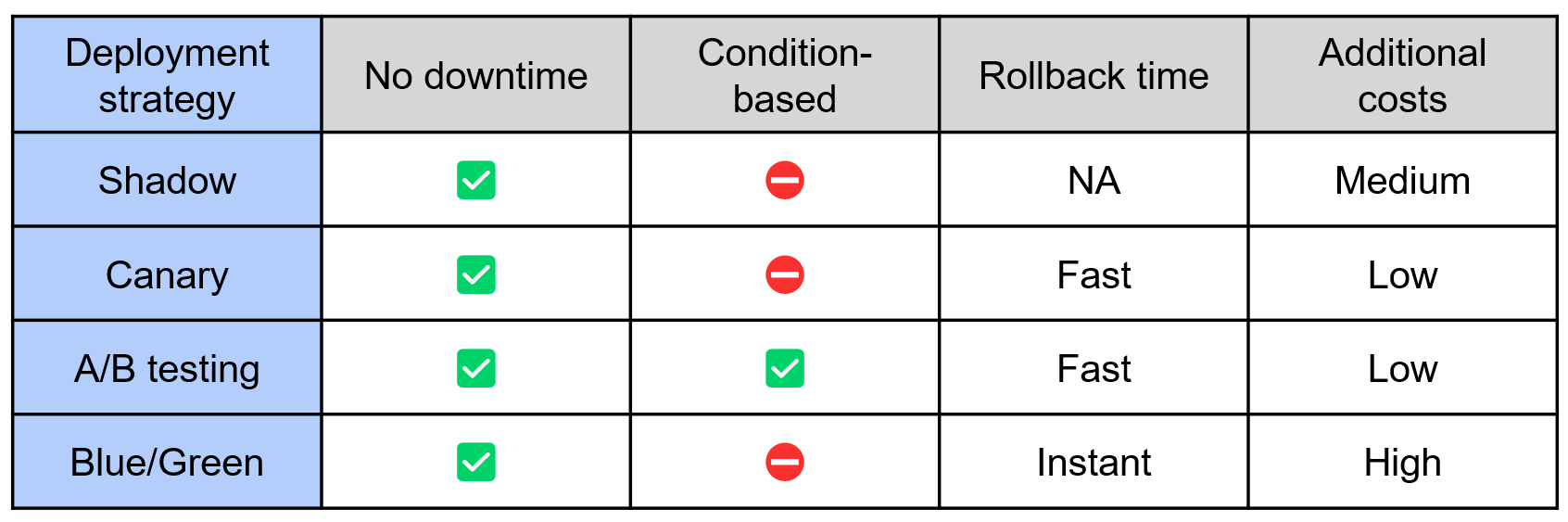
Automation in MLOps deployment strategies
Fully Automated MLOps

Arturo Opsetmoen Amador
