Building delayed pipelines
Parallel Programming with Dask in Python

James Fulton
Climate Informatics Researcher
Chunks of data


Spotify songs dataset
files = [
'2005_tracks.csv',
'2006_tracks.csv',
'2007_tracks.csv',
'2008_tracks.csv',
'2009_tracks.csv',
'2010_tracks.csv',
...
'2020_tracks.csv',
]
Spotify songs dataset
name duration_ms release_date ...
0 Aldrig (feat. Carmon) 247869 2019-01-01 ...
2 2019 - The Year to Build 288105 2019-01-01 ...
3 Na zawsze 186812 2019-01-01 ...
4 Humo en la Trampa 258354 2019-01-01 ...
5 Au Au 176000 2019-01-01 ...
... ... ... ... ...
Analyzing the data
import pandas as pd maximums = [] for file in files: # Load each file df = pd.read_csv(file)# Find maximum track length in each file max_length = df['duration_ms'].max()# Store this maximum maximums.append(max_length)# Find the maximum of all the maximum lengths absolute_maximum = max(maximums)
Analyzing the data
import pandas as pd
maximums = []
for file in files:
# Load each file
df = delayed(pd.read_csv)(file) # <------- delay loading
# Find maximum track length in each file
max_length = df['duration_ms'].max()
# Store this maximum
maximums.append(max_length)
# Find the maximum of all the maximum lengths
absolute_maximum = max(maximums)
Analyzing the data
import pandas as pd
maximums = []
for file in files:
# Load each file
df = delayed(pd.read_csv)(file) # <------- delay loading
# Find maximum track length in each file
max_length = df['duration_ms'].max()
# Store this maximum
maximums.append(max_length)
# Find the maximum of all the maximum lengths
absolute_maximum = delayed(max)(maximums) # <------- delay max() function
Using methods of a delayed object
import pandas as pd
maximums = []
for file in files:
df = delayed(pd.read_csv)(file)
# Use the .max() method
max_length = df['duration_ms'].max()
maximums.append(max_length)
absolute_maximum = delayed(max)(maximums)
print(max_length)
Delayed('max-0602855d-3ee6-4c43-a4d2-...')
- Delayed object methods and properties return new delayed objects
print(df.shape)
print(df.shape.compute())
Delayed('getattr-bc1e8838ab...')
(11907, 12)
Using methods of a delayed object
import pandas as pd
maximums = []
for file in files:
df = delayed(pd.read_csv)(file)
# Use a method which doesn't exist
max_length = df['duration_ms'].fake()
maximums.append(max_length)
absolute_maximum = delayed(max)(maximums)
print(max_length)
Delayed('max-6c026036-5daf-4b2-...')
- Methods aren't run until after
.compute()is used
print(max_length.compute())
...
AttributeError: 'Series' object has no
attribute 'fake'
Using methods of a delayed object
import pandas as pd
maximums = []
for file in files:
df = delayed(pd.read_csv)(file)
max_length = df['duration_ms'].max()
# Add delayed object to list
maximums.append(max_length)
# Run delayed max on delayed objects list
absolute_maximum = delayed(max)(maximums)
maximums is a list of delayed objects
print(maximums)
[Delayed('max-80b...'),
Delayed('max-fa15d...',
...]
Computing lists of delayed objects
import pandas as pd
maximums = []
for file in files:
df = delayed(pd.read_csv)(file)
max_length = df['duration_ms'].max()
# Add dalayed object to list
maximums.append(max_length)
# Compute all the maximums
all_maximums = dask.compute(maximums)
print(all_maximums)
([2539418, 4368000, ...
... 4511716, 4864333],)
Computing lists of delayed objects
import pandas as pd
maximums = []
for file in files:
df = delayed(pd.read_csv)(file)
max_length = df['duration_ms'].max()
maximums.append(max_length)
# Compute all the maximums
all_maximums = dask.compute(maximums)[0]
print(all_maximums)
[2539418, 4368000, ...
