Hyperparameters of KNN
Anomaly Detection in Python

Bekhruz (Bex) Tuychiev
Kaggle Master, Data Science Content Creator
Distance metrics

Manhattan distance
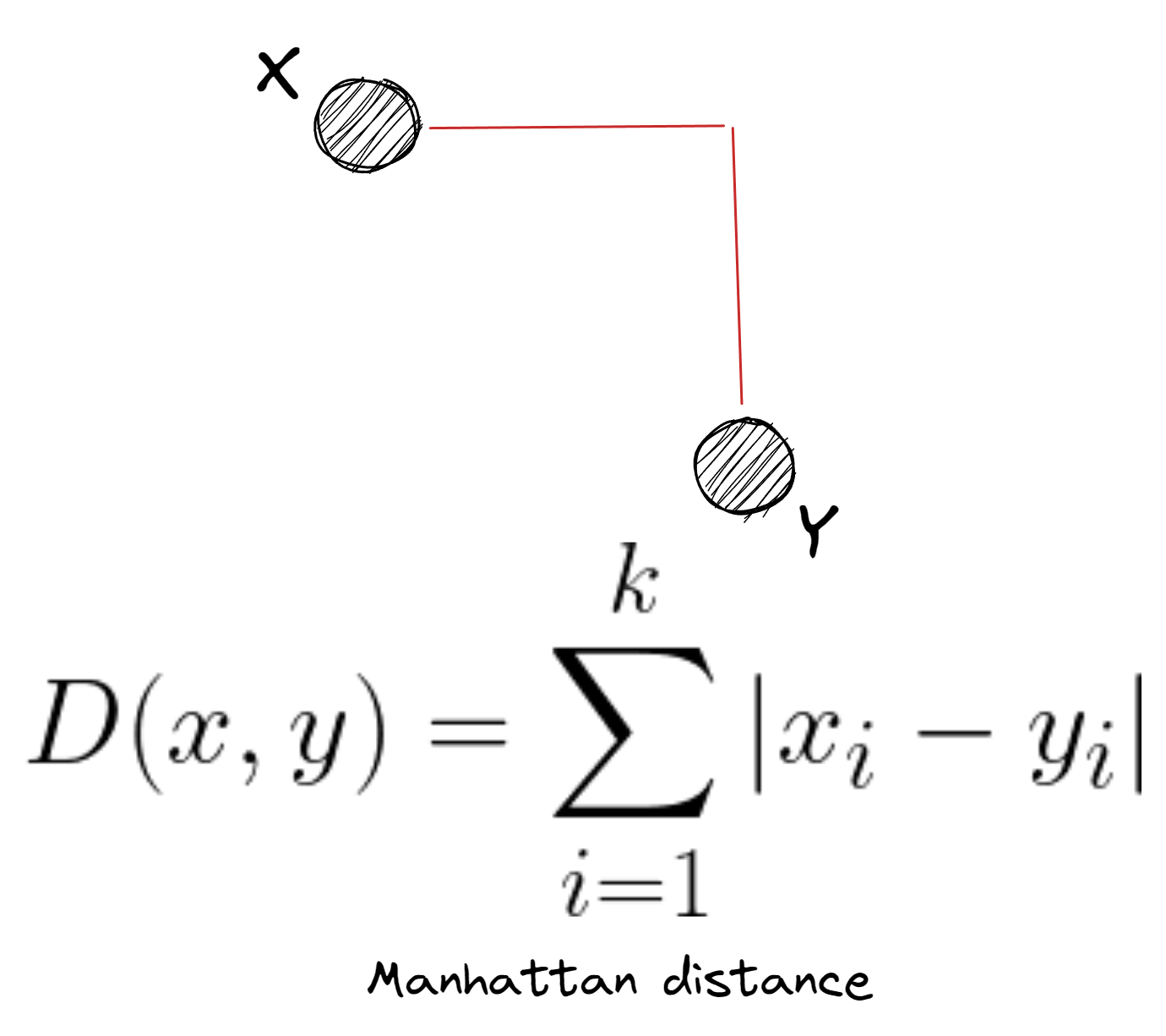
Manhattan distance
Minkowski distance
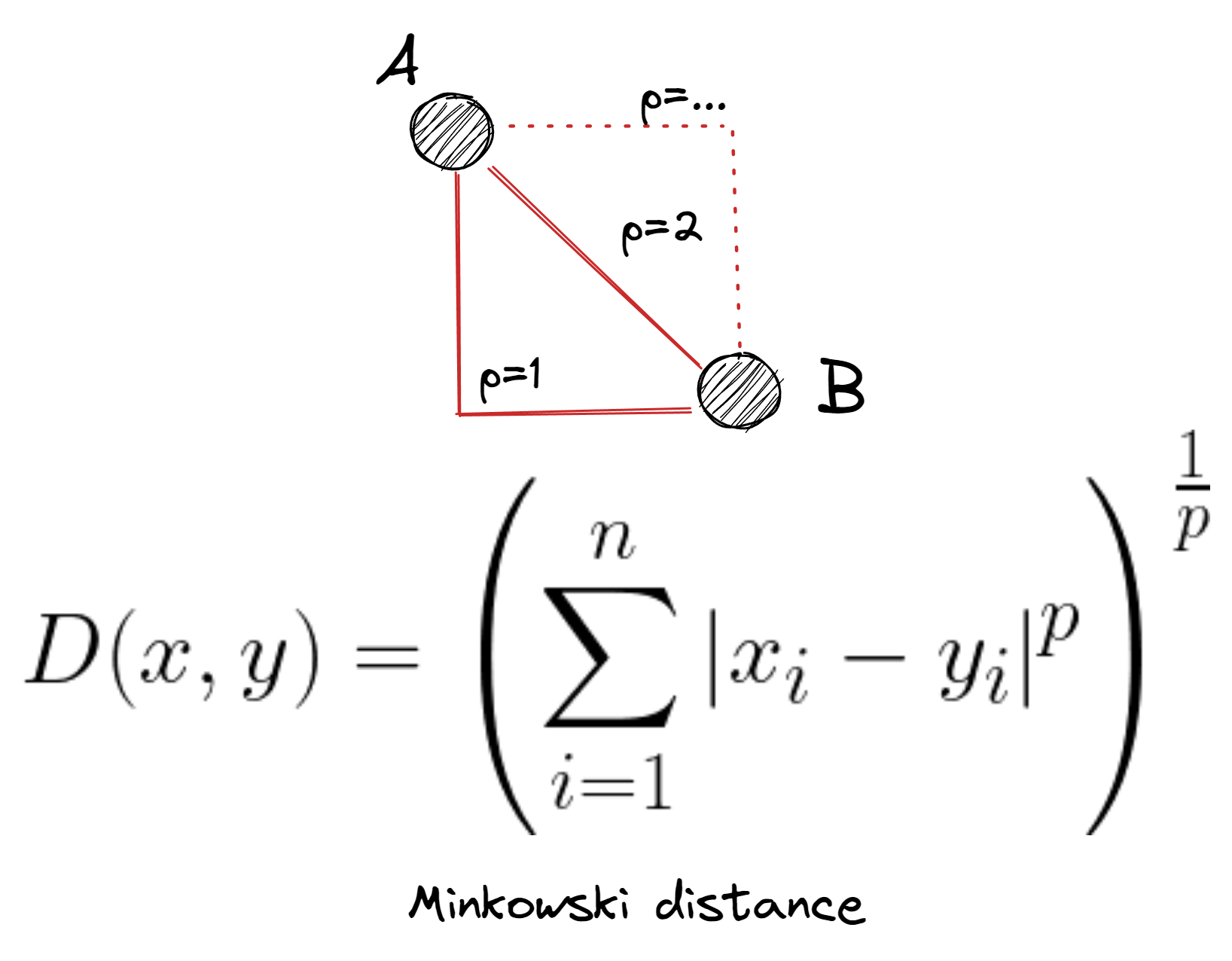
Anomaly Detection in Python
Bekhruz (Bex) Tuychiev
Kaggle Master, Data Science Content Creator