Senior Consultant - Machine Learning
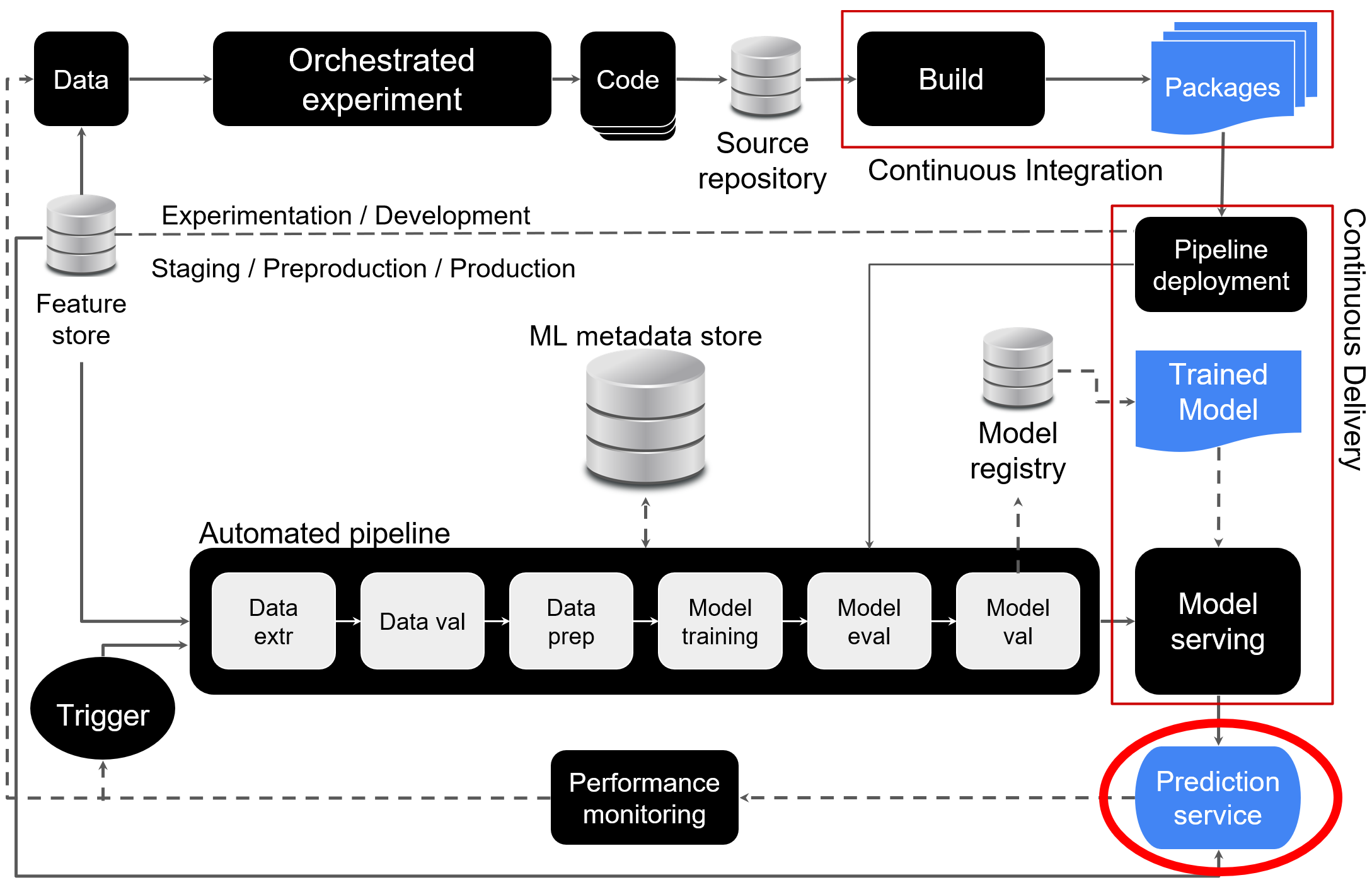
Model deployment - prediction service
