Anonymizing with data generalization
Data Privacy and Anonymization in Python

Rebeca Gonzalez
Data engineer
Data aggregation
Medical dataset
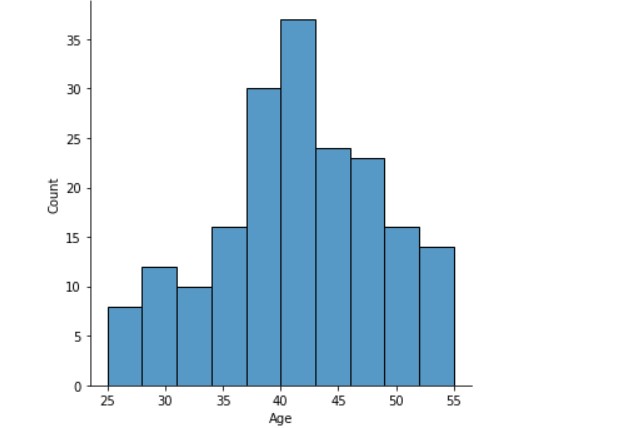
# Explore the histogram of the age variable
df_medical['age'].hist(bins=15)
Top and bottom coding
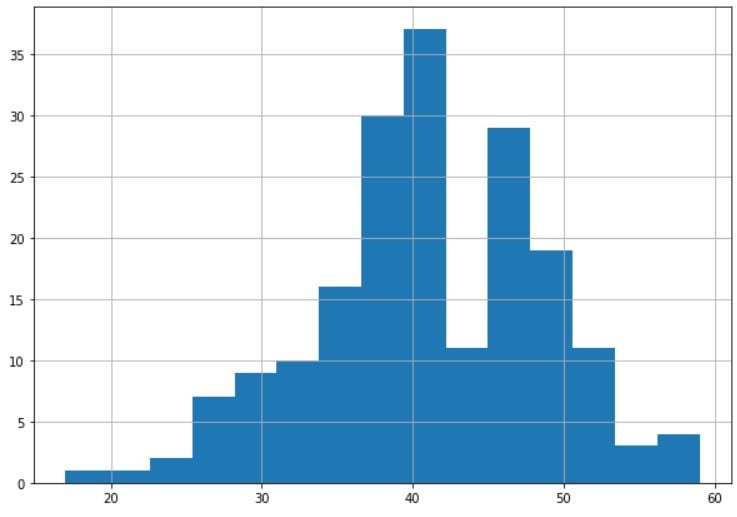
# Explore the histogram of the age variable
df_medical['age'].hist(bins=15)
Bottom coding
# Explore the histogram of the age variable
df_medical['age'].hist(bins=15)
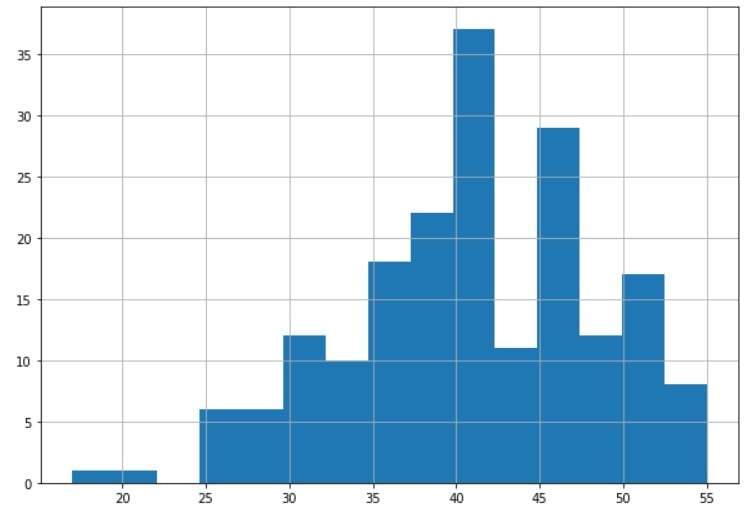
Bottom code
# Bottom code the age to 25 df_medical.loc[df['age'] < 25, 'age'] = 25# Explore the histogram of the age variable df_medical['age'].hist(bins=15)