Data masking and data generation with Faker
Data Privacy and Anonymization in Python

Rebeca Gonzalez
Data engineer
Quasi-identifiers
Non-sensitive Personally identifiable information can be quasi-identifiers as well.

1 Photo of Angela Merkel from Wikimedia Commons
Quasi-identifiers

Quasi-identifiers and re-identification attacks
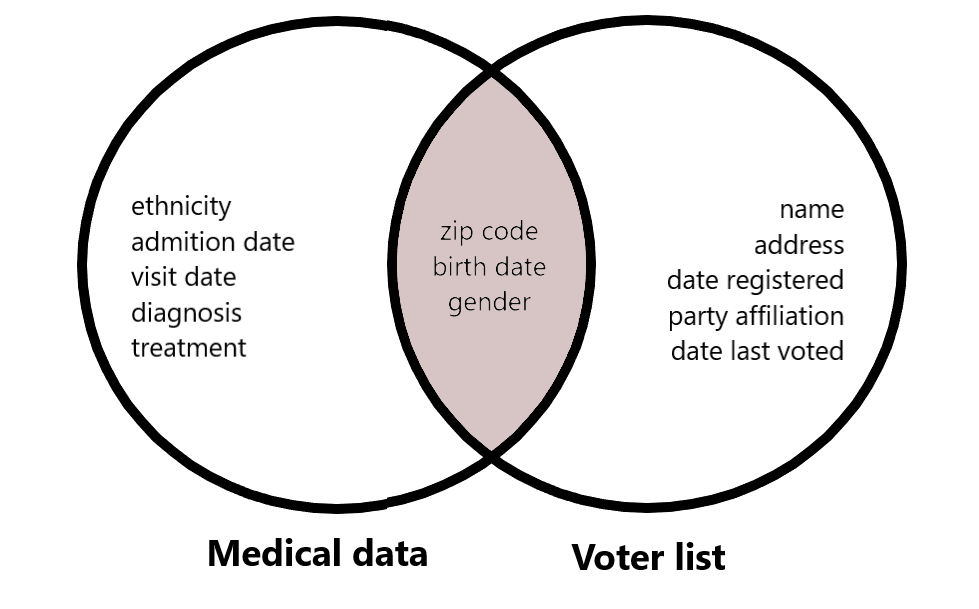
More anonymization techniques
Anonymization techniques for quasi-identifiers to reduce data disclosure risks.
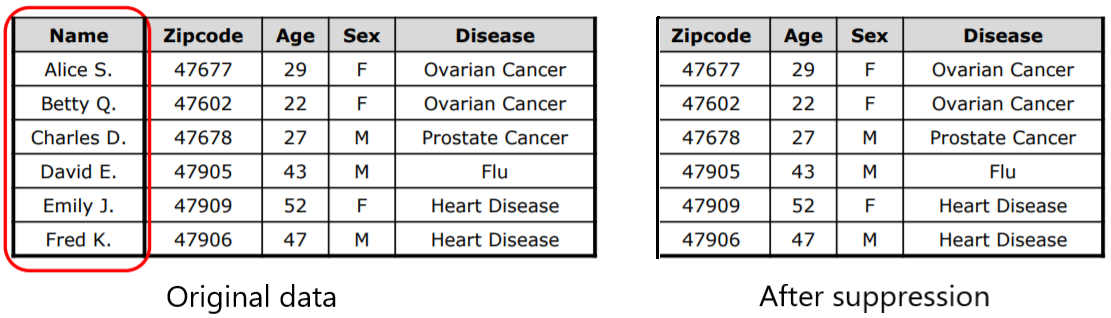
Partial data masking
Generating synthetic data

- Replacing sensitive information with newly generated data, similar to the original.

