Multidimensional arrays
Parallel Programming with Dask in Python

James Fulton
Climate Informatics Researcher
HDF5
![]()
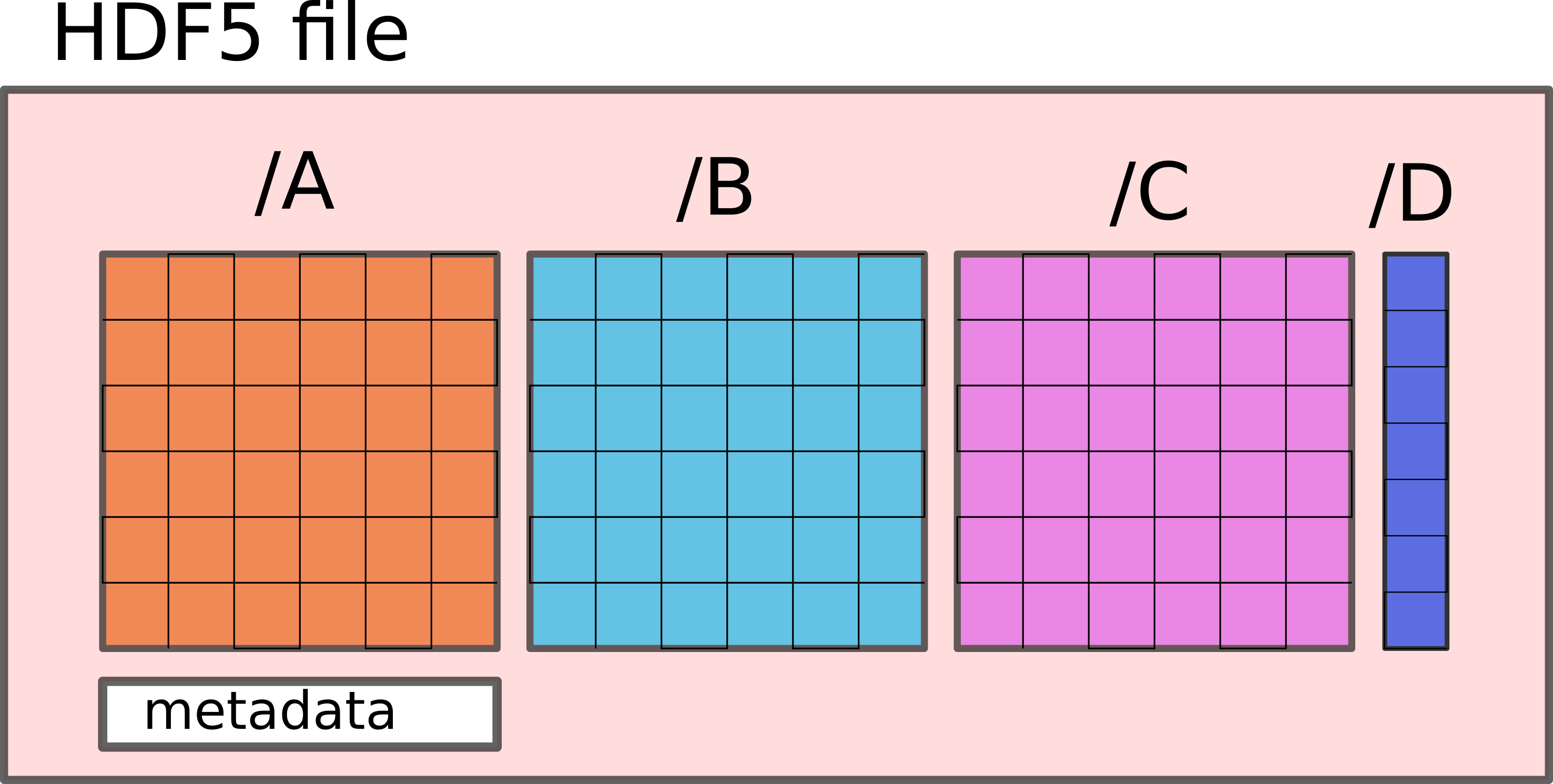
- Hierarchical Data Format
- Stored in hierarchical format - like (sub)directories
What does an HDF5 file look like?

What does an HDF5 file look like?