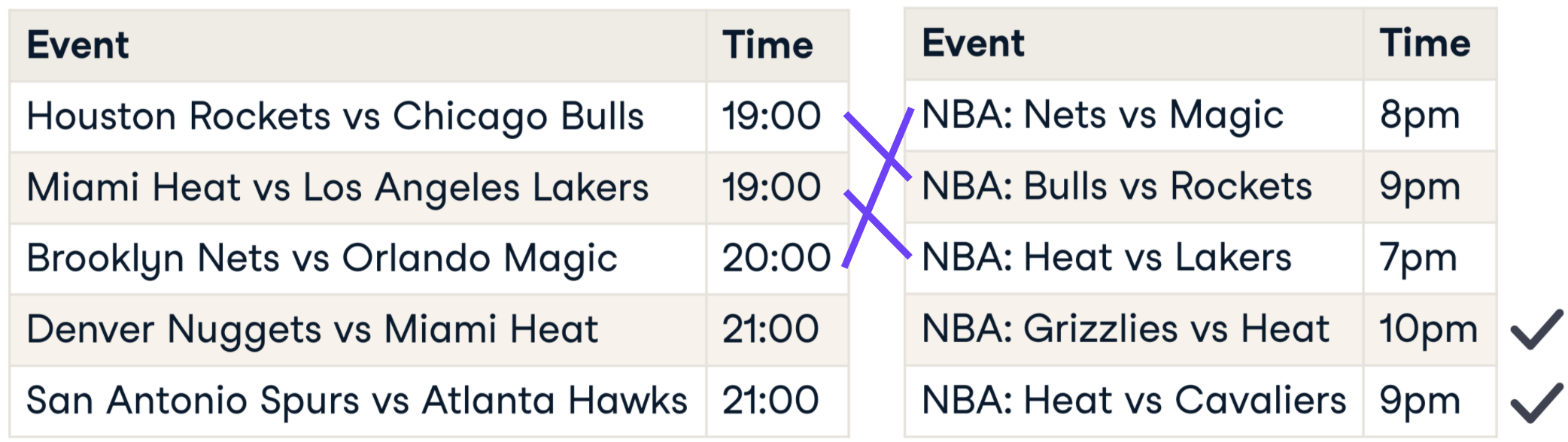
Comparing strings
Cleaning Data in Python

Adel Nehme
VP of AI Curriculum, DataCamp
Minimum edit distance
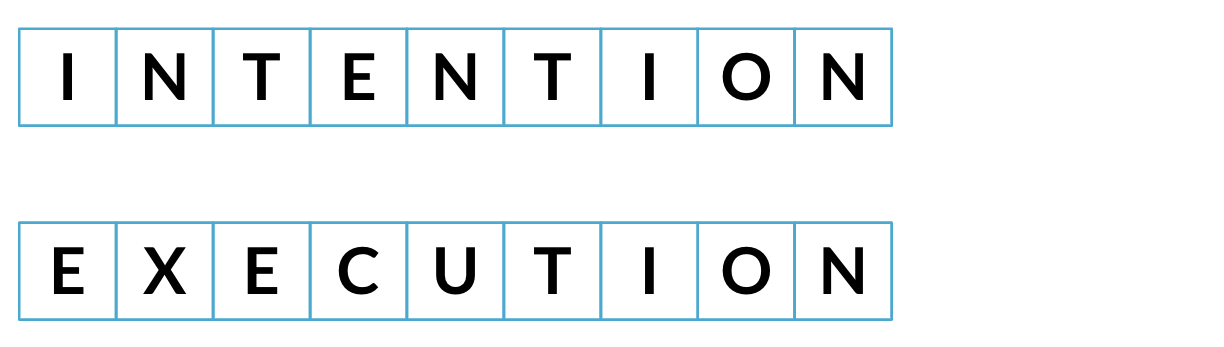
Least possible amount of steps needed to transition from one string to another
Minimum edit distance
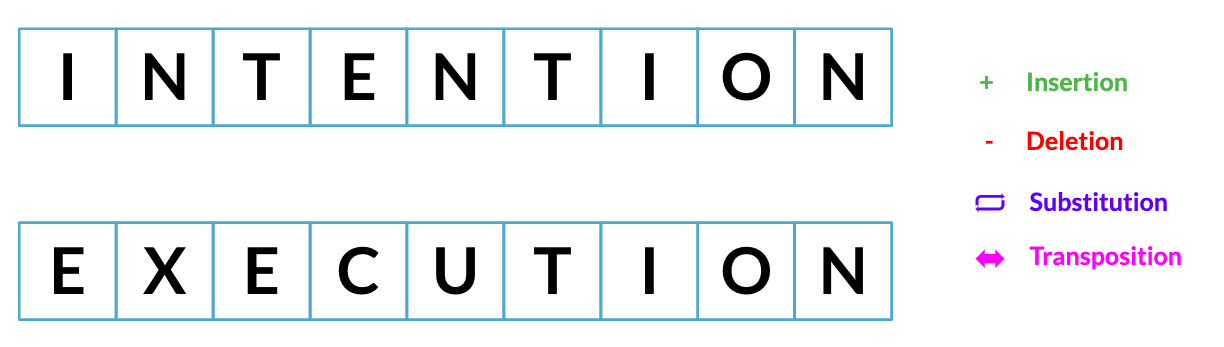
Least possible amount of steps needed to transition from one string to another
Minimum edit distance

