Regression analysis
Analyzing Survey Data in Python

EbunOluwa Andrew
Data Scientist
Regression analysis
- Understand the relationship between variables
- Utilized to predict a precise outcome
- Gauge influence of different independent variables on dependent variable
- Forecasts potential future opportunities and risks
- Reduces huge piles of raw data into actionable information
- Provides factual support for informed decisions

Linear regression using ordinary least squares (OLS) method

1 https://seeing-theory.brown.edu/regression-analysis/index.html
Add constant term

Perform regression and fit
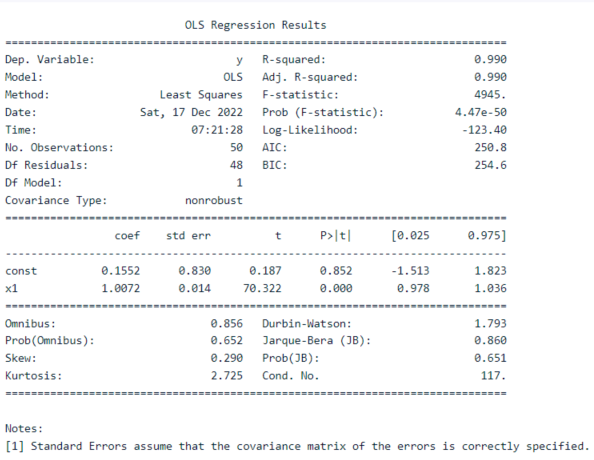
Retrieving m and b
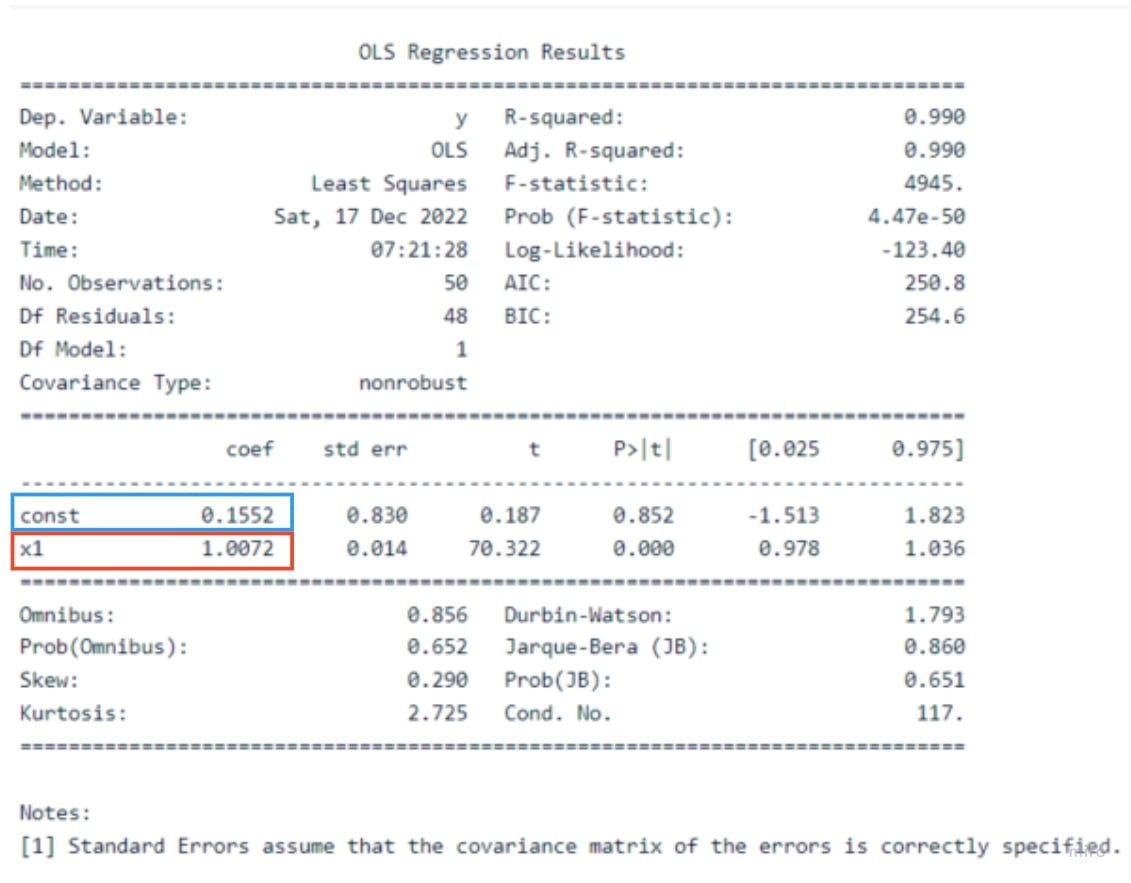
Plot original values
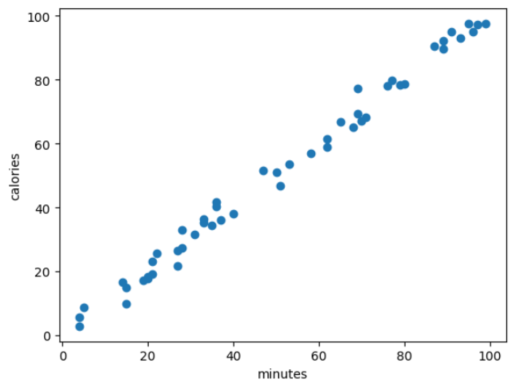
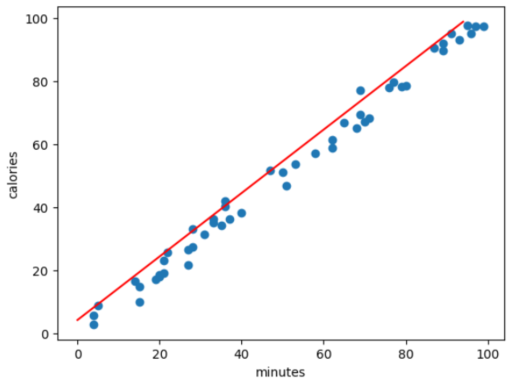
Plotting the regression line
Linear regression pros and cons
- Pro
- Performs well when data is linearly separable
- Con
- Assumes linear relationship for non-linear cases

