Dask DataFrames
Parallel Programming with Dask in Python

James Fulton
Climate Informatics Researcher
pandas DataFrames vs. Dask DataFrames
import pandas as pd# Read a single csv file pandas_df = pd.read_csv( "dataset/chunk1.csv" )
This reads a single CSV file immediately.
import dask.dataframe as dd# Lazily read all csv files dask_df = dd.read_csv( "dataset/*.csv" )
This reads all the CSV files in the dataset folder lazily.
Dask DataFrames
print(dask_df)
Dask DataFrame Structure:
ID col1 col2 col3 col4 ...
npartitions=3
int64 object object int64 float64 ...
... ... ... ... ... ...
... ... ... ... ... ...
... ... ... ... ... ...
Dask Name: getitem, 3 tasks
Dask DataFrame task graph
dask.visualize(dask_df)
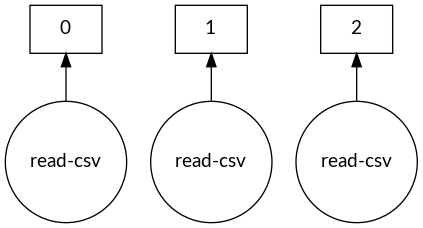
Controlling the size of blocks
# Set the maximum memory of a chunk dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")print(dask_df)
Dask DataFrame Structure:
ID col1 col2 col3 col4 ...
npartitions=7
int64 object object int64 float64 ...
... ... ... ... ... ...
... ... ... ... ... ...
... ... ... ... ... ...
Dask Name: getitem, 7 tasks
Explaining partitions
# Set the maximum memory of a chunk
dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")
Why 7 partitions?
size file
9M dataset/chunk1.csv
18M dataset/chunk2.csv
32M dataset/chunk3.csv
Explaining partitions
# Set the maximum memory of a chunk
dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")
Why 7 partitions?
size file
9M dataset/chunk1.csv # becomes 1 partition
18M dataset/chunk2.csv # becomes 2 partitions
32M dataset/chunk3.csv # becomes 4 partitions
Analysis with Dask DataFames
- Select column
col1 = dask_df['col1'] - Assigning columns
dask_df['double_col1'] = 2 * col1 - Mathematical operations, e.g.
dask_df.std() dask_df.min()
- Groupby
dask_df.groupby(col1).mean() - Even fuctions you used earlier
dask_df.nlargest(n=3, columns='col1')
Datetimes and other pandas functionality
import pandas as pd # Converting string to datetime format pd.to_datetime(pandas_df['start_date'])# Accessing datetime attributes pandas_df['start_date'].dt.year pandas_df['start_date'].dt.day pandas_df['start_date'].dt.hour pandas_df['start_date'].dt.minute
import dask.dataframe as dd # Converting string to datetime format dd.to_datetime(dask_df['start_date'])# Accessing datetime attributes dask_df['start_date'].dt.year dask_df['start_date'].dt.day dask_df['start_date'].dt.hour dask_df['start_date'].dt.minute
Making results non-lazy
# Show 5 rows
print(dask_df.head())
ID double_col1 col1 col2 col3 ...
0 543795 20 10 436 0 ...
1 874535 24 12 268 0 ...
2 781326 62 31 211 0 ...
3 112457 18 9 898 1 ...
4 103256 142 71 663 0 ...
# Convert lazy Dask DataFrame to in-memory pandas DataFrame
results_df = df.compute()
Sending answer straight to file
# 7 partitions (chunks) so 7 output files
dask_df.to_csv('answer/part-*.csv')
part-0.csv
part-1.csv
part-2.csv
part-3.csv
part-4.csv
part-5.csv
part-6.csv
Faster file formats - Parquet
# Read from parquet
dask_df = dd.read_parquet('dataset_parquet')
# Save to parquet
dask_df.to_parquet('answer_parquet')
- Parquet format is multiple times faster to read data from than CSV
- Can be faster to write to
Let's practice!
Parallel Programming with Dask in Python

