Feature selection vs. feature extraction
Dimensionality Reduction in R

Matt Pickard
Owner, Pickard Predictives, LLC
Approaches to dimensionality reduction

1 Image Source: Daderot, CC0, via Wikimedia Commons
Feature selection

Feature selection
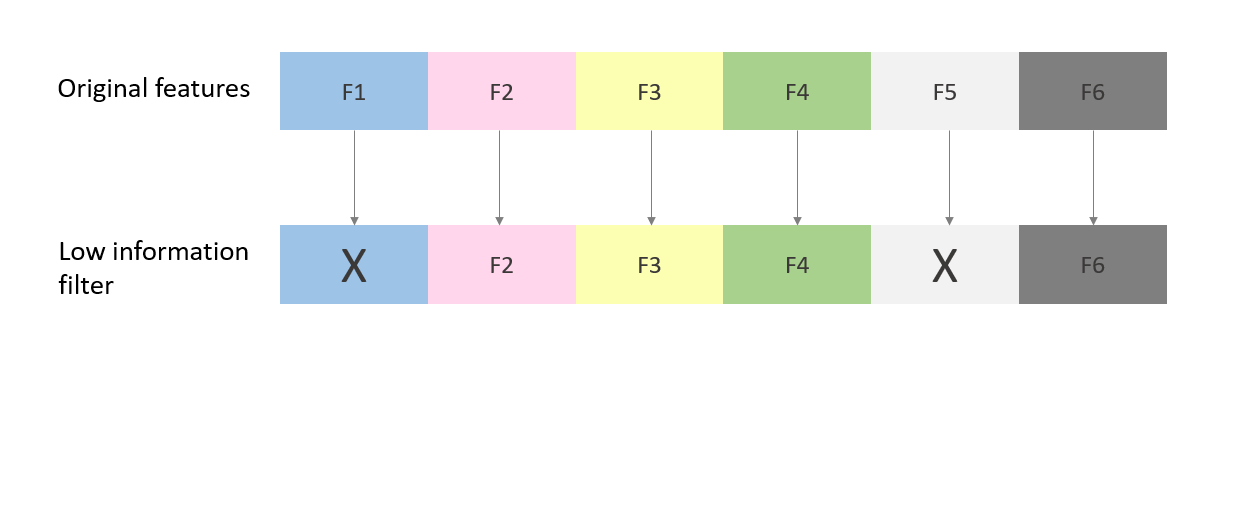
Feature selection
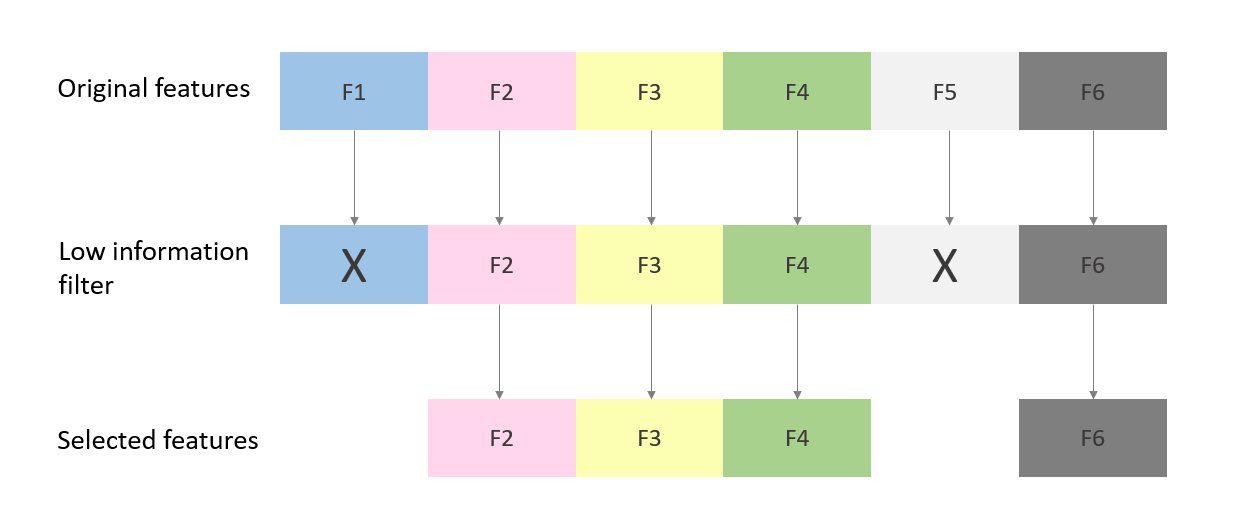
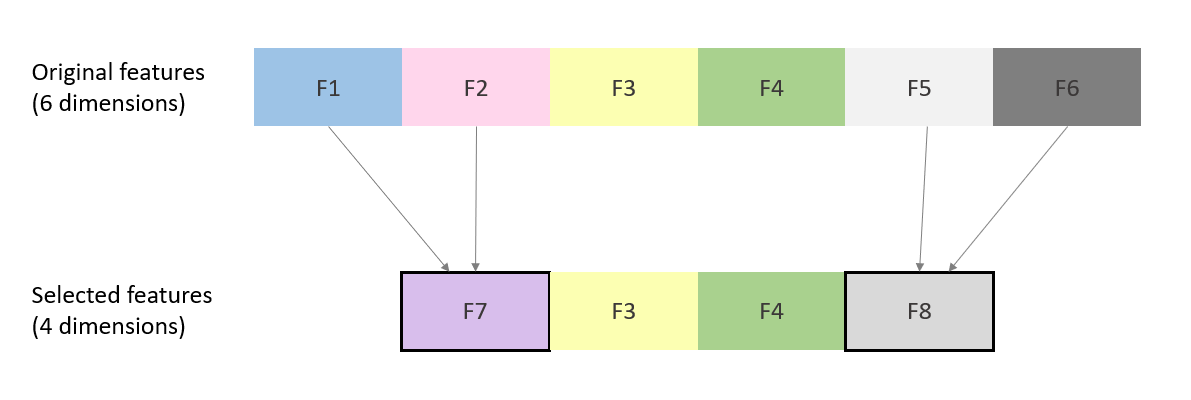
Feature extraction
Feature extraction
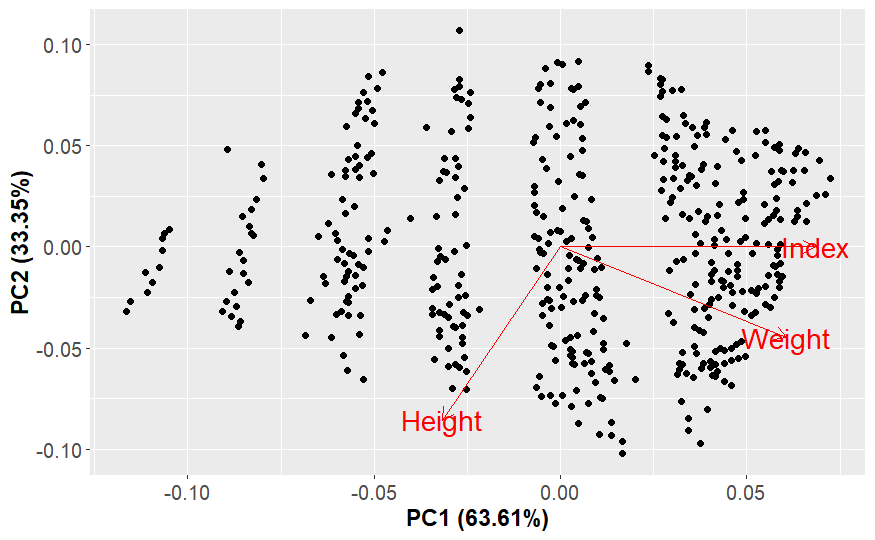
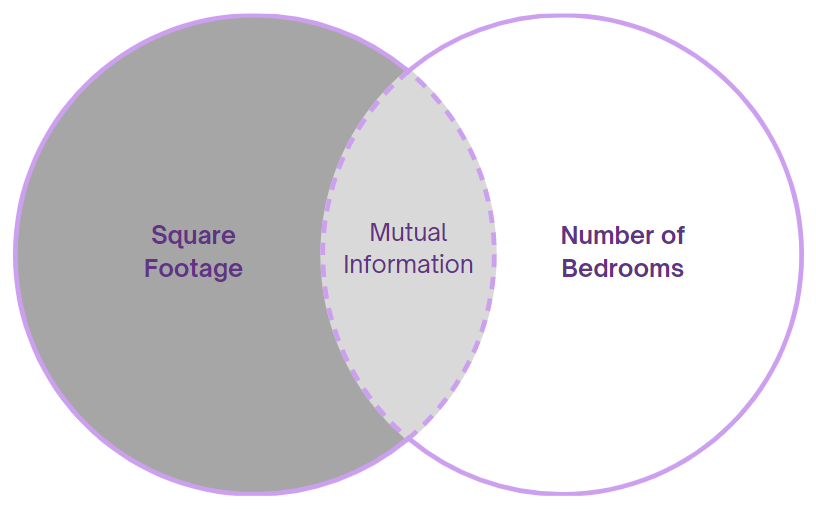
