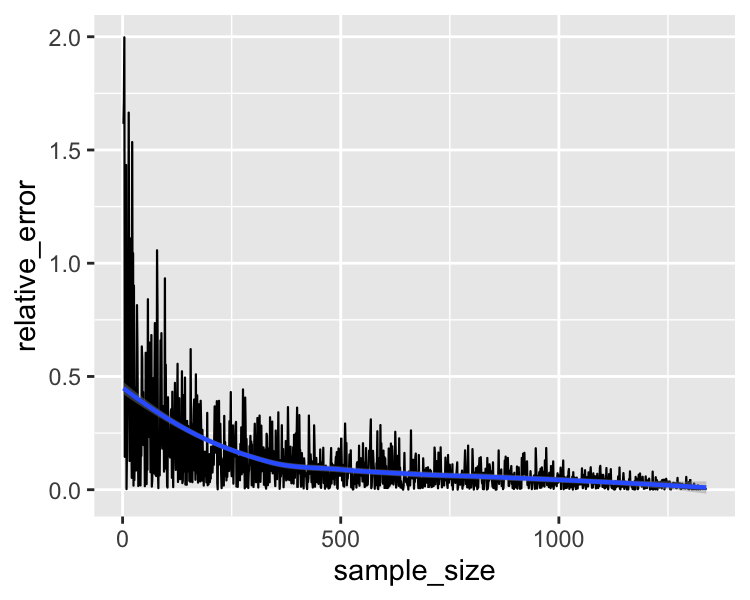
Population parameter
population_mean <- coffee_ratings %>%
summarize(mean_points = mean(total_cup_points)) %>%
pull(mean_points)
Point estimate
sample_mean <- coffee_ratings %>%
slice_sample(n = sample_size) %>%
summarize(mean_points = mean(total_cup_points)) %>%
pull(mean_points)
Relative error as a percentage
100 * abs(population_mean - sample_mean) / population_mean