Model Building and Evaluation with tidymodels
Dimensionality Reduction in R

Matt Pickard
Owner, Pickard Predictives, LLC
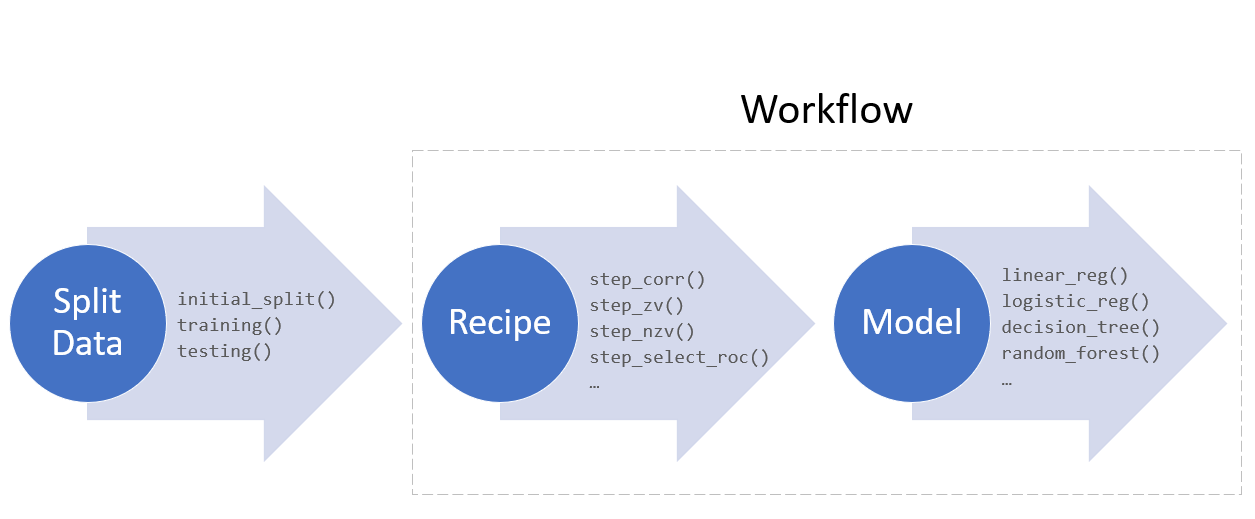
Model fitting process

Model fitting process

Model fitting process

Model fitting process

Model fitting with tidymodels
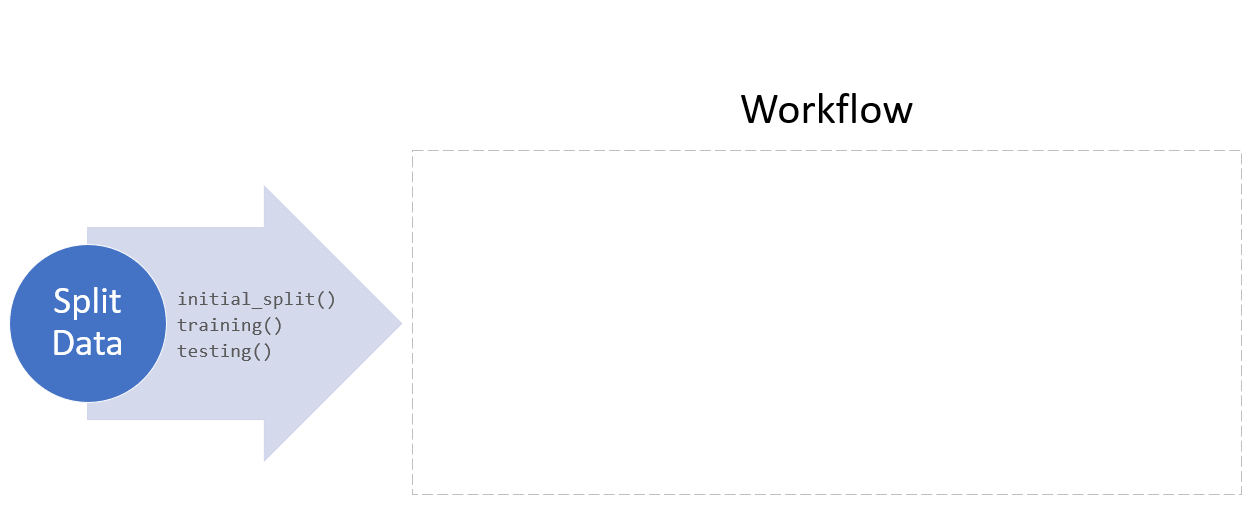
Model fitting with tidymodels
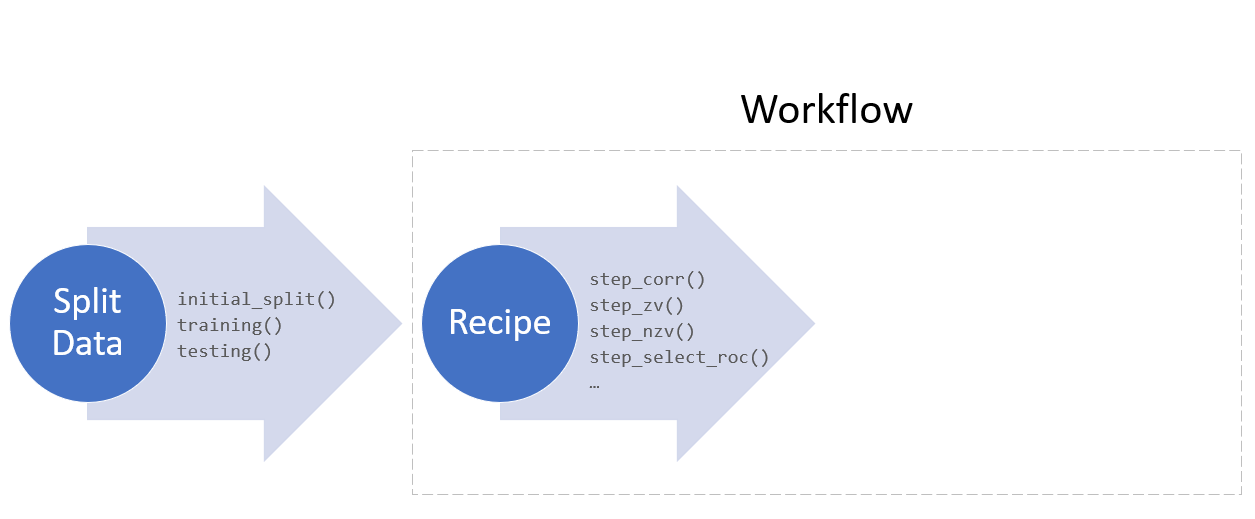
Model fitting with tidymodels