Selecting based on missing values
Dimensionality Reduction in R

Matt Pickard
Owner, Pickard Predictives, LLC
Calculate missing values ratio
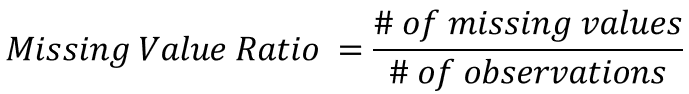
n <- nrow(credit_df)missing_vals_df <- credit_df %>% summarize(across(everything(), ~ sum(is.na(.)))) %>%pivot_longer(everything(), names_to = "feature", values_to = "num_missing_values") %>%mutate(missing_val_ratio = num_missing_values / n)
Rules of thumb for missing value ratio threshold


