Membership constraints
Cleaning Data in Python

Adel Nehme
Content Developer @DataCamp
Why could we have these problems?

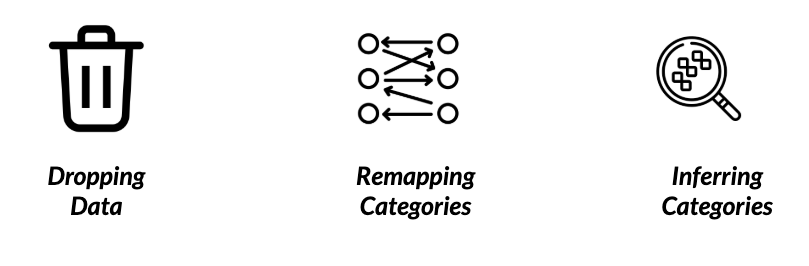
How do we treat these problems?
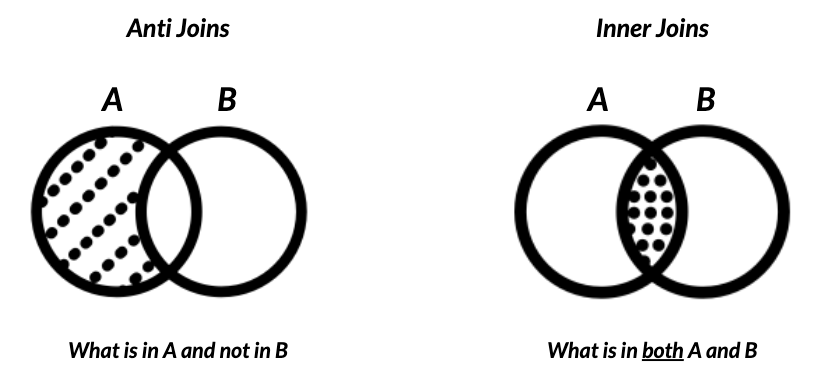
A note on joins
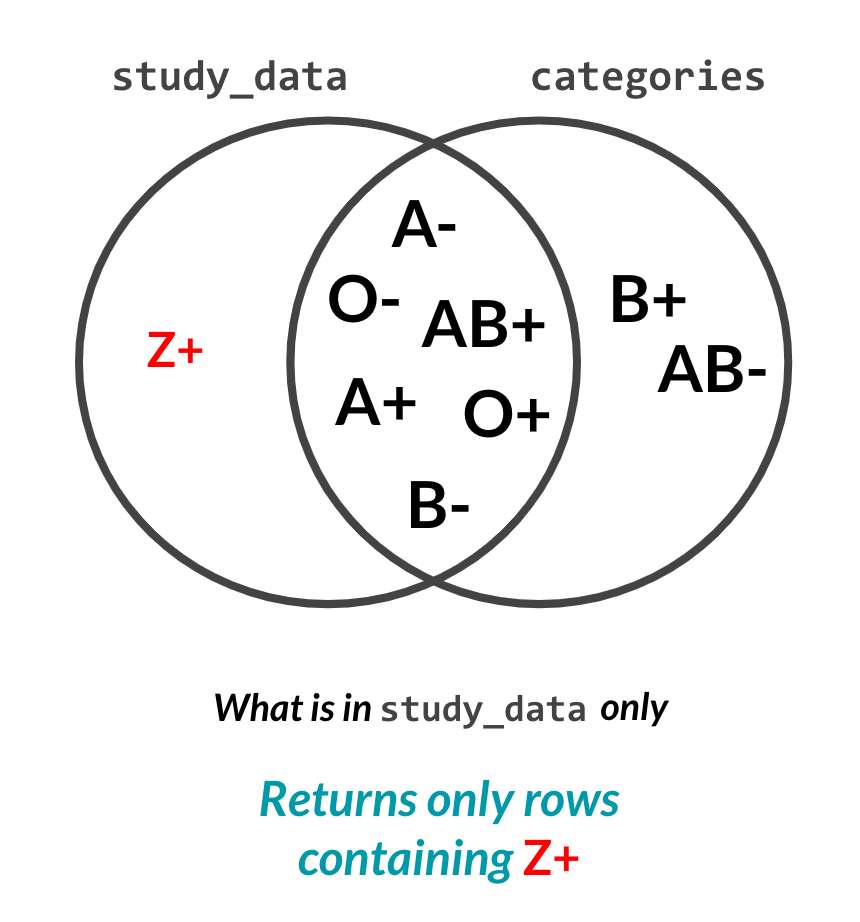
A left anti join on blood types
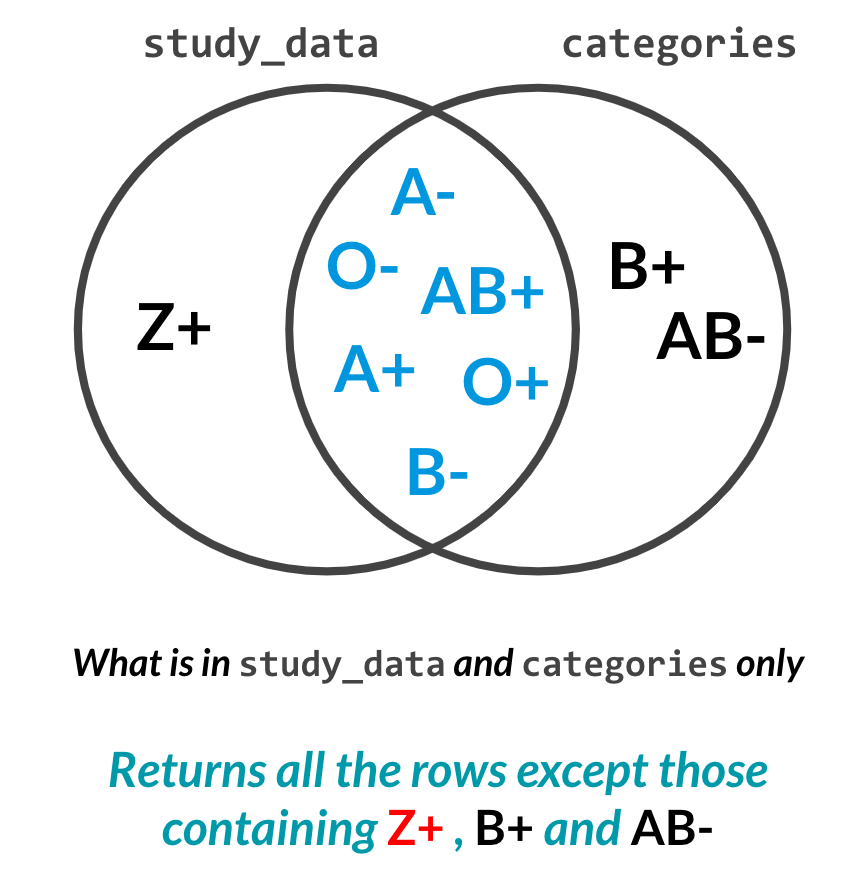
An inner join on blood types
Cleaning Data in Python
Adel Nehme
Content Developer @DataCamp

