectional data, mean imputation is often a very poor choice:
- Destroys relations between variables.
- There is no variance in the imputed values.
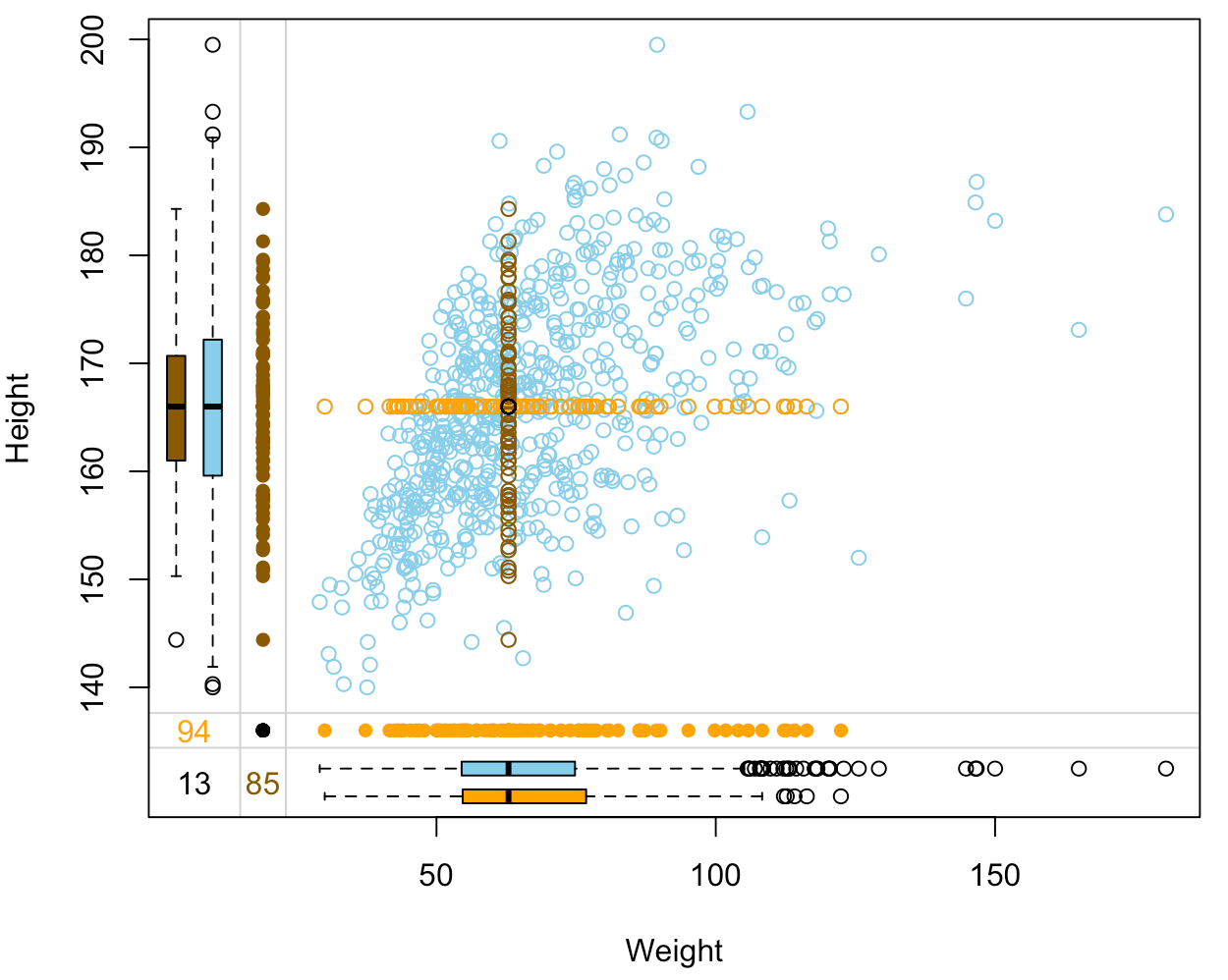