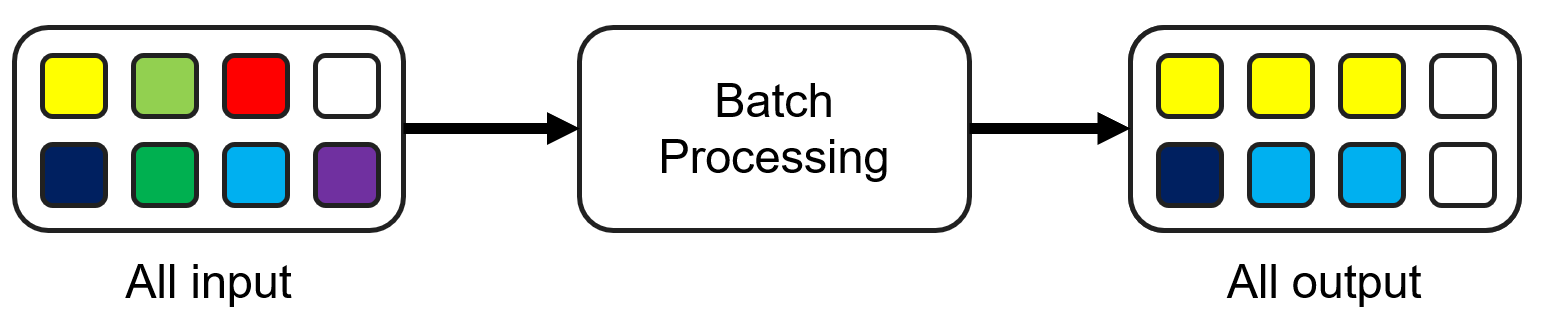
Prediction service - batch serving
$$
$$
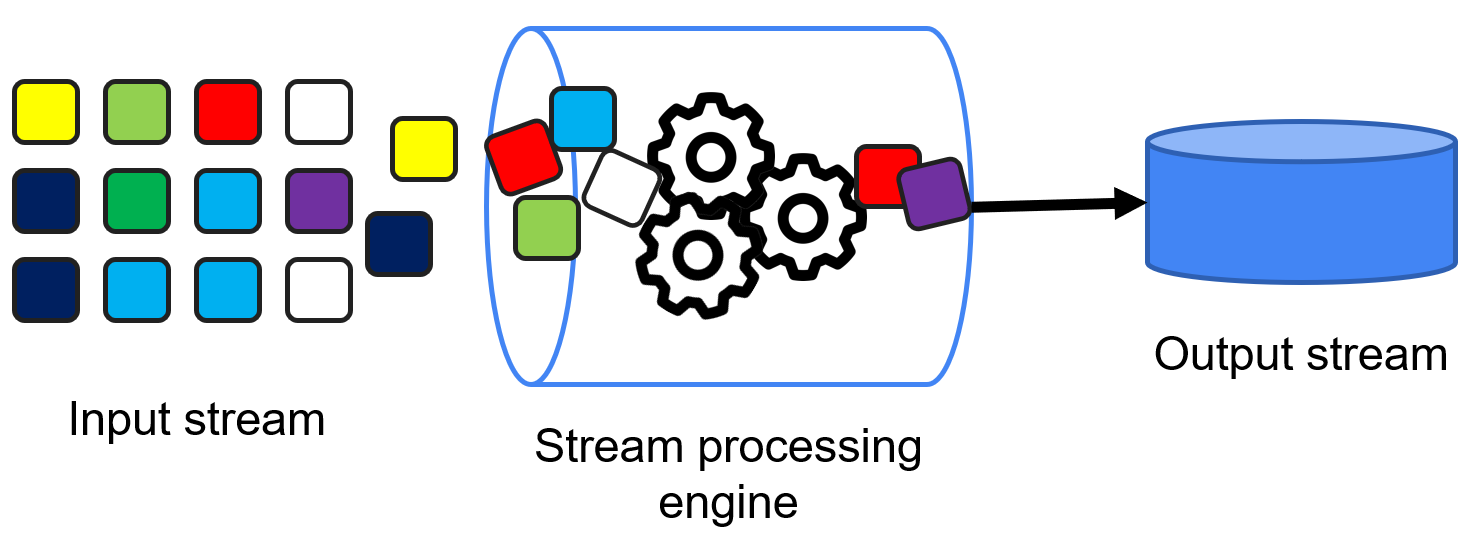
