PCA for anonymization
Data Privacy and Anonymization in Python

Rebeca Gonzalez
Data engineer
Principal component analysis (PCA)
$$ $$ Dimensionality-reduction method that is often used to reduce the dimensionality of large datasets.
Data masking with PCA
PCA creates new "principal components" from linear transformations of the original features.
In a dataset of beers, PCA will constructs new features. For example:
$$ 2\times AlcoholicVolume - BitternessLevel$$
Data masking with PCA
New projections of the data
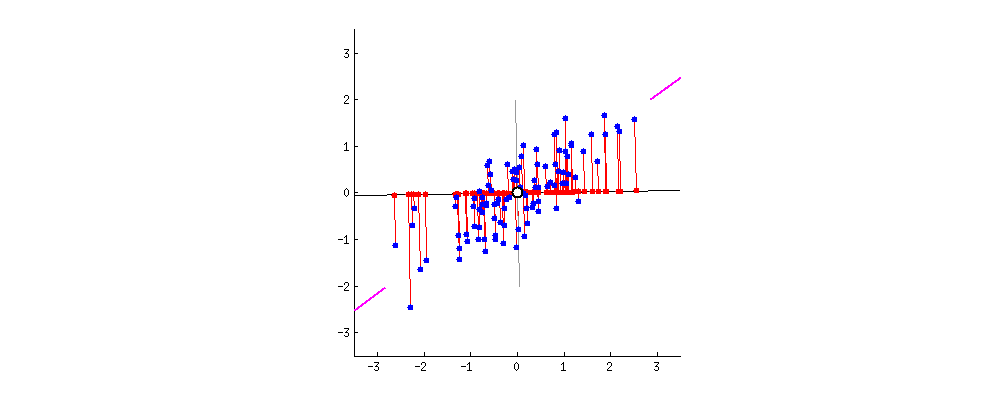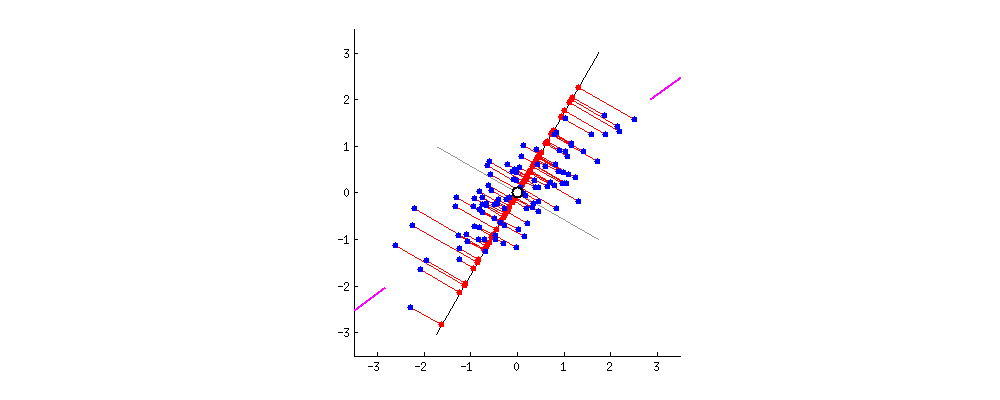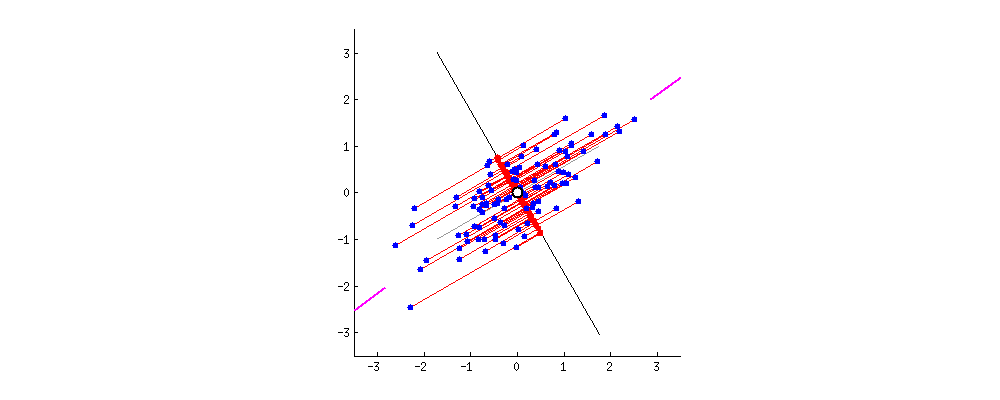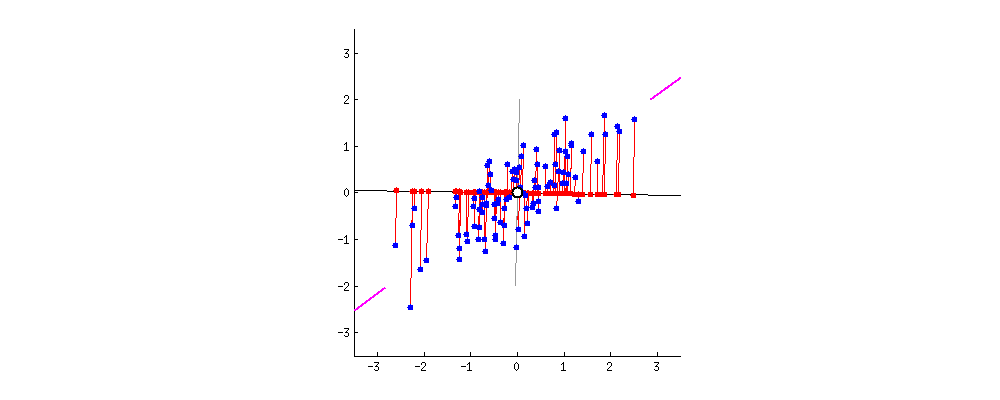
Data masking with PCA
PCA without the dimensionality reduction
$$
- It's only a rotation of the original space in the dataset.
- This means that the distances are preserved.
- An advantage for predictive tasks and algorithms.
Data masking with PCA
- If those resulting values are released without explanation, algorithms could still be trained with these and make accurate predictions.
- Adversaries would not know how to interpret those masked values.
Data masking with PCA
# Explore the dataset
heart_df.head()
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target
0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1
1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1
2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1
3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1
4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1
Data masking with PCA and Scikit-learn
# Obtain the data without the target column x_data = df.drop(['target'], axis = 1)# Target column as array of values y = df.target.values
Data masking with PCA and Scikit-learn
# Import PCA from Scikit-learn from sklearn.decomposition import PCA# Initialize PCA with number of components to be the same as the number of columns pca = PCA(n_components=len(x_data.columns))# Apply PCA to the data x_data_pca = pca.fit_transform(x_data)
Data masking with PCA and Scikit-learn