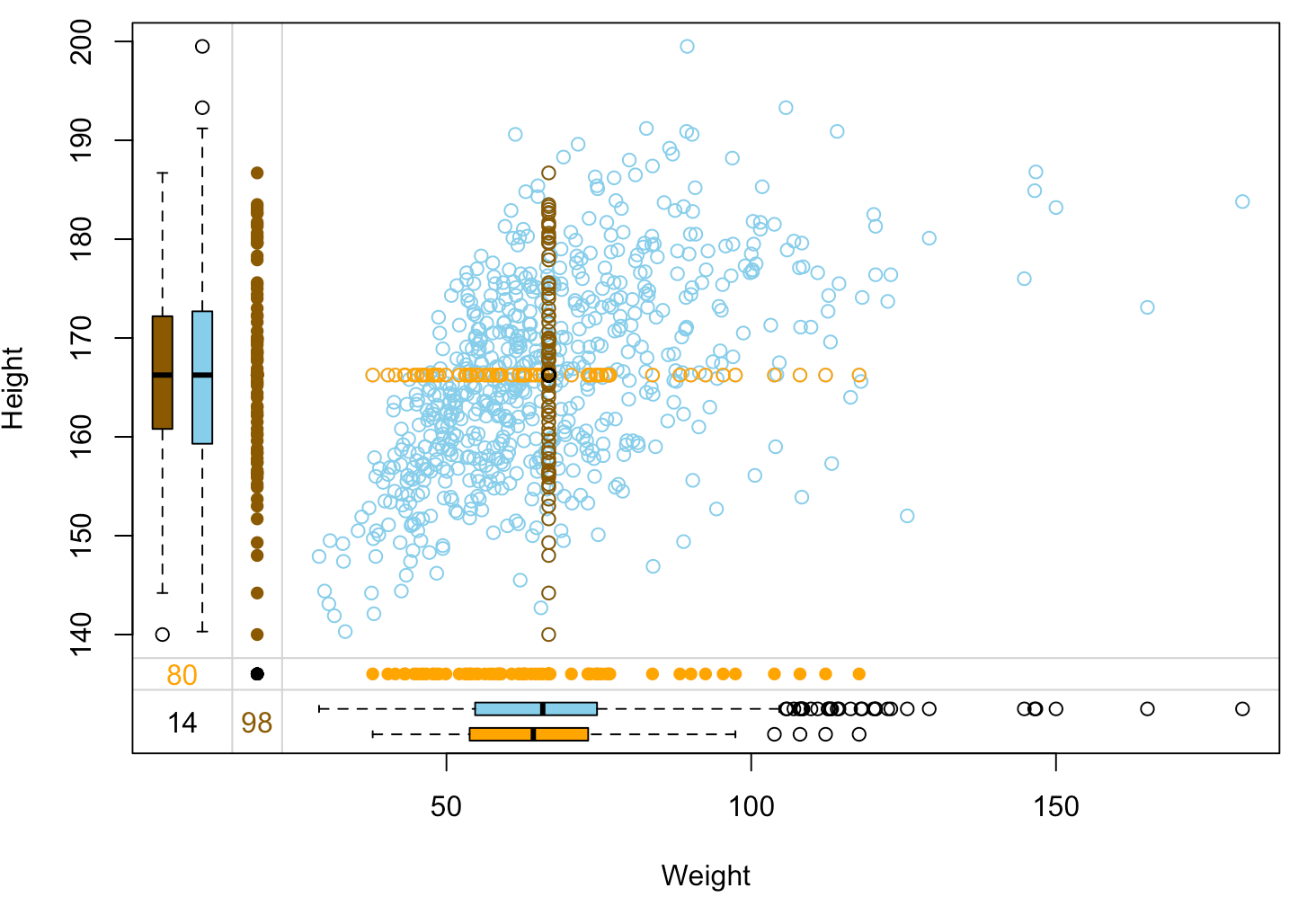
Assessing imputation quality: margin plot
nhanes_imp %>% select(Weight, Height, Height_imp, Weight_imp) %>% marginplot(delimiter="imp")
Median and mode imputation