Prediction service - streaming serving
$$
Prediction service - real time
$$

Prediction service - on the edge
$$

A/B testing
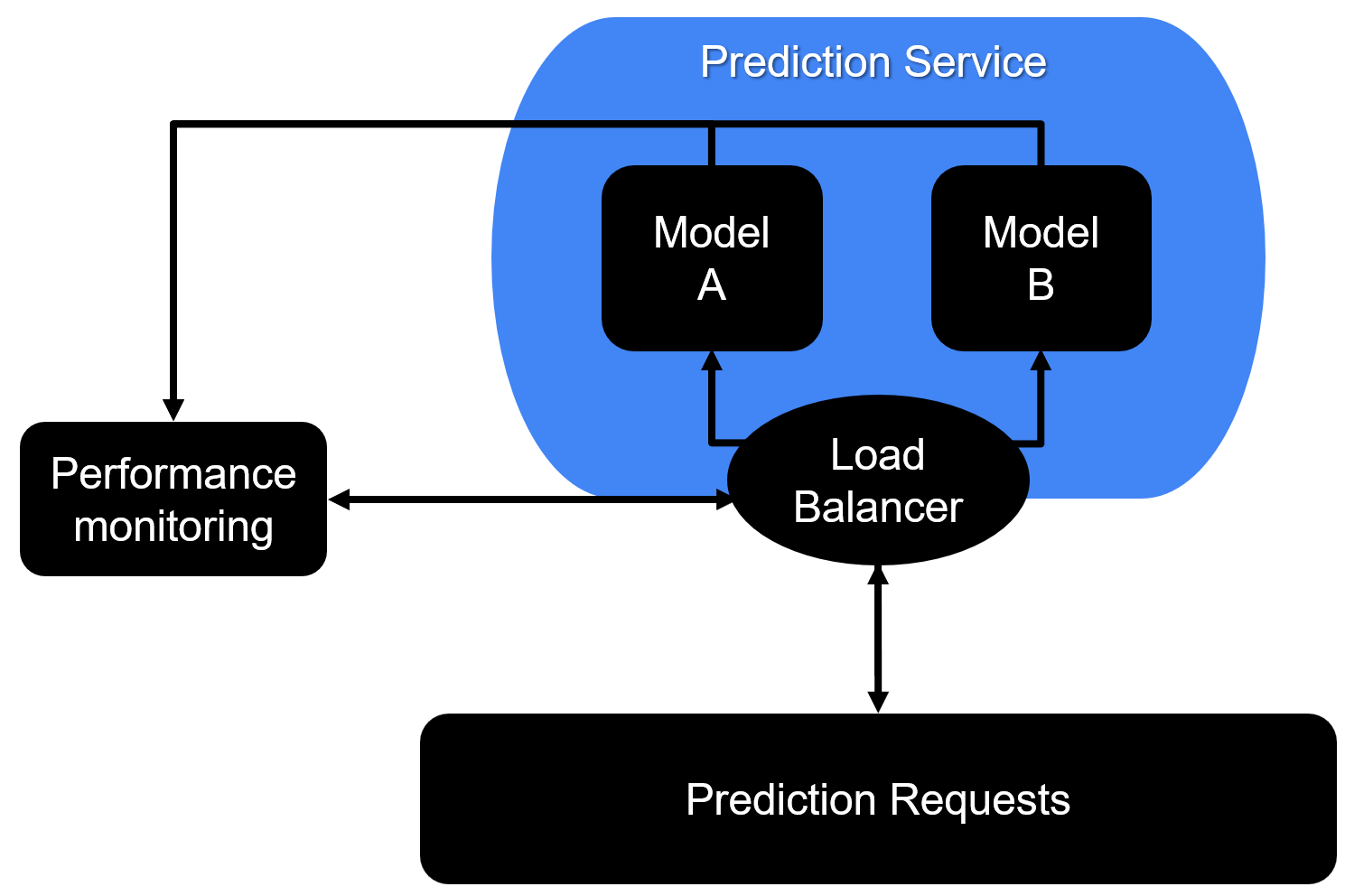
A/B testing
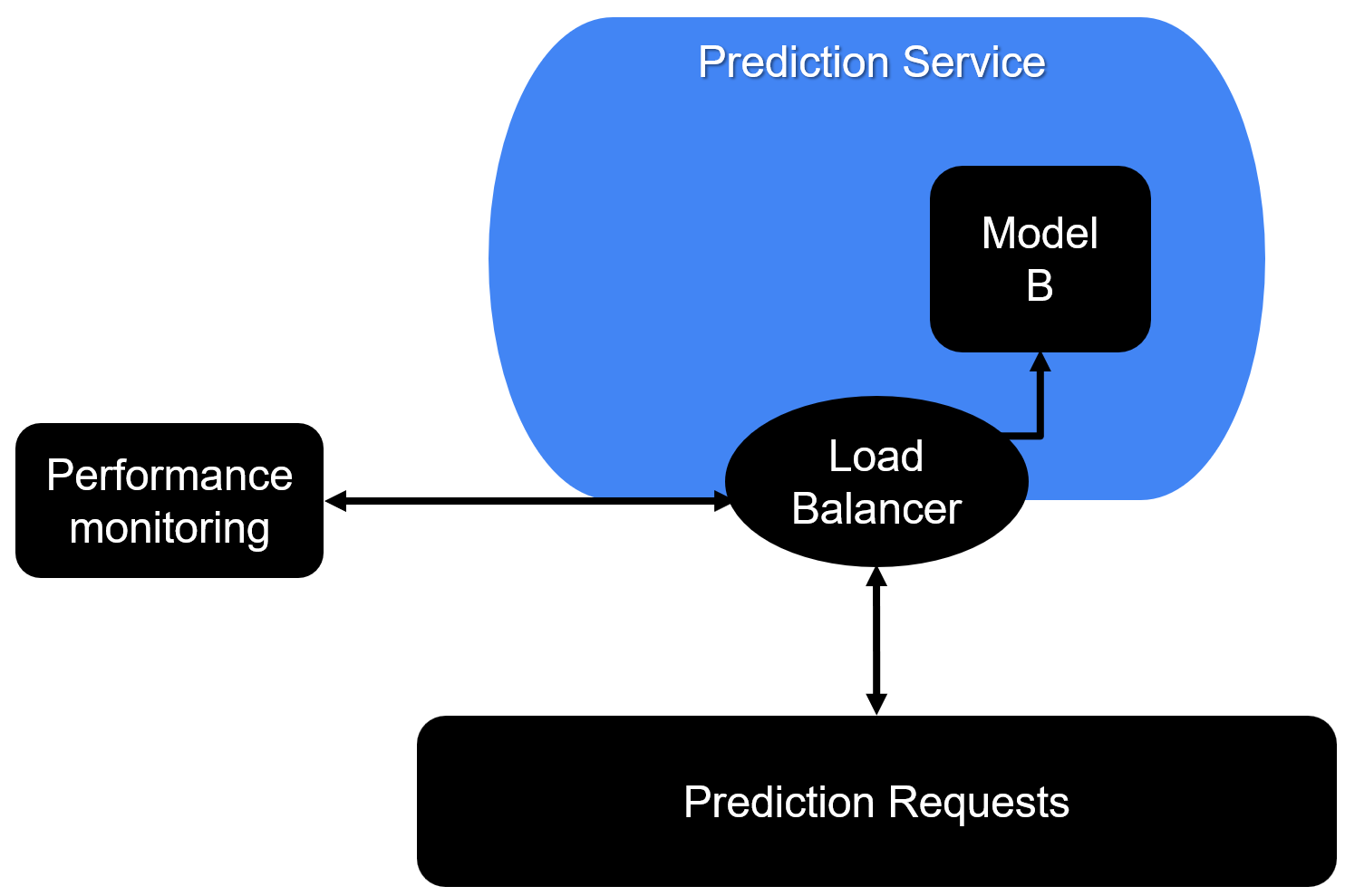
Shadow deployment