# See the data
x_data_pca
array([[-1.22673448e+01, 2.87383781e+00, 1.49698788e+01, ...,
7.31102828e-01, -2.90393586e-01, 5.12575925e-01],
[ 2.69013712e+00, -3.98713736e+01, 8.77882303e-01, ...,
4.04206943e-01, -4.25920179e-01, -1.48124511e-01],
[-4.29502141e+01, -2.36368199e+01, 1.75944589e+00, ...,
-9.15397287e-01, 2.17828257e-01, 7.97593843e-02],
...,
Data masking with PCA and Scikit-learn
# Create a DataFrame from the resulting PCA transformed data df_x_data_pca = pd.DataFrame(x_data_pca)# Inspect the shape of the dataset df_x_data_pca.shape
(1213, 13)
Data utility after PCA data masking
- Perform classification with logistics regression and look for accuracy loss by comparing original and resulting data.
$$
- Logistic regression is a classification algorithm used to predict a binary outcome based on a set of independent variables.
Data utility after PCA data masking
Perform classification with logistic regression and look for accuracy loss.
# Split the resulting dataset into training and test data x_train, x_test, y_train, y_test = train_test_split(x_data_pca, y, test_size=0.2)# Create the model lr = LogisticRegression(max_iter=200)# Fit train the model lr.fit(x_train,y_train)# Run the model and perform predictions to obtain accuracy score acc = lr.score(x_test, y_test) * 100 print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Data utility before PCA data masking
Perform classification with logistic regression and see the score with the original data
# Split the resulting dataset into training and test data
x_train, x_test, y_train, y_test = train_test_split(x_data.to_numpy(),y,test_size = 0.2)
# Create the model
lr = LogisticRegression(max_iter=200)
# Fit train the model
lr.fit(x_train,y_train)
# Run the model and perform predictions to obtain accuracy score
acc = lr.score(x_test,y_test) * 100
print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Let's practice!
Data Privacy and Anonymization in Python

