Selecting based on variance
Dimensionality Reduction in R

Matt Pickard
Owner, Pickard Predictives, LLC
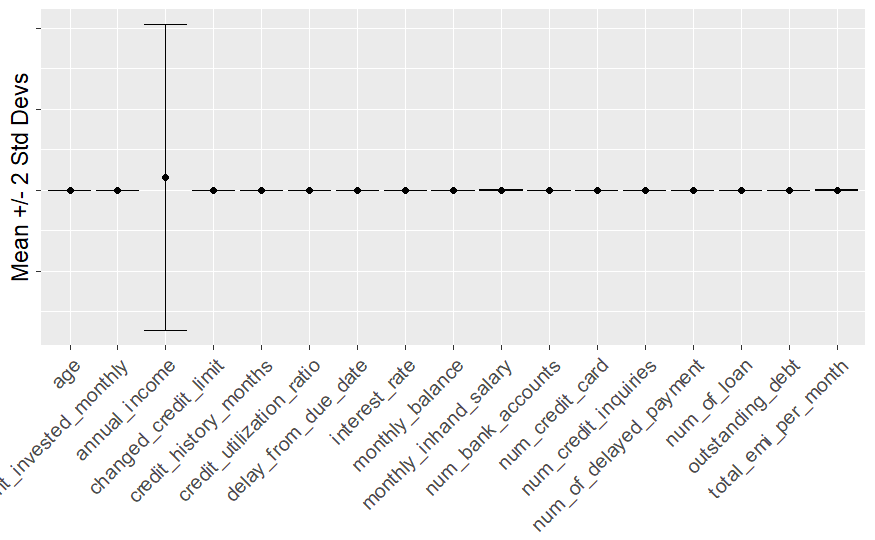
Variance of unscaled data
