Creating synthetic datasets using scikit-learn
Data Privacy and Anonymization in Python

Rebeca Gonzalez
Data engineer
Generating datasets with Scikit-learn
We can create datasets that sample from probability distributions
Such as the normal distribution
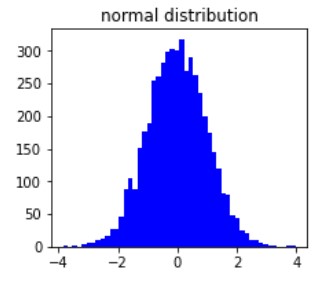
Normal distribution
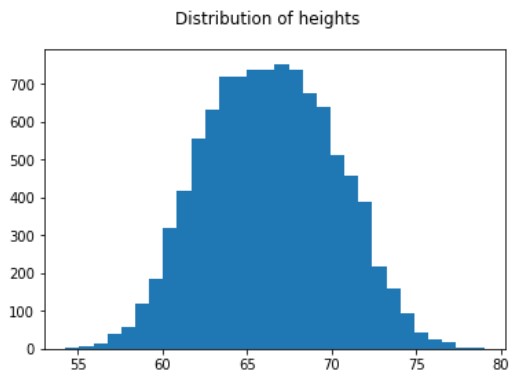
Sample from a normal distribution
# Draw histogram to see the resulting heights distribution
new_measures['Height'].hist(bins=50)
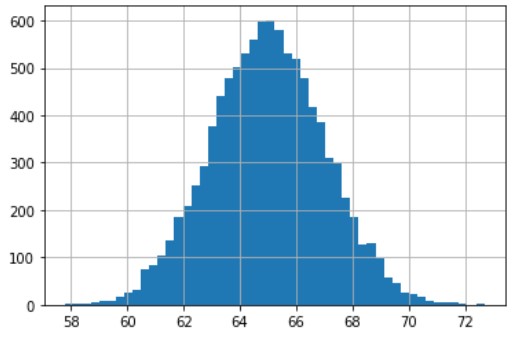
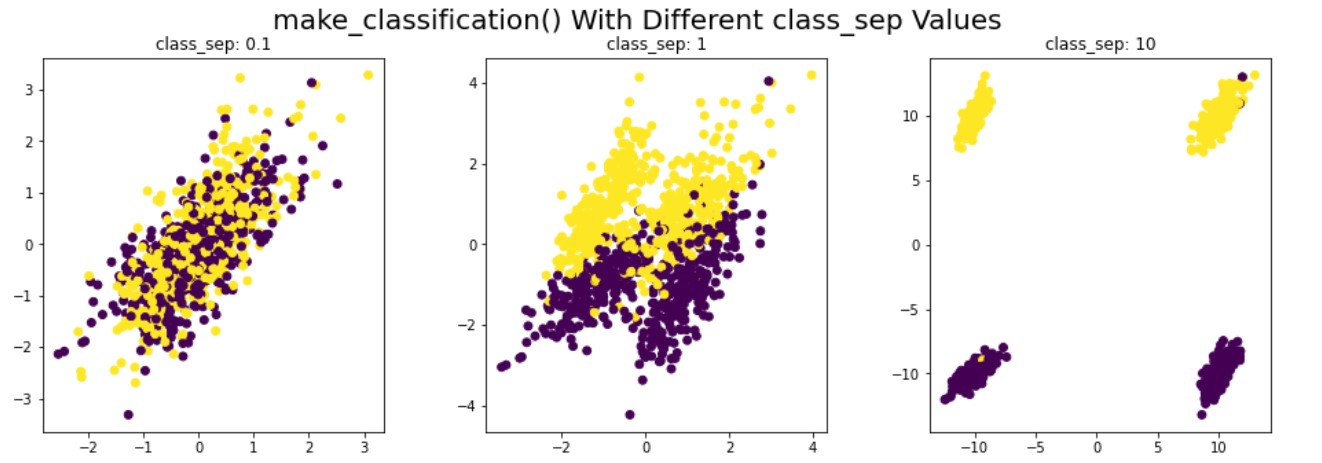
Synthetic data for classification
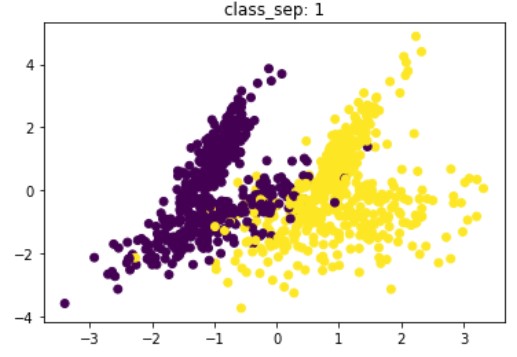
Synthetic data for classification
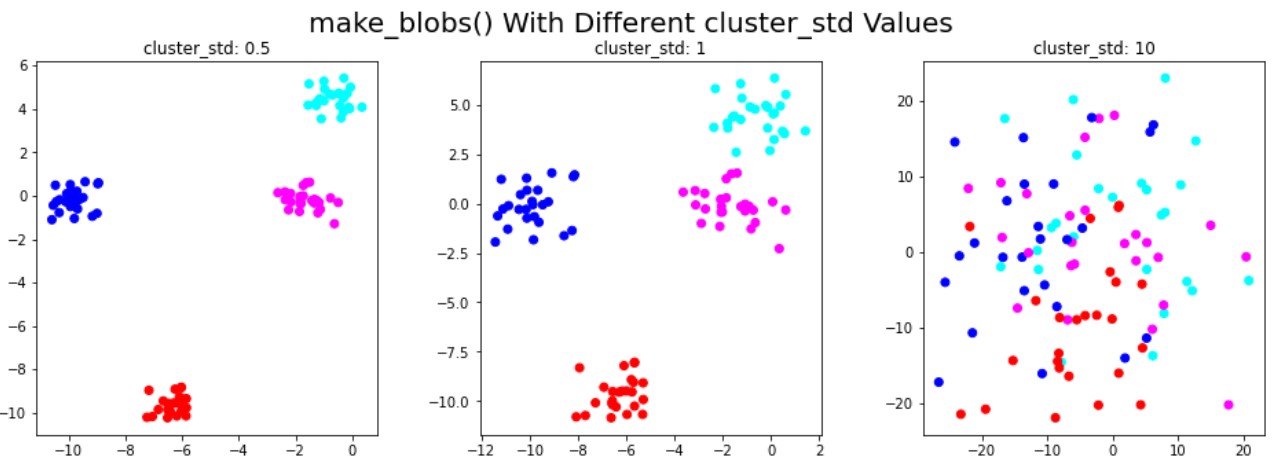
Synthetic data for clustering
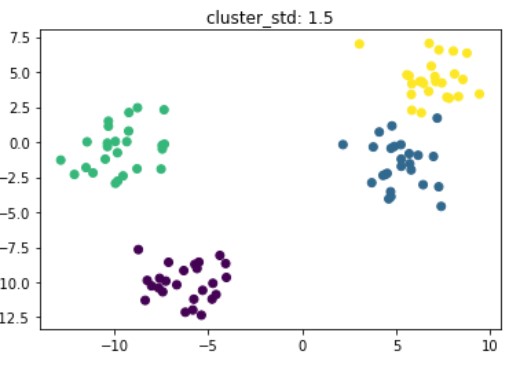
Synthetic data for clustering