<html>
<body>
<div>
<p>The first paragraph.</p>
</div>
<div>
Not an actual paragraph,
but with a <a href="#">link</a>.
</div>
<p>A paragraph without an
enclosing div.</p>
</body>
</html>
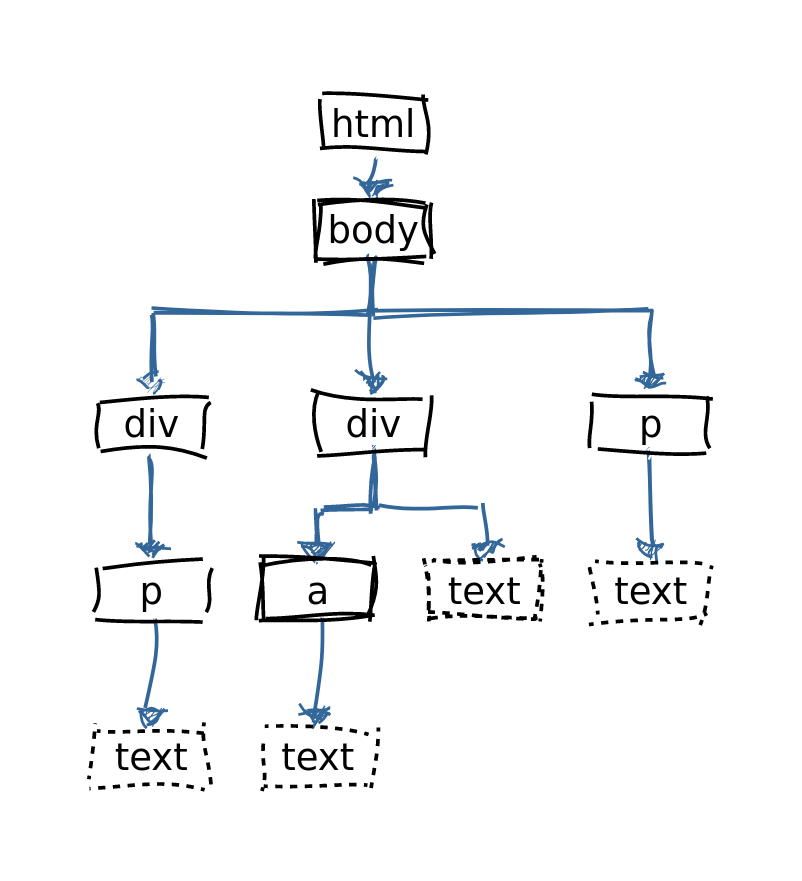
HTML is like a tree
<html>
<body>
<div>
<p>The first paragraph.</p>
</div>
<div>
Not an actual paragraph,
but with a <a href="#">link</a>.
</div>
<p>A paragraph without an
enclosing div.</p>
</body>
</html>
HTML is like a tree
<html>
<body>
<div>
<p>The first paragraph.</p>
</div>
<div>
Not an actual paragraph,
but with a <a href="#">link</a>.
</div>
<p>A paragraph without an
enclosing div.</p>
</body>
</html>
Navigating the tree with rvest
<html>
<body>
<div>
<p>The first paragraph.</p>
</div>
<div>
Not an actual paragraph,
but with a <a href="#">link</a>.
</div>
<p>A paragraph without an
enclosing div.</p>
</body>
</html>
html <- read_html(html_document)
html_children(html)
{xml_nodeset (1)}
[1] <body>\n <div>\n < ...
html %>% html_children()
html %>% html_children() %>% html_text()
[1] "\n \n The first paragraph.\n
\n \n Not an actual paragraph, \n
but with a link.\n \n A paragraph ...
Navigating to nodes with selectors
<html>
<body>
<div>
<p>The first paragraph.</p>
</div>
<div>
Not an actual paragraph,
but with a <a href="#">link</a>.
