Introduction to K-anonymity
Data Privacy and Anonymization in Python

Rebeca Gonzalez
Data engineer
Why is k-anonymity important?

Why is it important?
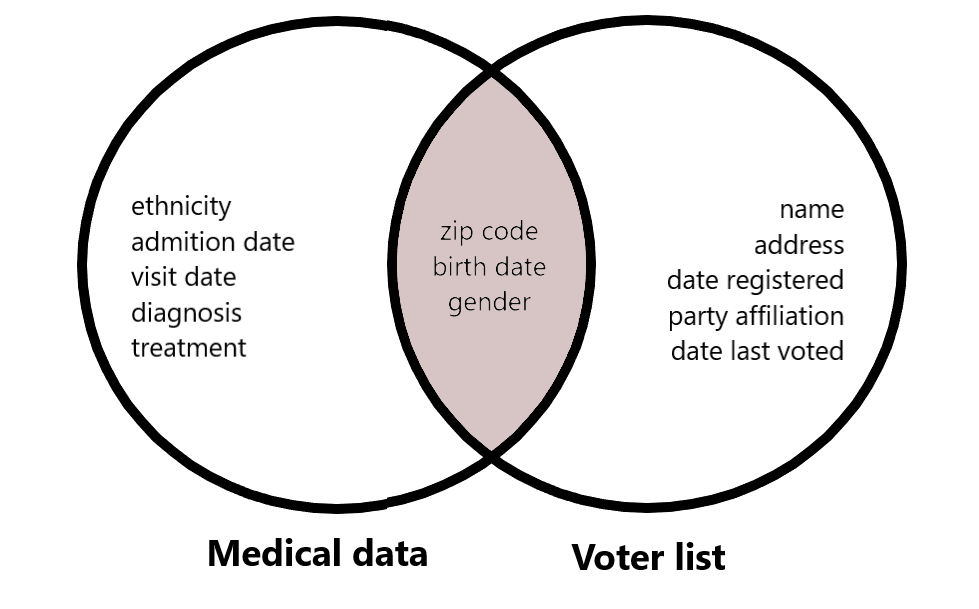
Definition of k-anonymity

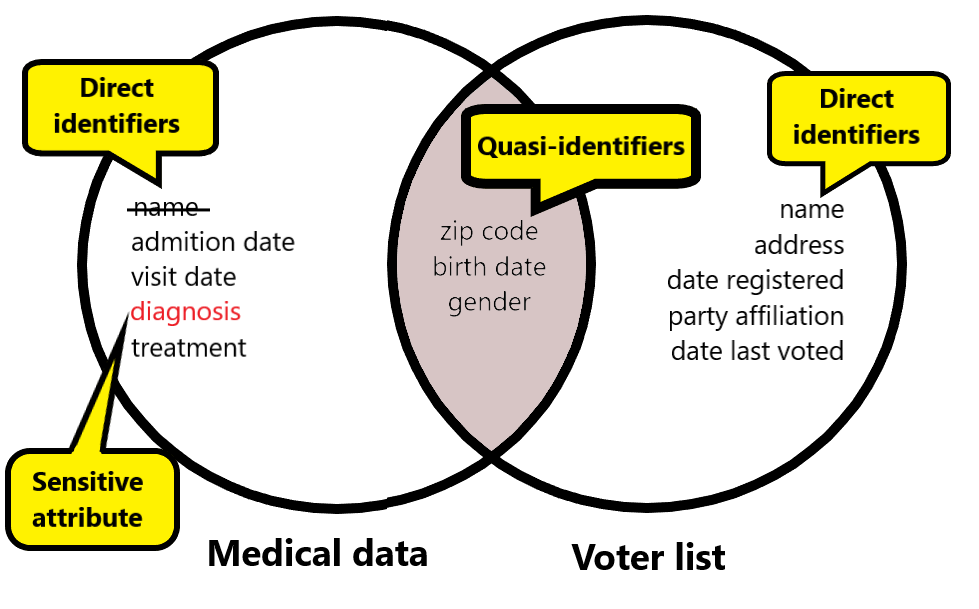
K-anonymity: Terminology
Data Privacy and Anonymization in Python
Rebeca Gonzalez
Data engineer