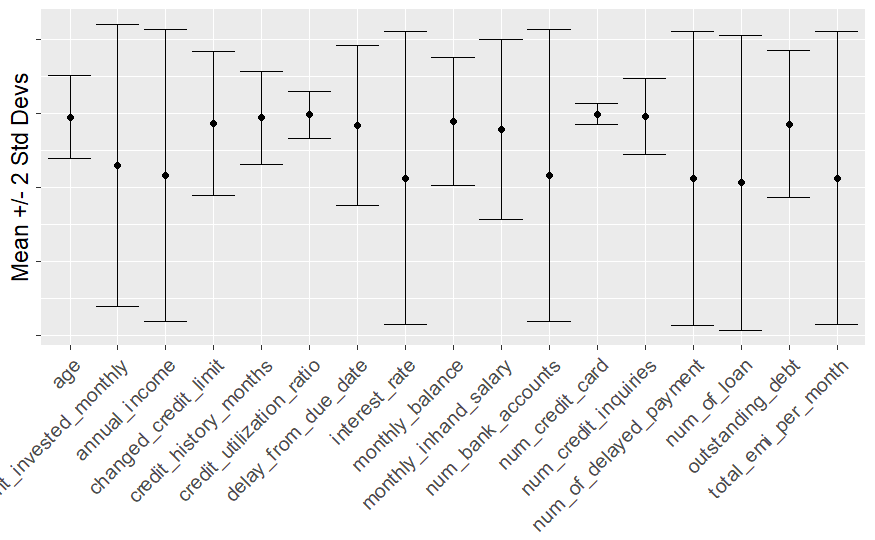
Variance of scaled data
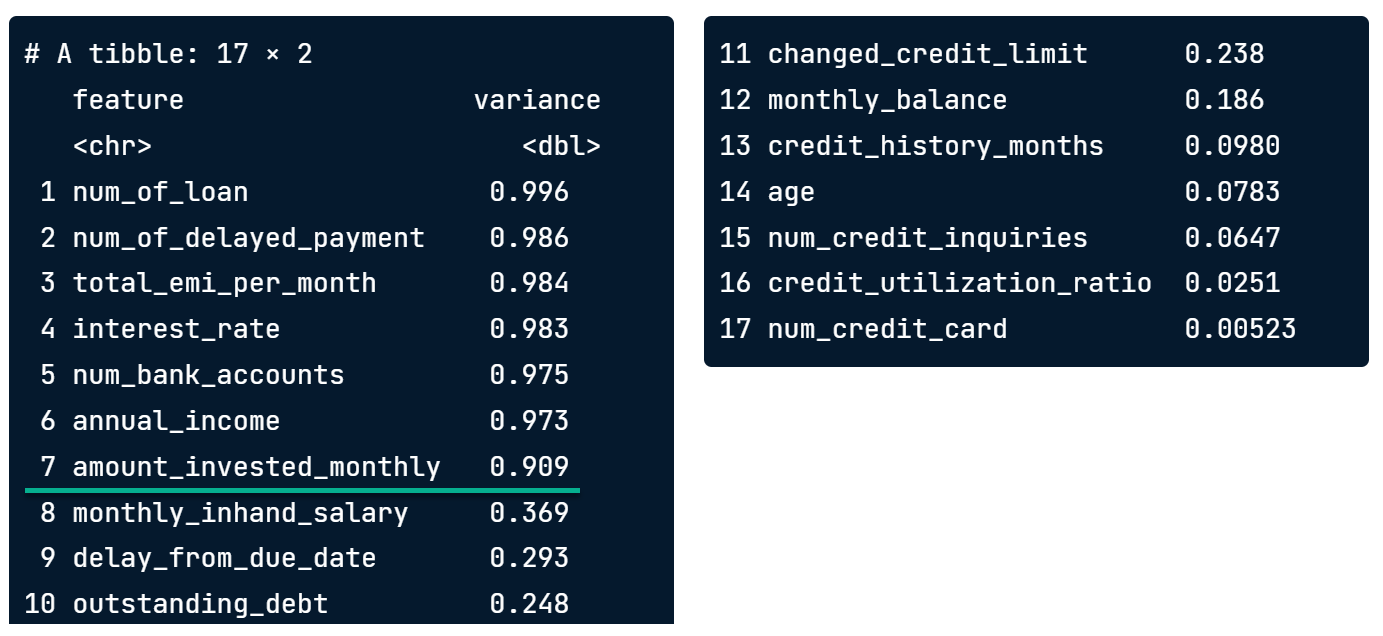
Variance cutoff

Variance cutoff
Variance cutoff
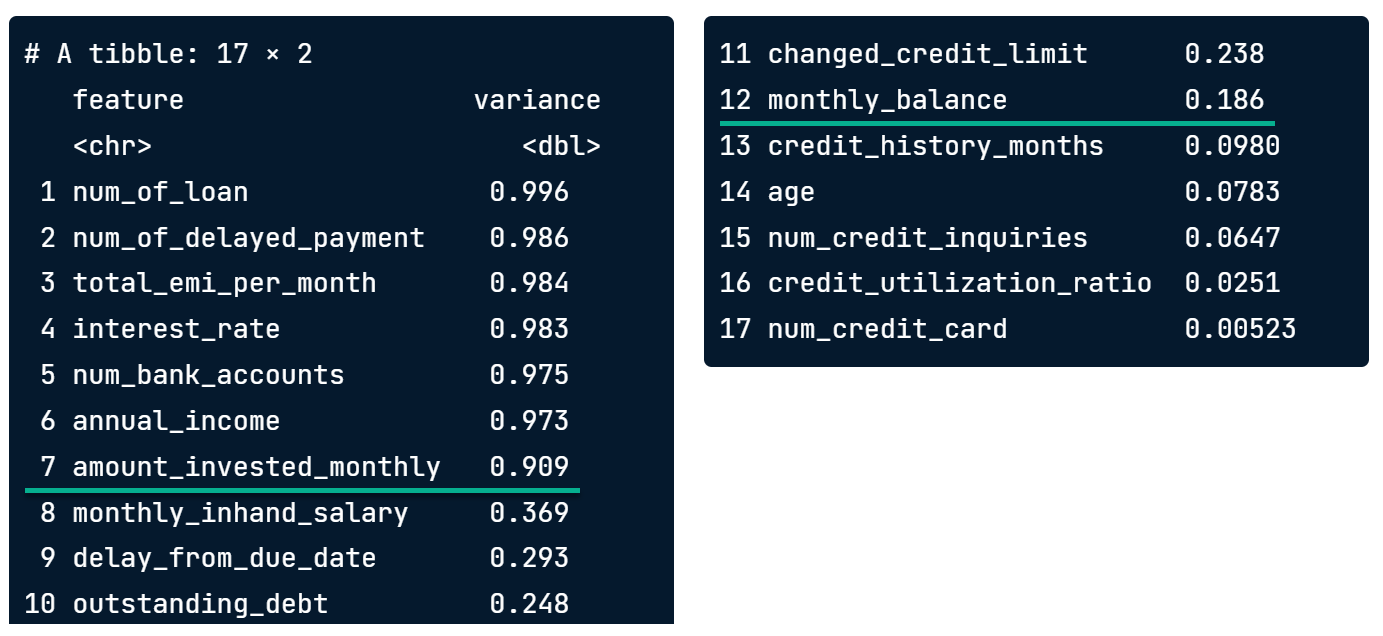