Feature extraction and mutual information
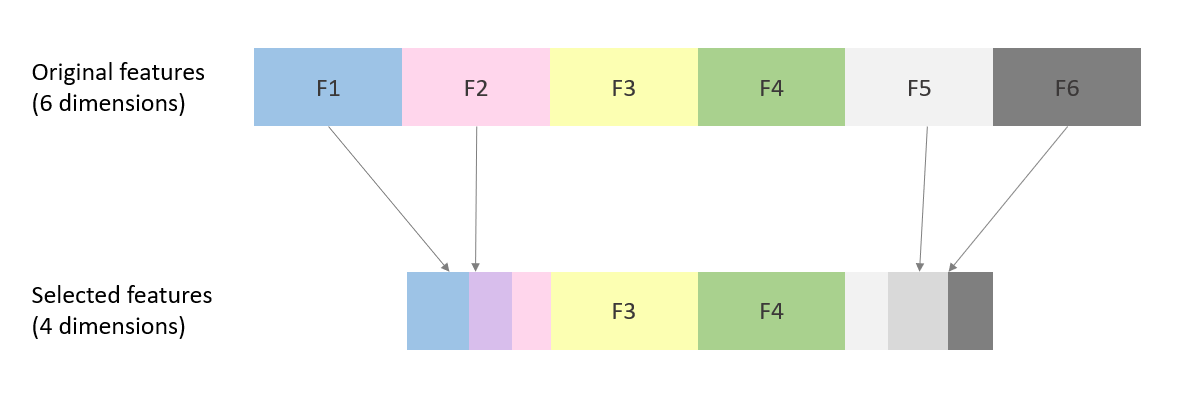
Feature extraction: Combining mutual exclusive info
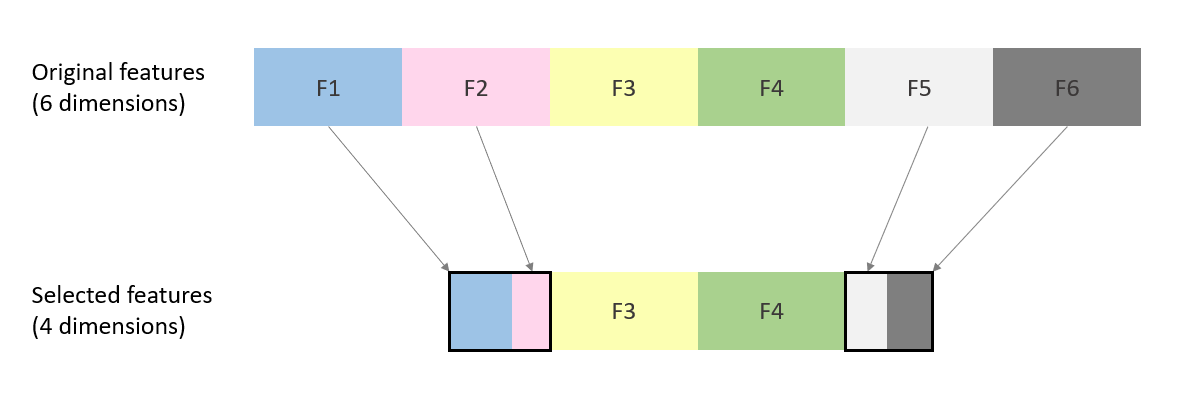
Feature extraction: Combining mutual exclusive info
Advantages and disadvantages of feature extraction