Making content-based recommendations
Building Recommendation Engines in Python

Rob O'Callaghan
Director of Data
Introducing the Jaccard similarity
Jaccard similarity:
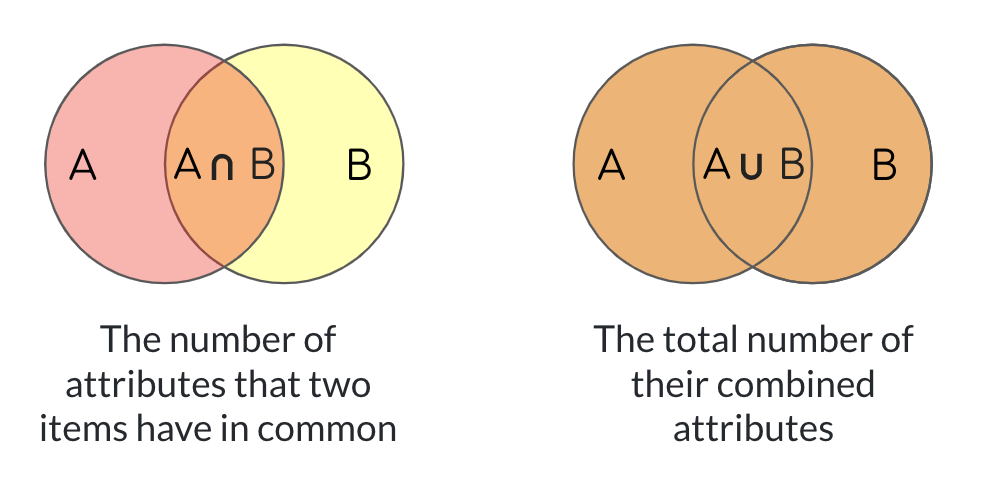 $$J(A,B)=\frac{A\cap B }{A \cup B}$$
$$J(A,B)=\frac{A\cap B }{A \cup B}$$
Building Recommendation Engines in Python
Rob O'Callaghan
Director of Data
Jaccard similarity:
$$J(A,B)=\frac{A\cap B }{A \cup B}$$

