Measuring model performance
Supervised Learning with scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Measuring model performance
In classification, accuracy is a commonly used metric
Accuracy:
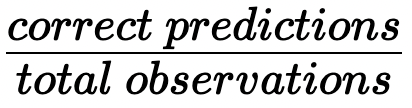
Computing accuracy
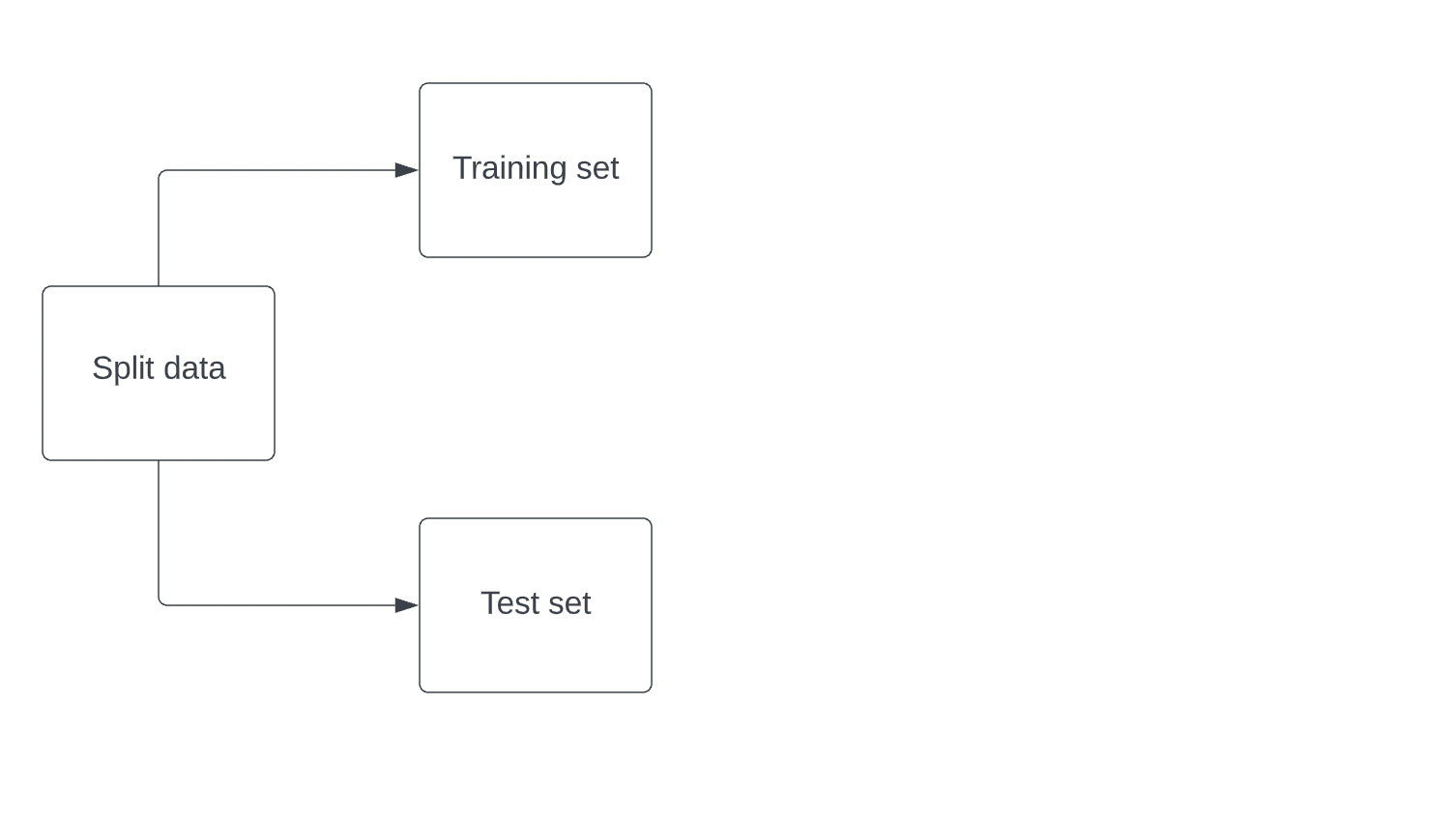
Computing accuracy
