Creating a sampling distribution
Sampling in R

Richie Cotton
Data Evangelist at DataCamp
Distribution of sample means for size 30
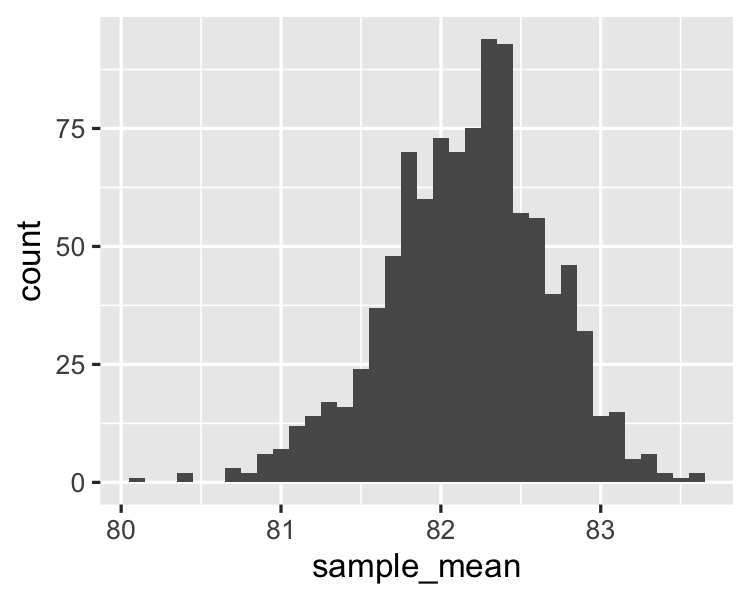
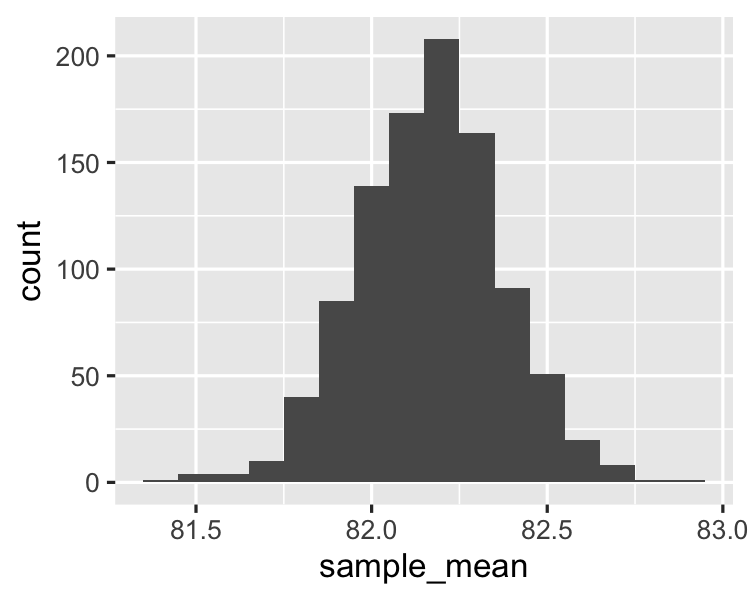
Different sample sizes
Sample size 6
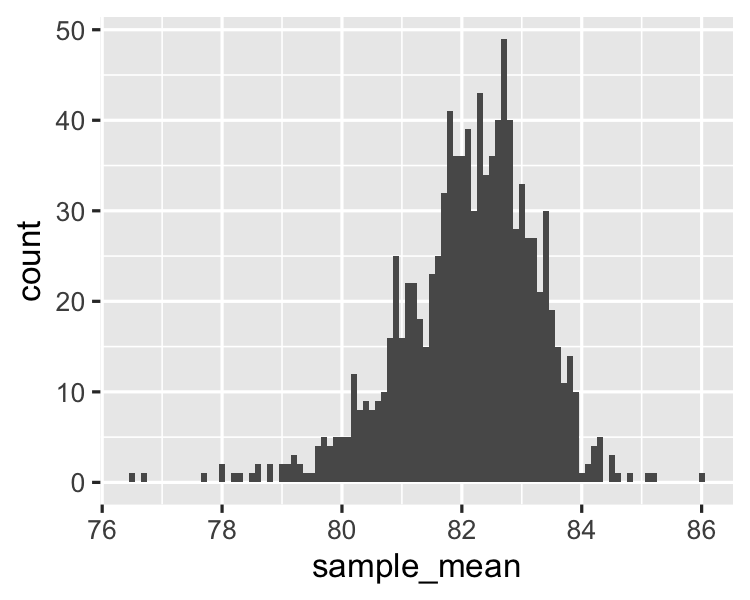
Sample size 150
Sampling in R
Richie Cotton
Data Evangelist at DataCamp
Sample size 6
Sample size 150

