Generalizing data using hierarchies
Data Privacy and Anonymization in Python

Rebeca Gonzalez
Data engineer
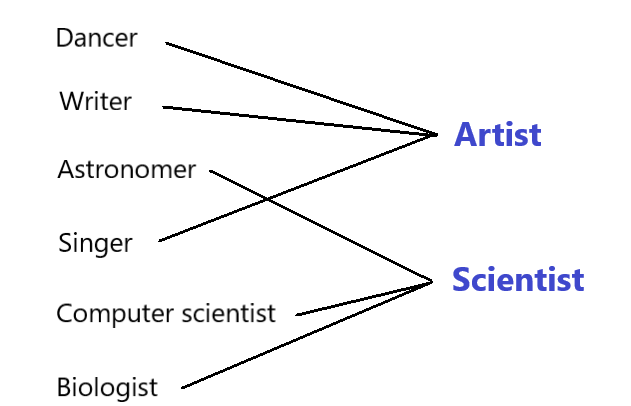
Data generalization
Allows you to replace a data value with a less precise value.
- "Dancer" -> "Artist"
- "Archaeologist" -> "Scientist"
- "Allergist" -> "Doctor"
Data generalization with hierarchies
Refugee status dataset
# Explore dataset
refugee_df.head()
Nationality Gender RefugeeStatus Year
0 russian F 0 2010
1 colombian M 0 2008
2 vietnamese F 1 2008
3 korean M 0 2010
4 ethiopian F 1 2012
Exploring the dataset
# Set k value to 4 k = 4# Calculate how many unique combinations are for nationality and gender df_count = df.groupby(['Nationality', 'Gender']).size().reset_index(name='Count')# Filter the rows that have a count value less than k df_count[df_count['Count'] < k]
Nationality Gender Count
4 colombian F 2
7 cuban M 2
12 liberian F 2
14 mexican F 3
15 mexican M 3
17 russian M 1
20 ukranian F 3
21 ukranian M 1
Data generalization with hierarchies
# See the combination counts
df['Nationality'].value_counts()
belarusian 14
korean 14
ethiopian 10
chinese 10
vietnamese 9
taiwanese 9
colombian 6
cuban 6
russian 6
mexican 6
liberian 6
ukranian 4
Name: Nationality, dtype: int64
Data generalization with hierarchies
# Create hierarchies for origin countries
hierarchies = {'Europe': ['ukranian','russian','belarusian'],
'America':['mexican','colombian','cuban'],
'Asia': ['taiwanese','korean','chinese'],
'Africa': ['ethiopian','liberian']}
Data generalization with hierarchies
# Creating hierachy father for each contry origin_hierarchy = {} for (key, countries) in hierarchies.items(): for country in countries: origin_hierarchy[country] = keyorigin_hierarchy
{'belarusian': 'Europe',
'chinese': 'Asia',
'colombian': 'America',
'cuban': 'America',
'ethiopian': 'Africa',
'korean': 'Asia',
'liberian': 'Africa',
'mexican': 'America',
'russian': 'Europe',
'taiwanese': 'Asia',
'ukranian': 'Europe'}
Data generalization with hierarchies
# Apply origin_hierarchy hierarchy generalization to Nationality df['Nationality_generalized'] = df['Nationality'].map(origin_hierarchy)# Explore resulting dataset df.head()
Nationality Gender RefugeeStatus Year Nationality_generalized
0 korean M 1 2019 Asia
1 ethiopian M 1 2003 Africa
2 cuban M 0 2015 America
3 cuban F 0 2001 America
4 korean M 0 2013 Asia
Data generalization with hierarchies
# Calculate how many unique combinations are for Nationality_generalized and Gender
df_count = df.groupby(['Nationality_generalized', 'Gender']).size()
.reset_index(name='Count')
# Filter the combinations that appear less than k times
df_count[df_count['Count'] < k]
Nationality_generalized Gender Count
More on K-anonymity
Types:
- Constraints approach
- Mondrian Multidimensional approach
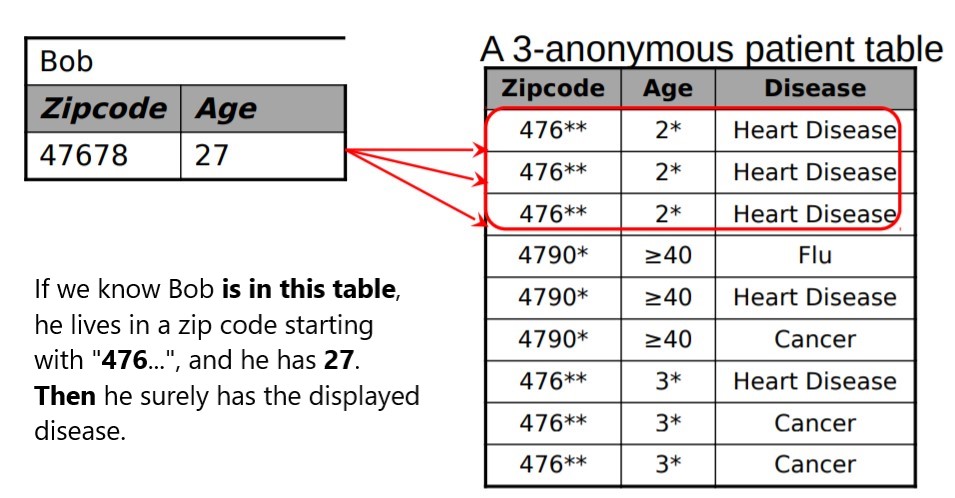
How safe is K-anonymity?
Let's practice!
Data Privacy and Anonymization in Python