Variance cutoff
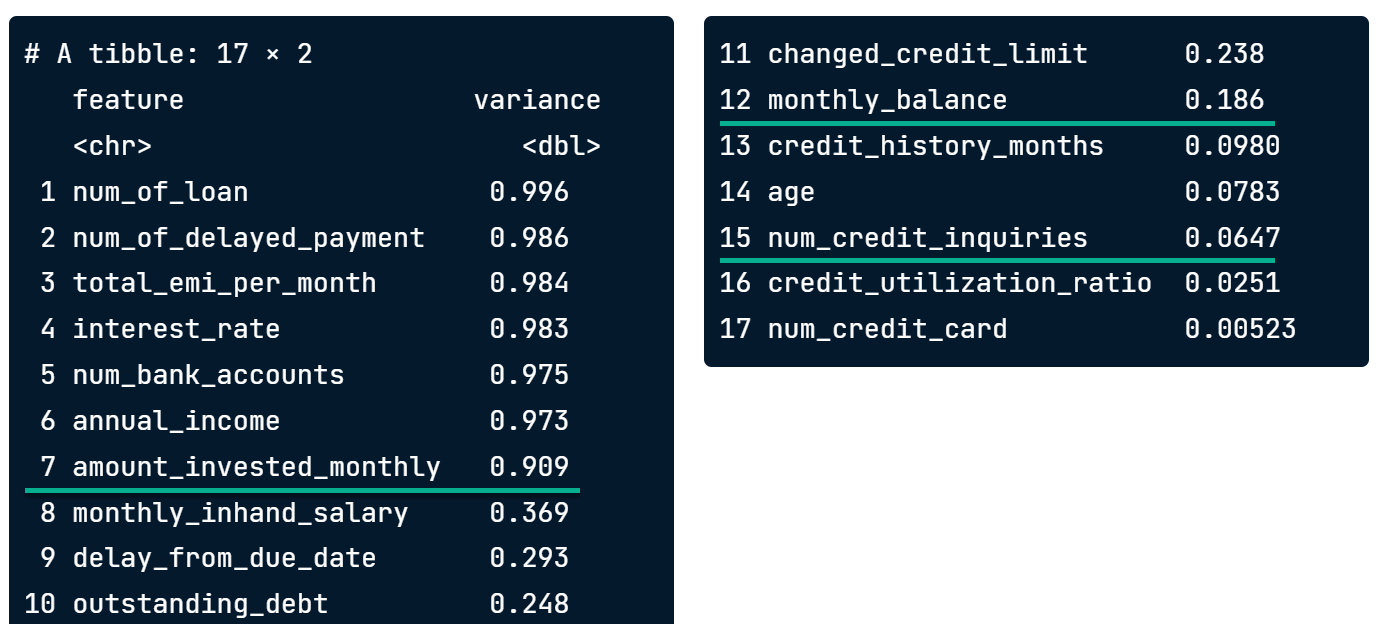
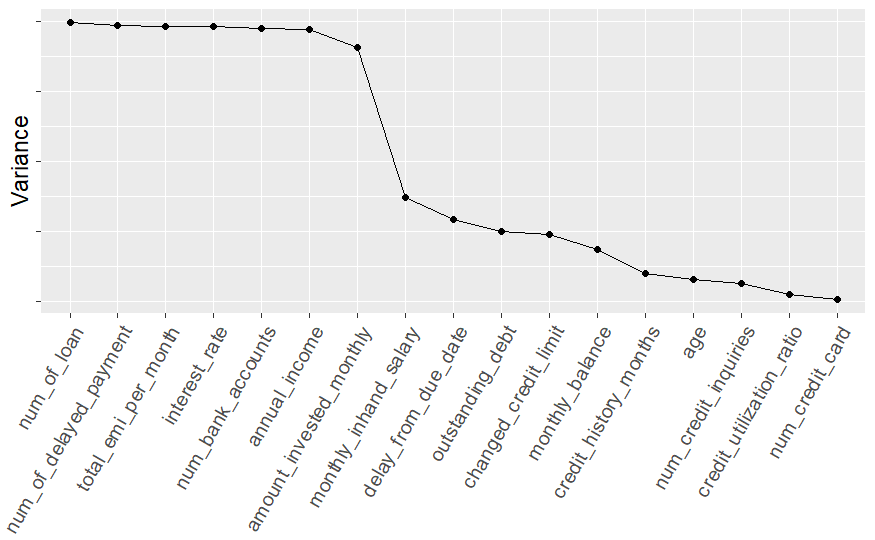
Variance cutoff plot
Dimensionality Reduction in R
Matt Pickard
Owner, Pickard Predictives, LLC