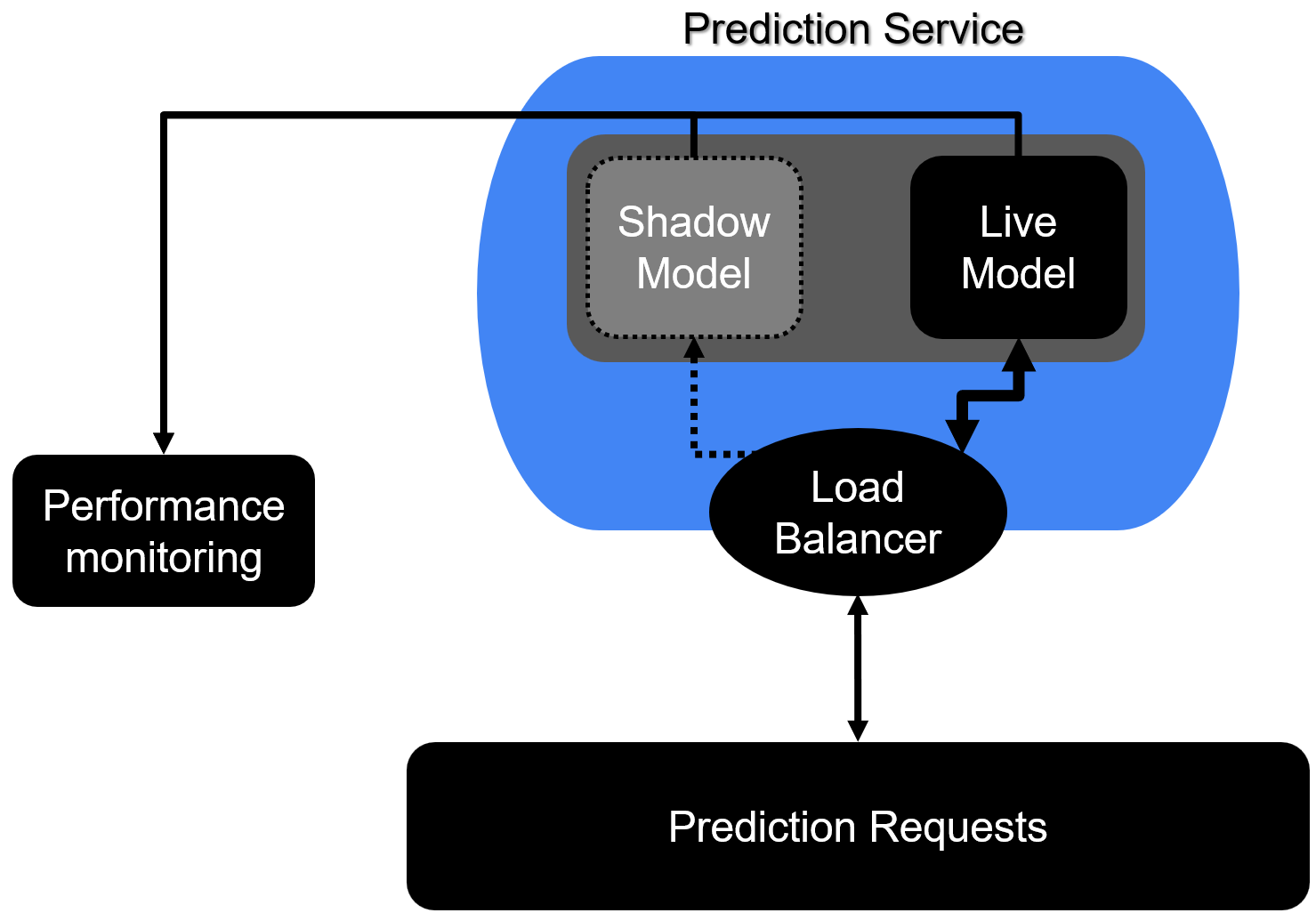
Blue/Green deployment
Blue/Green deployment
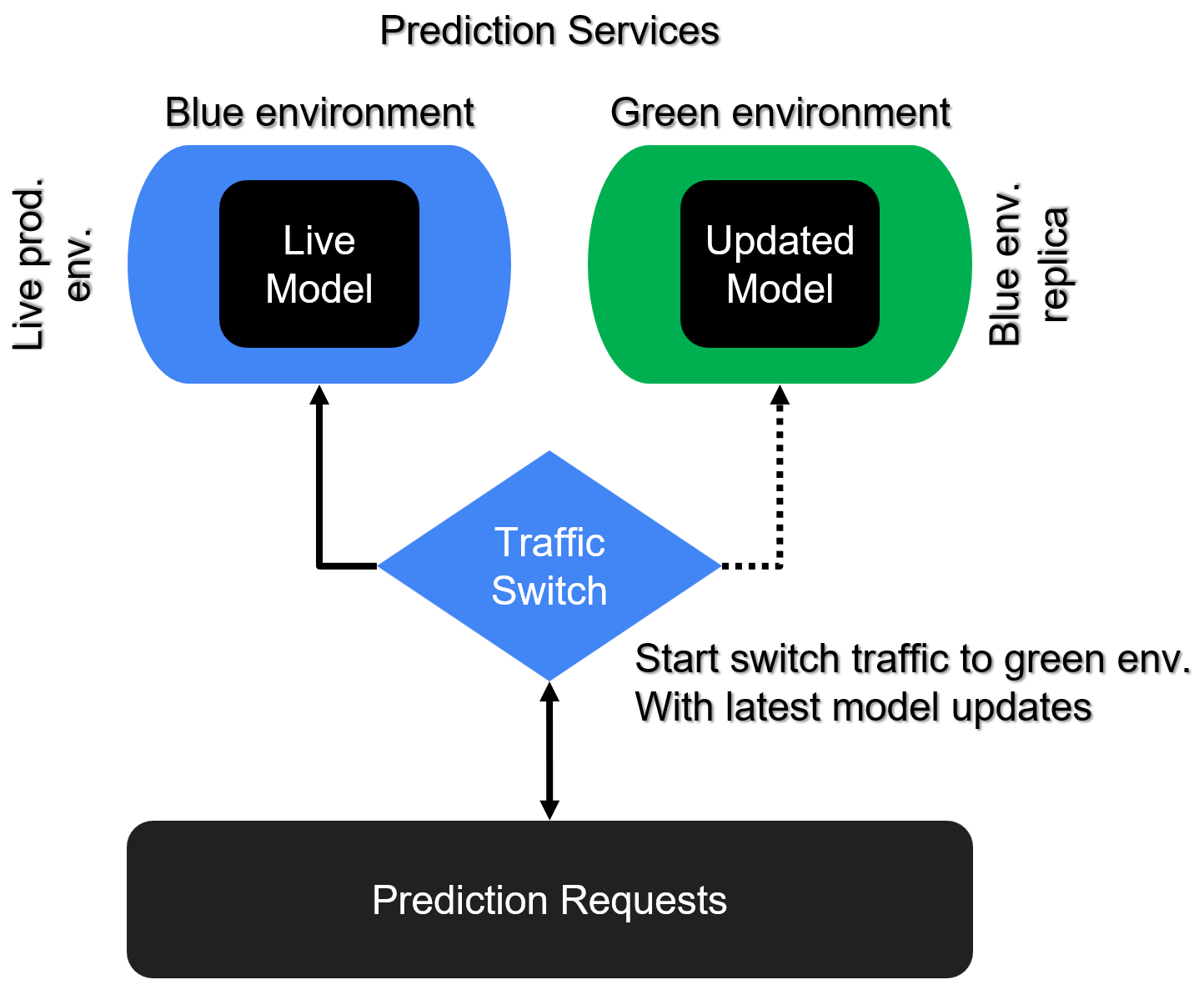
