Sampling in Python
James Chapman
Curriculum Manager, DataCamp
len(coffee_ratings.sample(n=300))
300
len(coffee_ratings.sample(frac=0.25))
334
coffee_ratings['total_cup_points'].mean()
82.15120328849028
coffee_ratings.sample(n=10)['total_cup_points'].mean()
83.027
coffee_ratings.sample(n=100)['total_cup_points'].mean()
82.4897
coffee_ratings.sample(n=1000)['total_cup_points'].mean()
82.1186
Population parameter:
population_mean = coffee_ratings['total_cup_points'].mean()
Point estimate:
sample_mean = coffee_ratings.sample(n=sample_size)['total_cup_points'].mean()
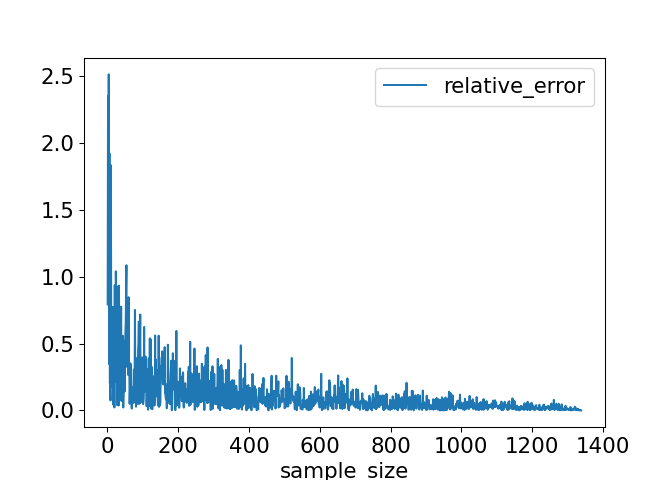
Relative error as a percentage:
rel_error_pct = 100 * abs(population_mean-sample_mean) / population_mean
import matplotlib.pyplot as plt errors.plot(x="sample_size", y="relative_error", kind="line") plt.show()
Properties: