Dimensionality Reduction in R
Matt Pickard
Owner, Pickard Predictives, LLC
library(tidymodels) rf <- rand_forest(mode = "classification", trees = 200) %>% set_engine("ranger", importance = "impurity") rf_fit <- rf %>% fit(credit_score ~ ., data = train) predict_df <- test %>% bind_cols(predict = predict(rf_fit, test))
library(tidymodels)
rf <- rand_forest(mode = "classification", trees = 200) %>% set_engine("ranger", importance = "impurity")
rf_fit <- rf %>% fit(credit_score ~ ., data = train)
predict_df <- test %>% bind_cols(predict = predict(rf_fit, test))
f_meas(predict_df, credit_score, .pred_class)
0.6895
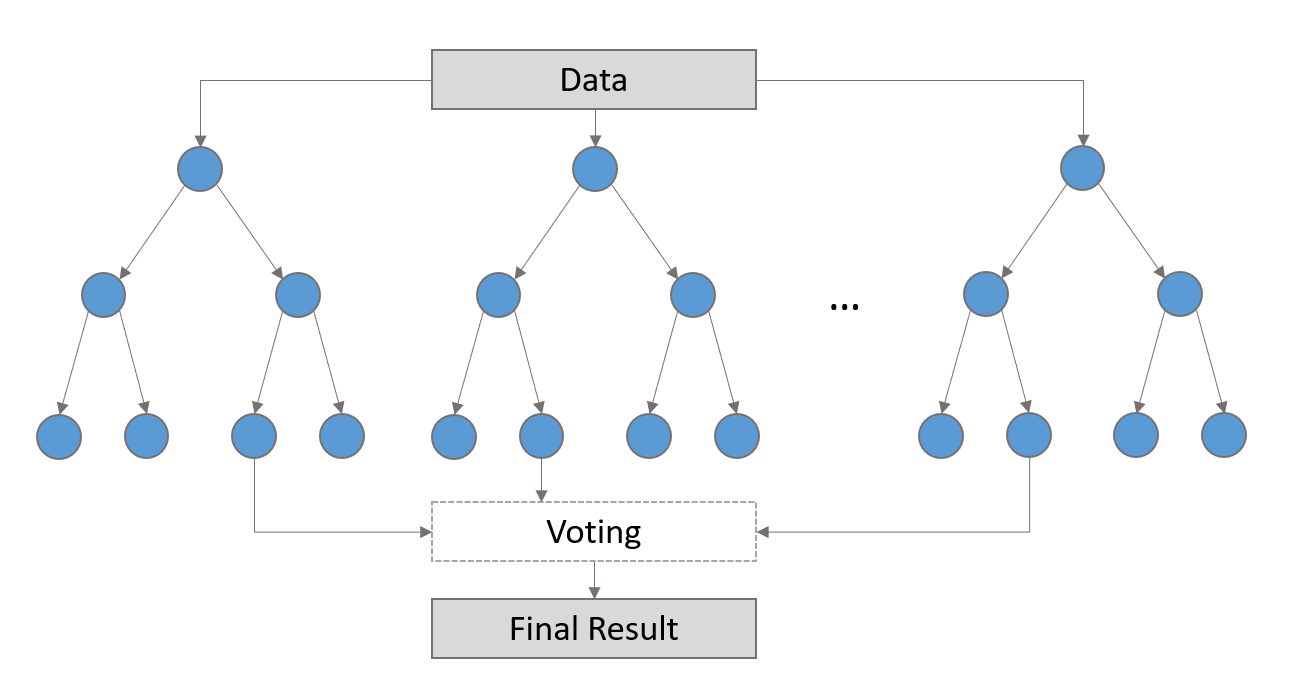
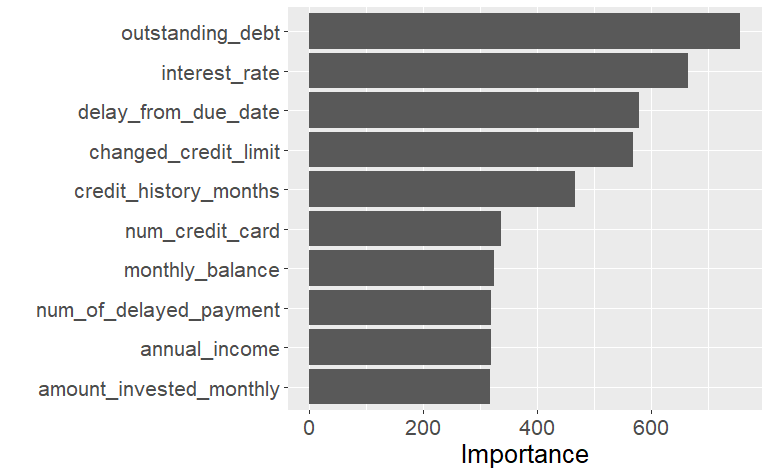
library(vip) rf_fit %>% vip()
library(vip)
rf_fit %>% vip()
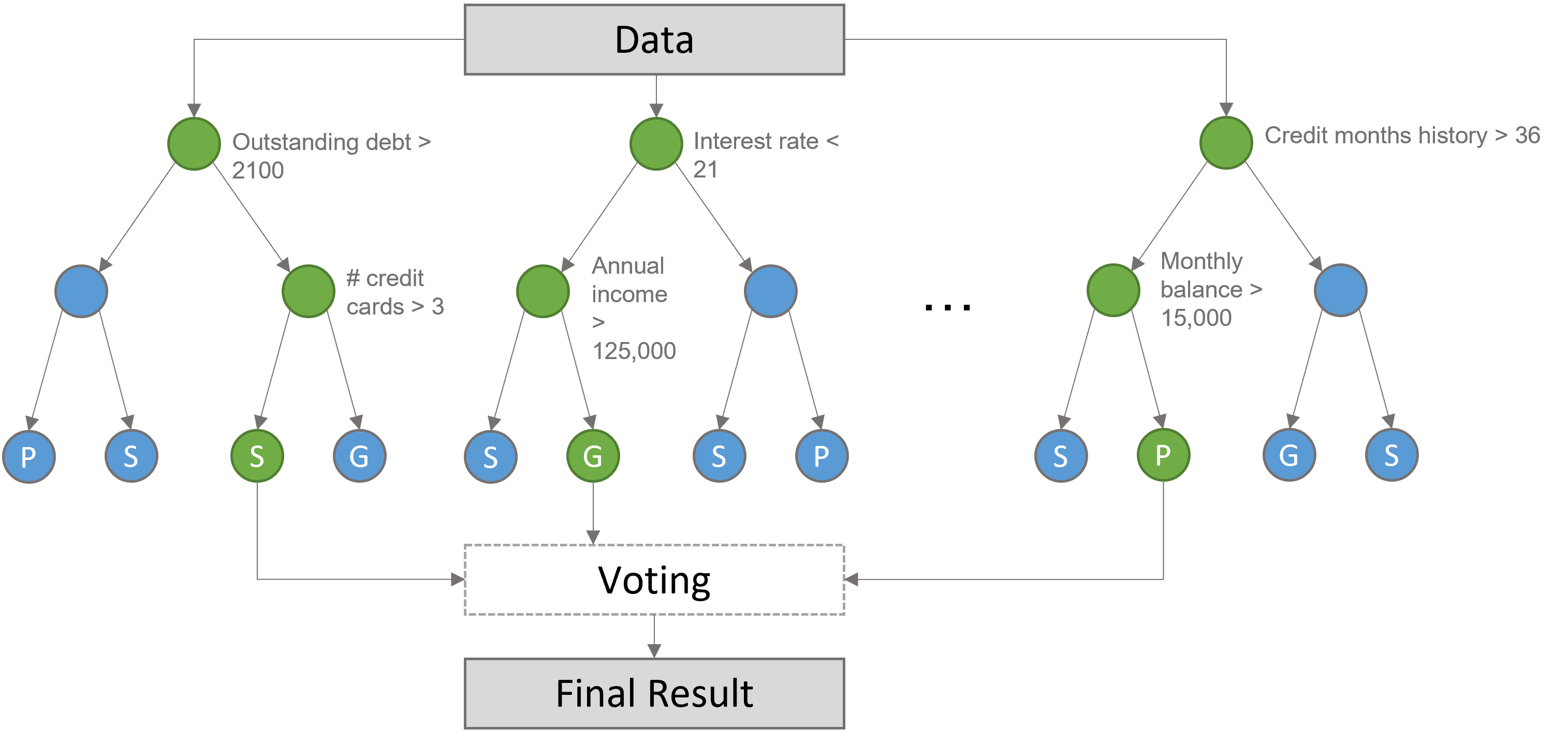
top_features <- rf_fit %>% vi(rank = TRUE) %>% filter(Importance <= 10) %>% pull(Variable) top_features
top_features <- rf_fit %>% vi(rank = TRUE) %>% filter(Importance <= 10) %>% pull(Variable)
top_features
[1] "outstanding_debt" "interest_rate" [3] "delay_from_due_date" "changed_credit_limit" [5] "credit_history_months" "num_credit_card" [7] "monthly_balance" "num_of_delayed_payment" [9] "annual_income" "amount_invested_monthly"
train_reduced <- train[top_features] test_reduced <- test[top_features]
rf_fit <- rf %>% fit(credit_score ~ ., data = train_reduced) predict_reduced_df <- test_reduced %>% bind_cols(predict = predict(rf_fit, test_reduced)) f_meas(predict_reduced_df, credit_score, .pred_class)
rf_fit <- rf %>% fit(credit_score ~ ., data = train_reduced)
predict_reduced_df <- test_reduced %>% bind_cols(predict = predict(rf_fit, test_reduced))
f_meas(predict_reduced_df, credit_score, .pred_class)
0.6738
F-score of the unreduced model: