Getting started with Isolation Forests
Anomaly Detection in Python

Bekhruz (Bex) Tuychiev
Kaggle Master, Data Science Content Creator
Survey data

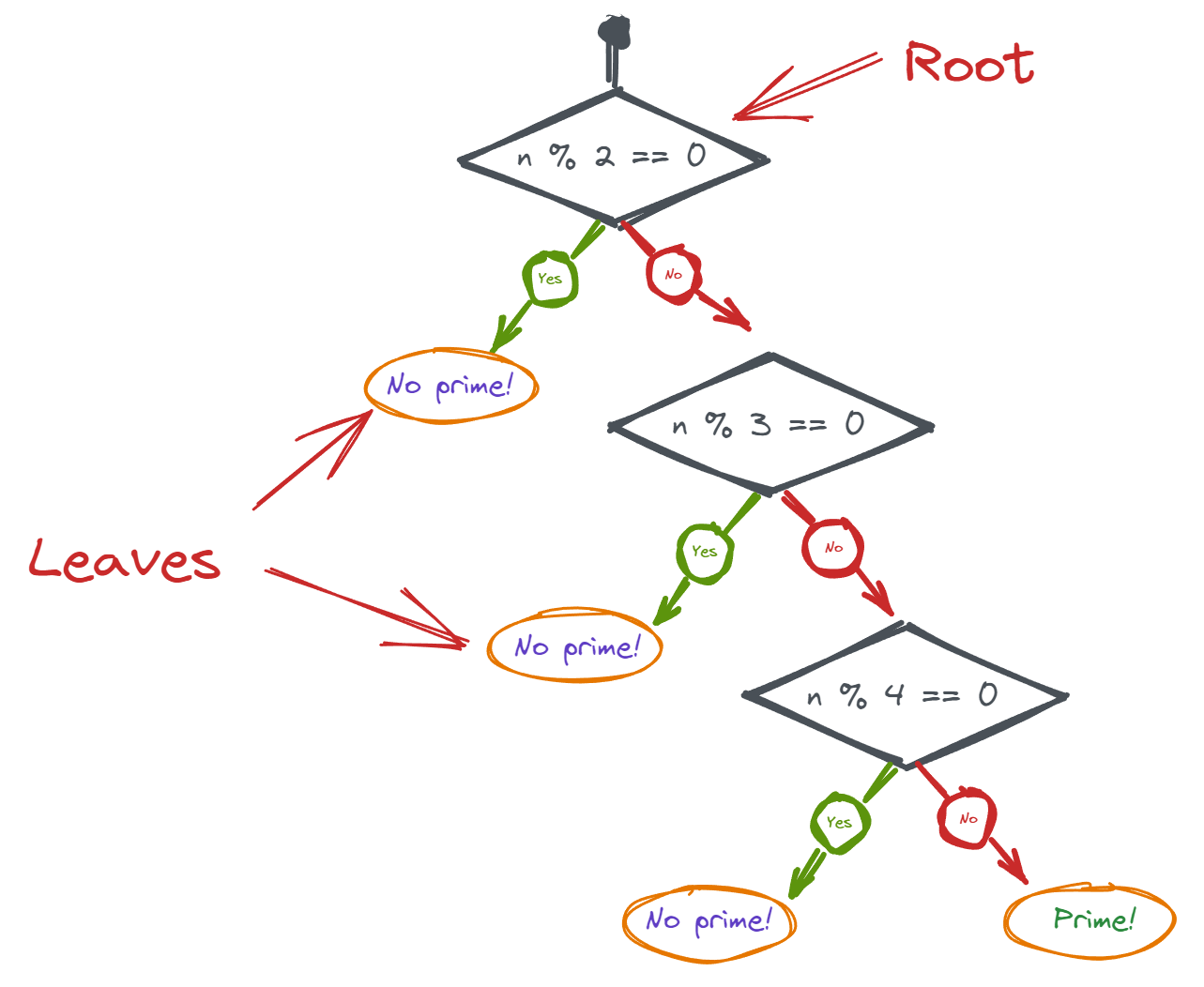
Decision trees
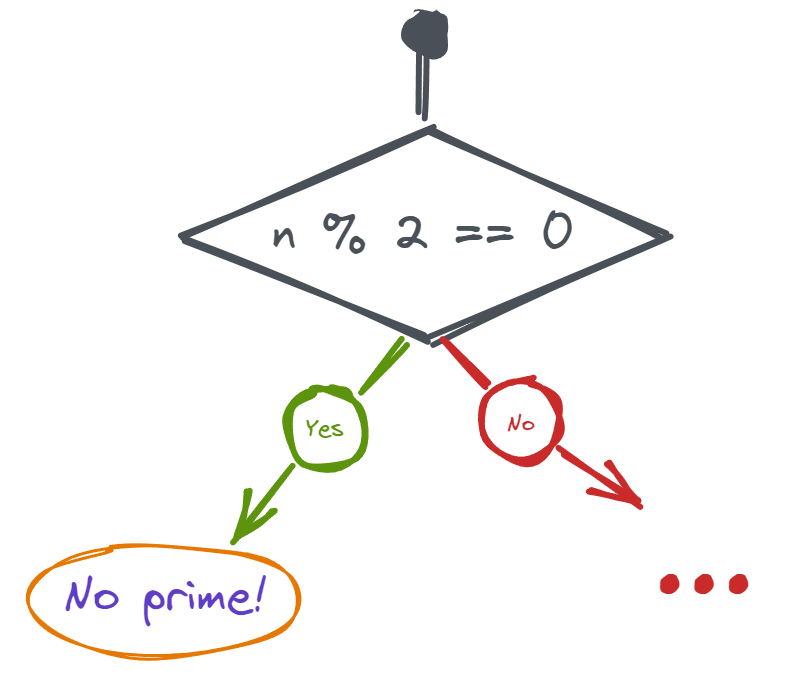
Decision trees
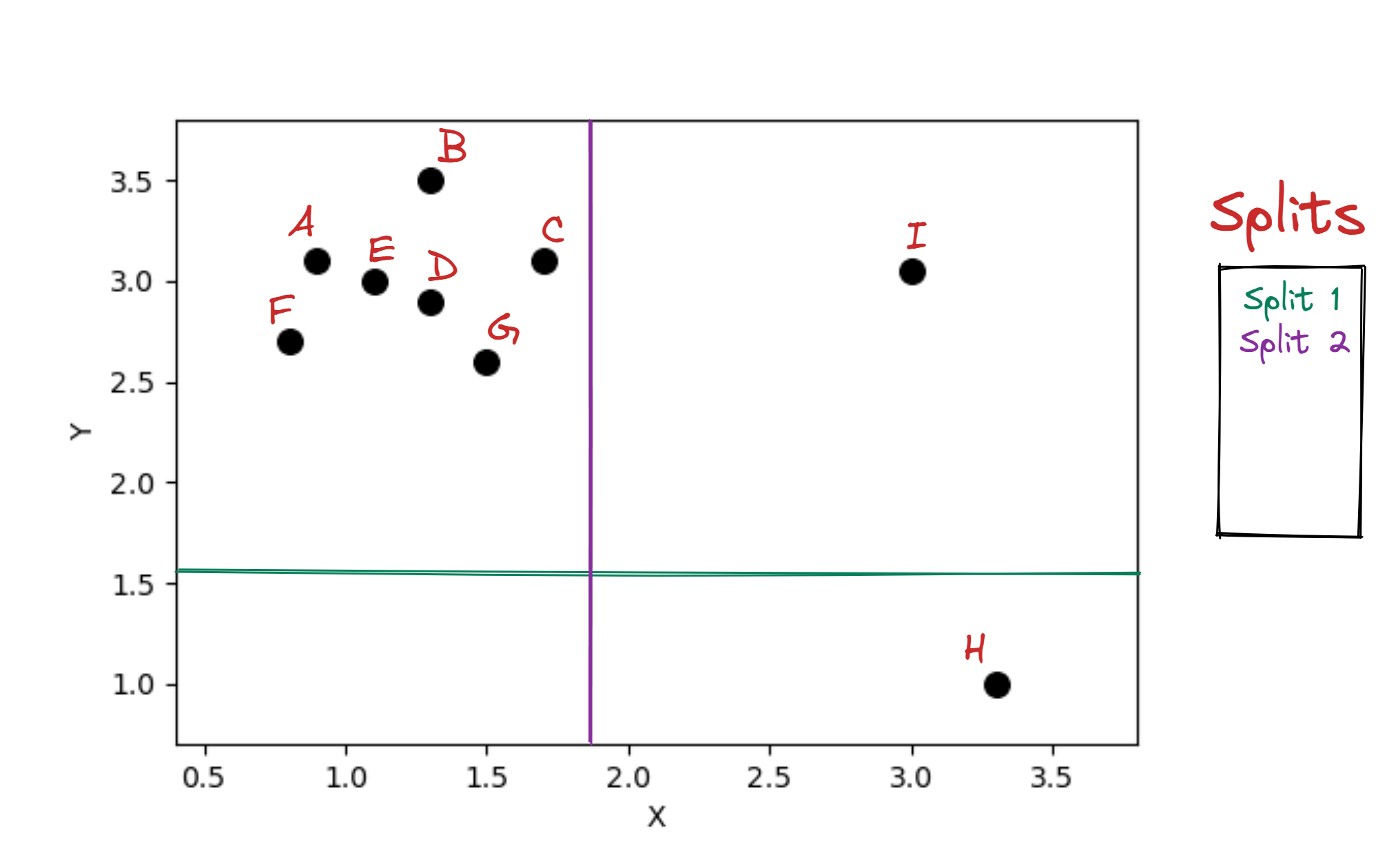
Example 2D data
Fitting an iTree
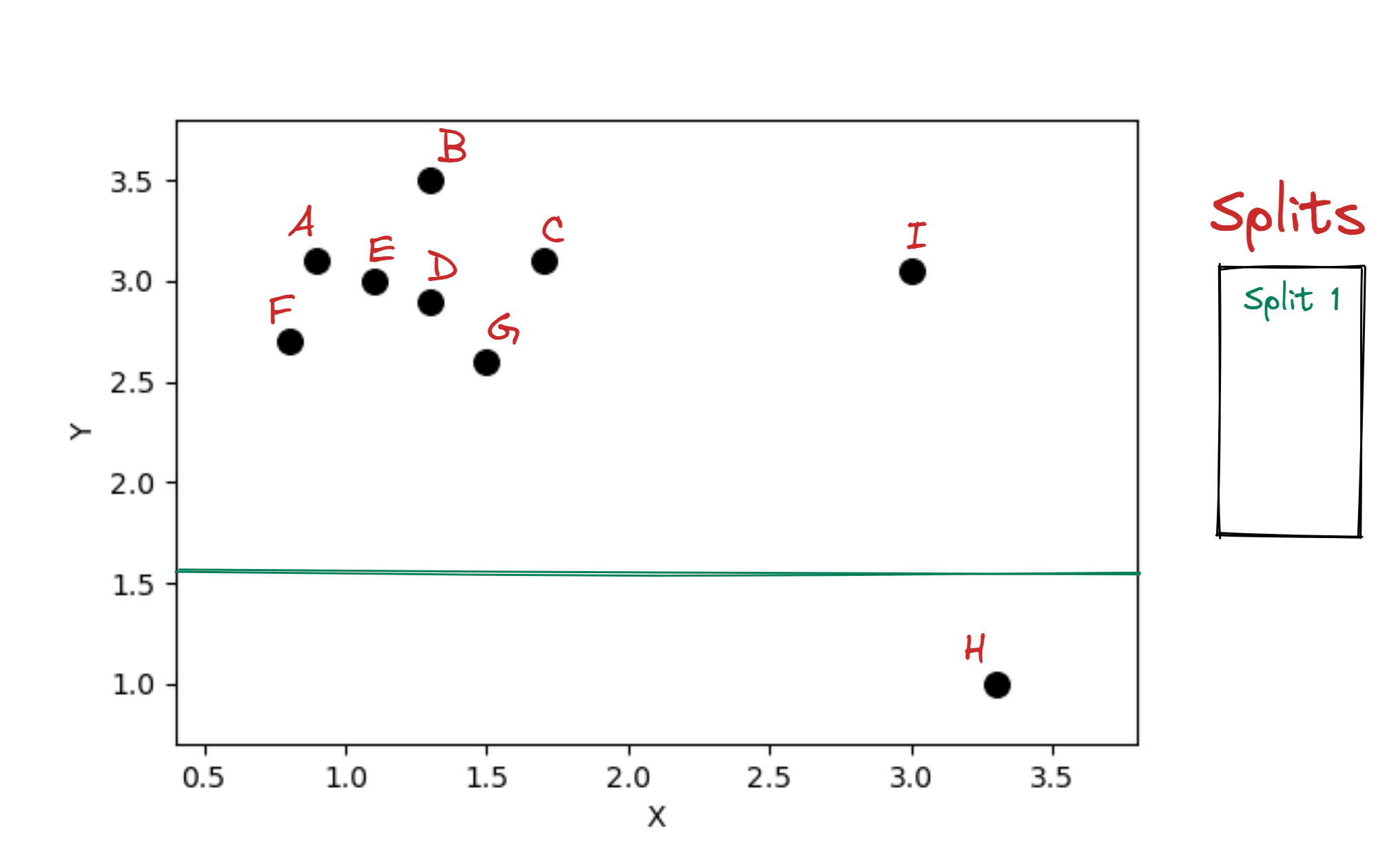
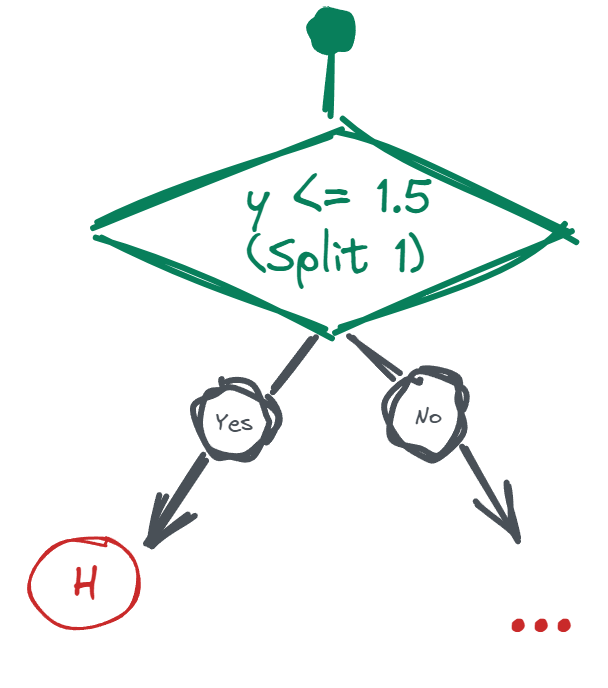
Fitting an iTree
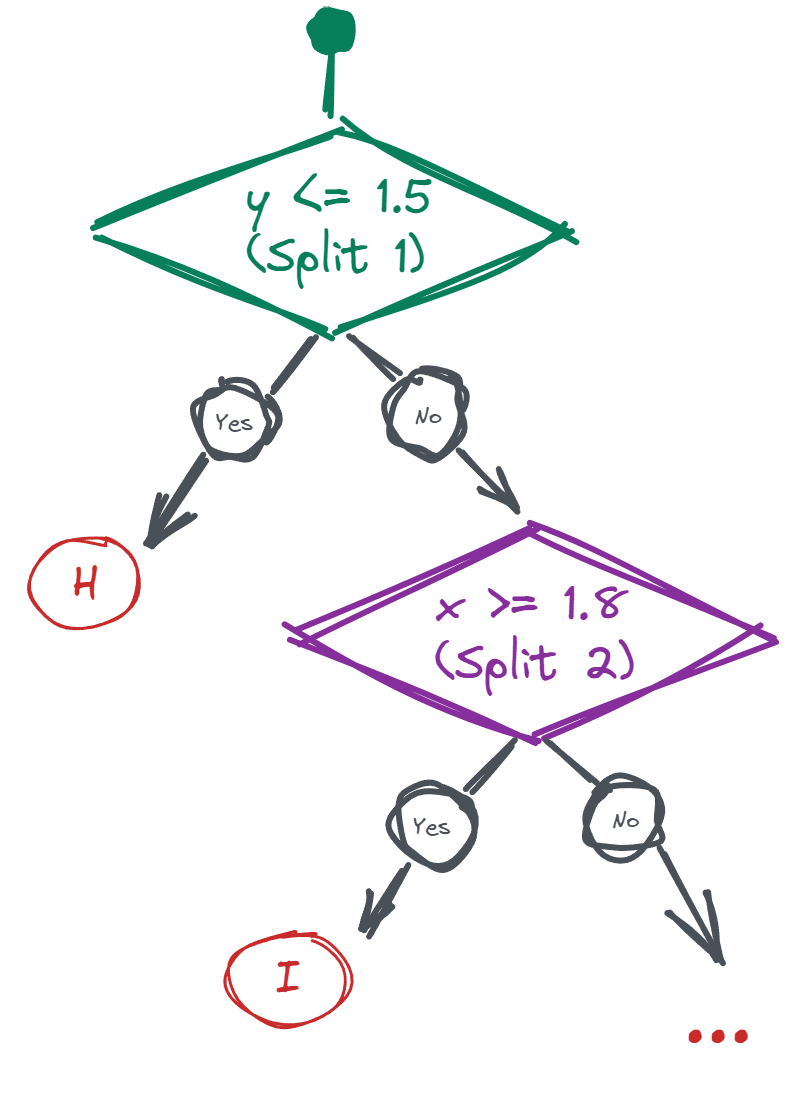
Fitting an iTree
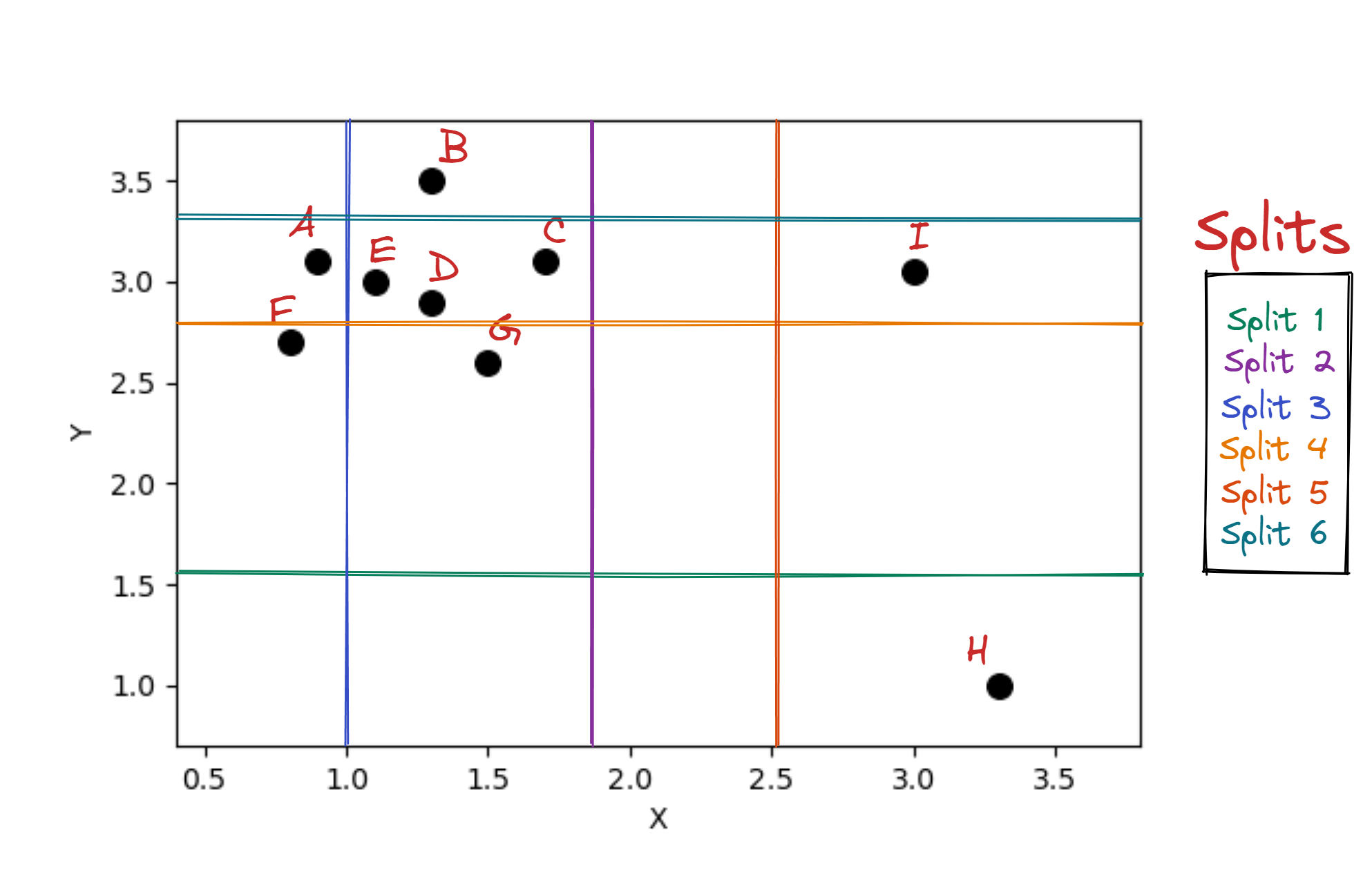
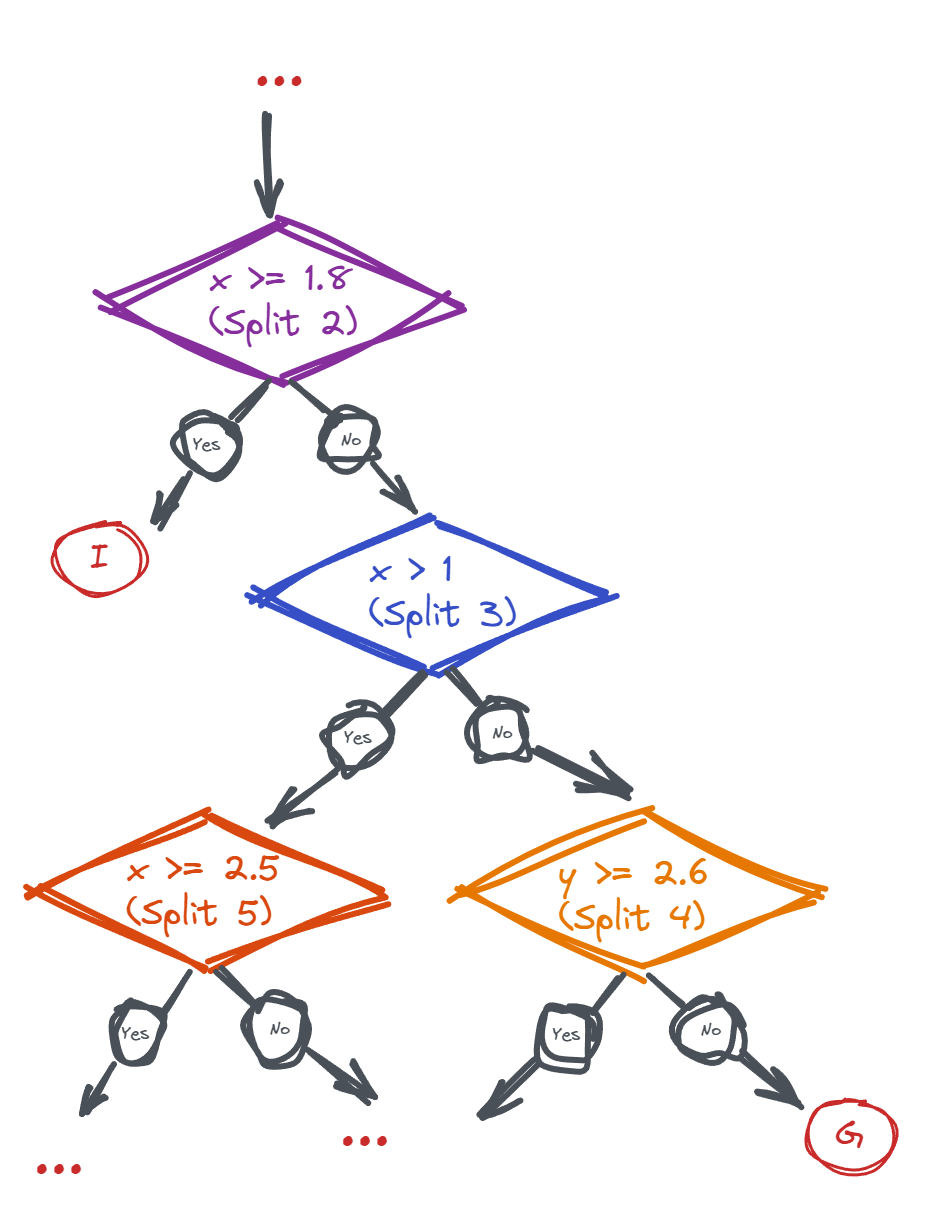
How points are classified