... 4511716, 4864333]
To delay or not to delay
def get_max_track(df):
return df['duration_ms'].max()
for file in files:
df = delayed(pd.read_csv)(file)
# Use function to find max
max_length = get_max_track(df)
maximums.append(max_length)
absolute_maximum = delayed(max)(maximums)
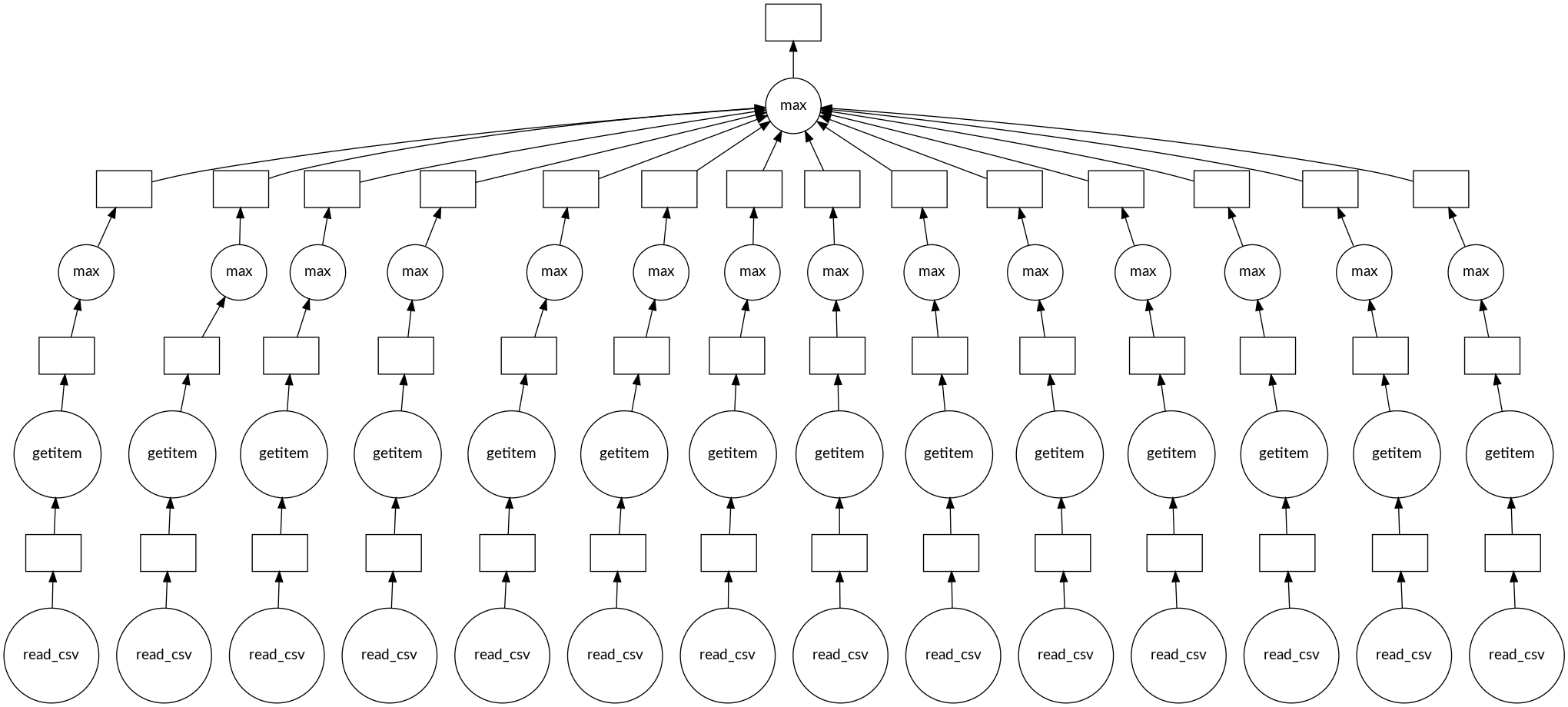
Deeper task graph
absolute_maximum.visualize()
Let's practice!
Parallel Programming with Dask in Python