Minimum edit distance
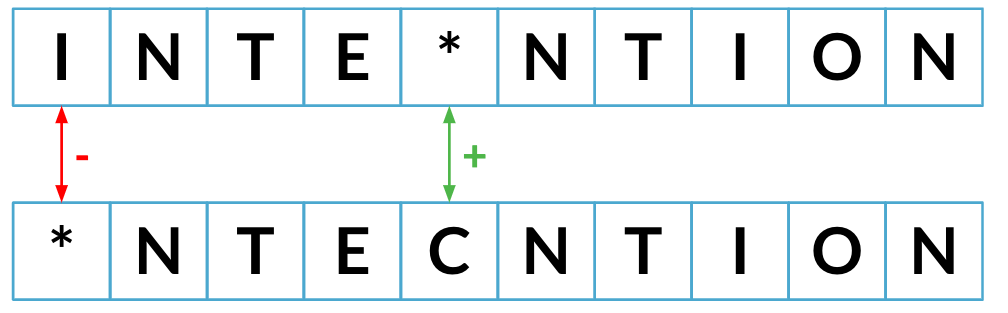
Minimum edit distance so far: 2
Minimum edit distance
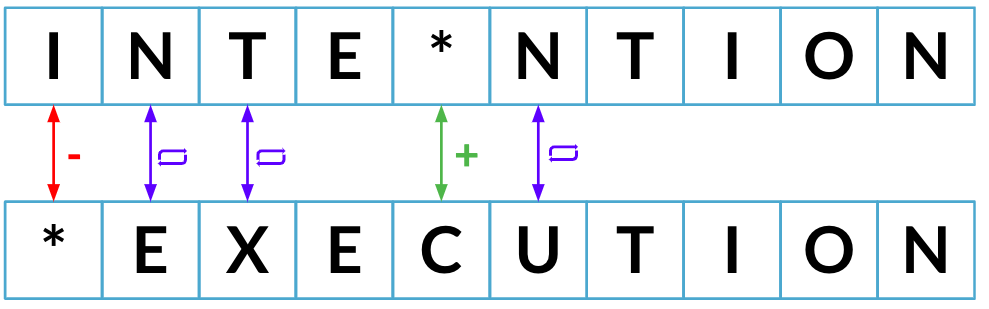
Minimum edit distance: 5
Minimum edit distance

Record linkage