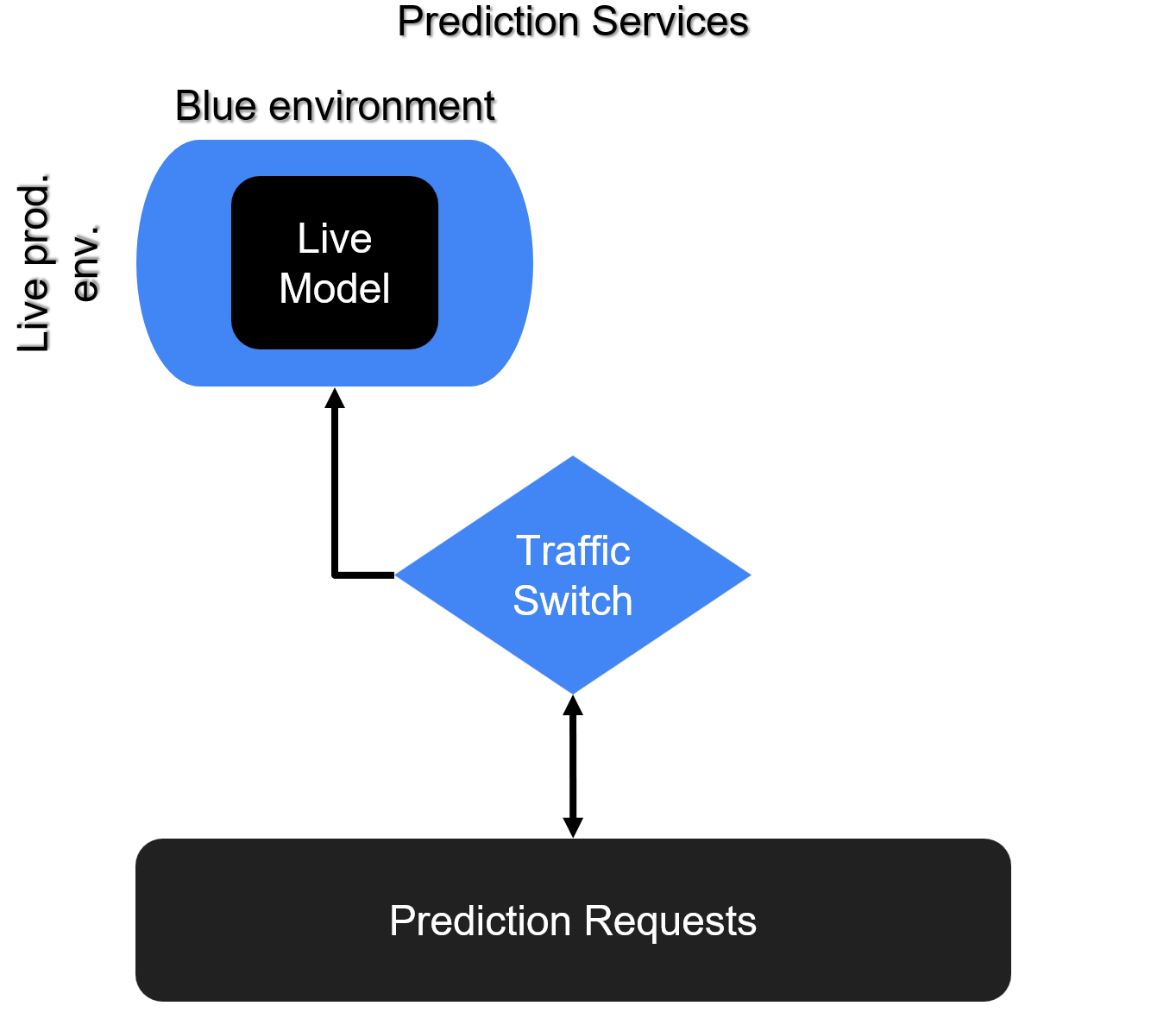
Blue/Green deployment
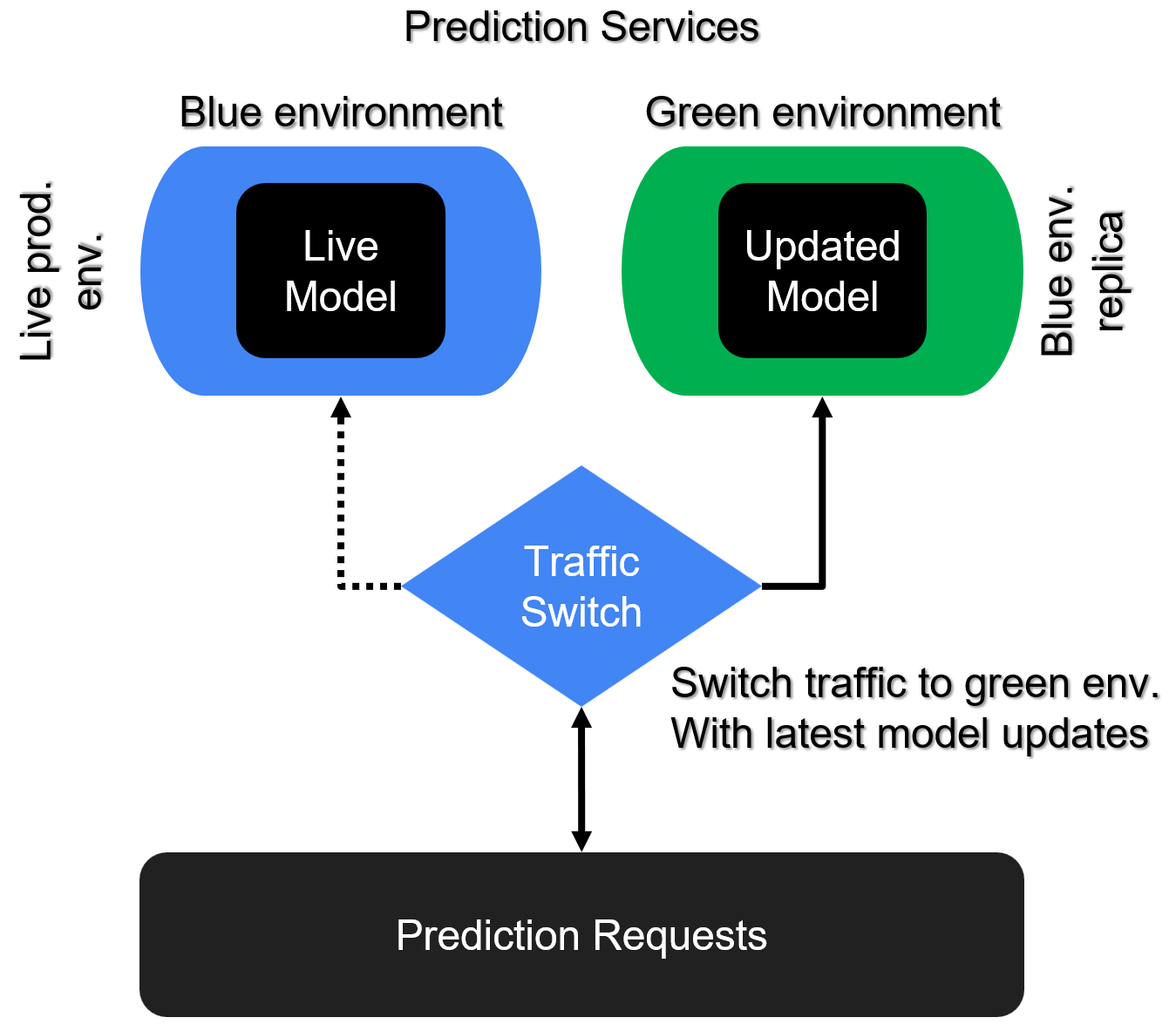
Blue/Green deployment