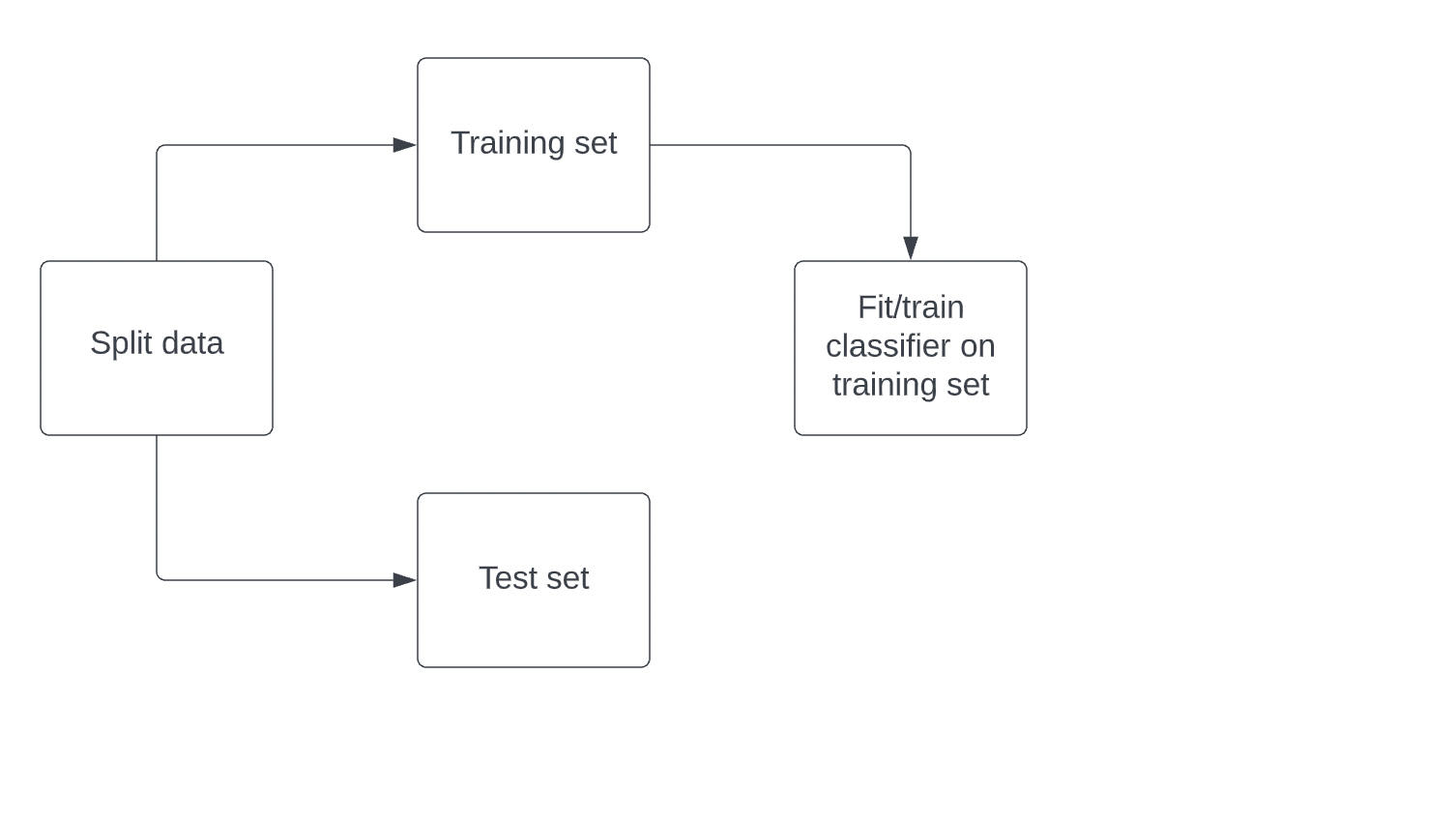
Computing accuracy
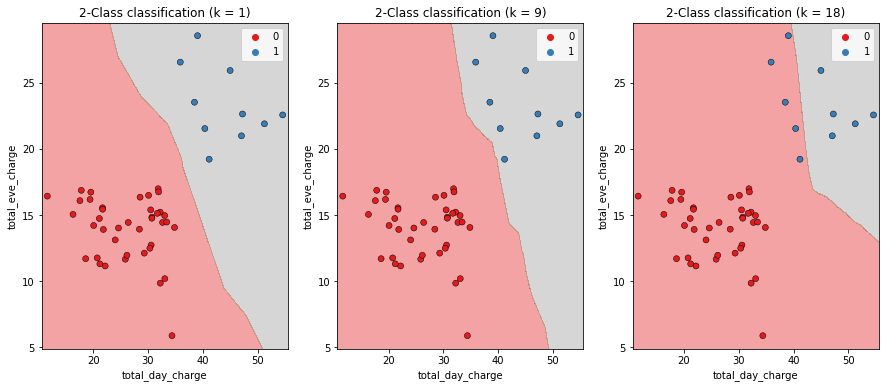
Model complexity
Larger k = less complex model = can cause underfitting
Smaller k = more complex model = can lead to overfitting
Model complexity curve
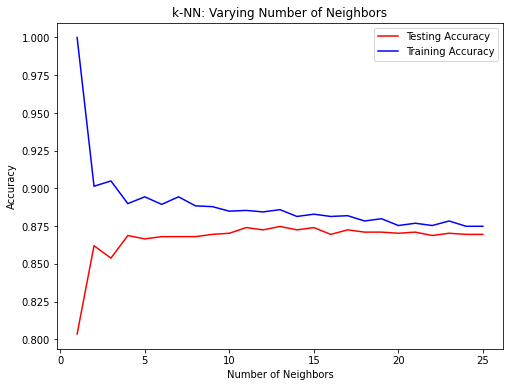
Model complexity curve
![]()