</div>
<p>A paragraph without an
enclosing div.</p>
</body>
</html>
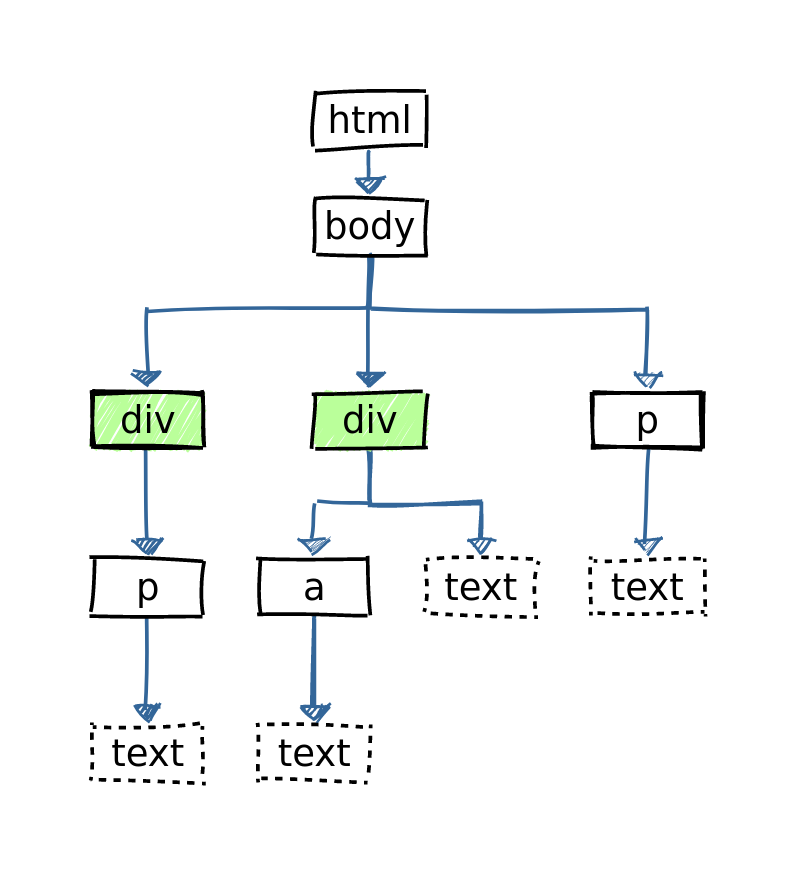
html <- read_html(html_document)
html %>% html_element('body')
{xml_nodeset (1)}
[1] <body>\n <div>\n < ...
html %>% html_elements('div p')
{xml_nodeset (1)}
[1] <p>The first paragraph.</p>
Navigating to nodes with selectors
<html>
<body>
<div>
<p>The first paragraph.</p>
</div>
<div>
Not an actual paragraph,
but with a <a href="#">link</a>.
</div>
<p>A paragraph without an
enclosing div.</p>
</body>
</html>
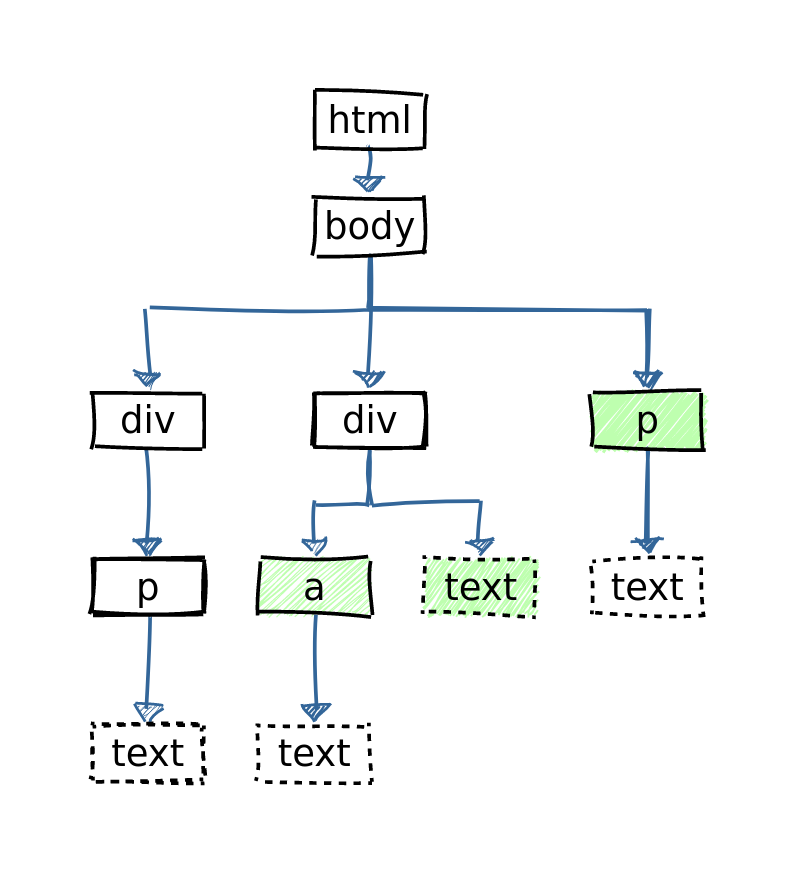
html %>% html_elements('p')
{xml_nodeset (2)}
[1] <p>The first paragraph.</p>
[2] <p>A paragraph without an enclosi...
html %>% html_elements('div') %>%
html_elements('p')