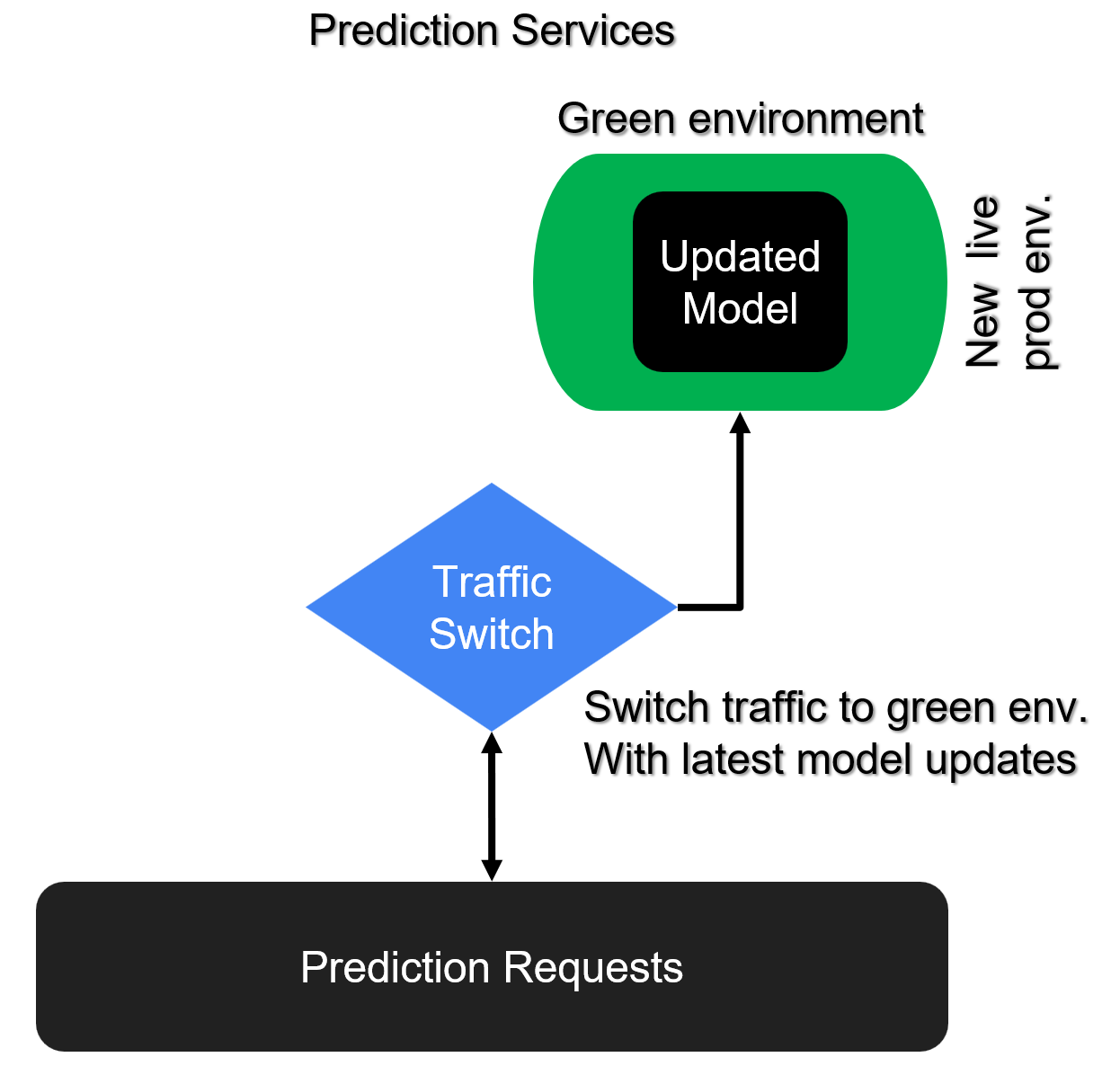
Deploying and updating prediction services
$$
Model type determines deployment strategy