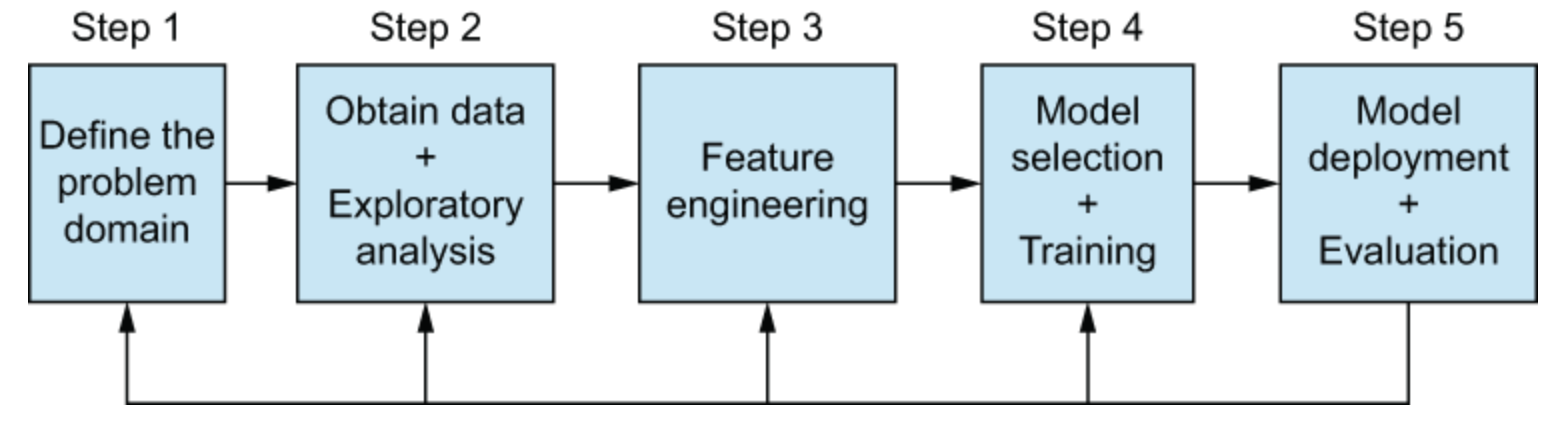
Feature engineering
Developing Machine Learning Models for Production

Sinan Ozdemir
Data Scientist and Author
Introduction to feature engineering
- Transforming training data to maximize ML pipeline performance
- Reducing computation complexity
- Examples
- Aggregating data from multiple sources
- Constructing new features
- Applying feature transformations
1 https://www.manning.com/books/feature-engineering-bookcamp
Aggregating data from multiple sources
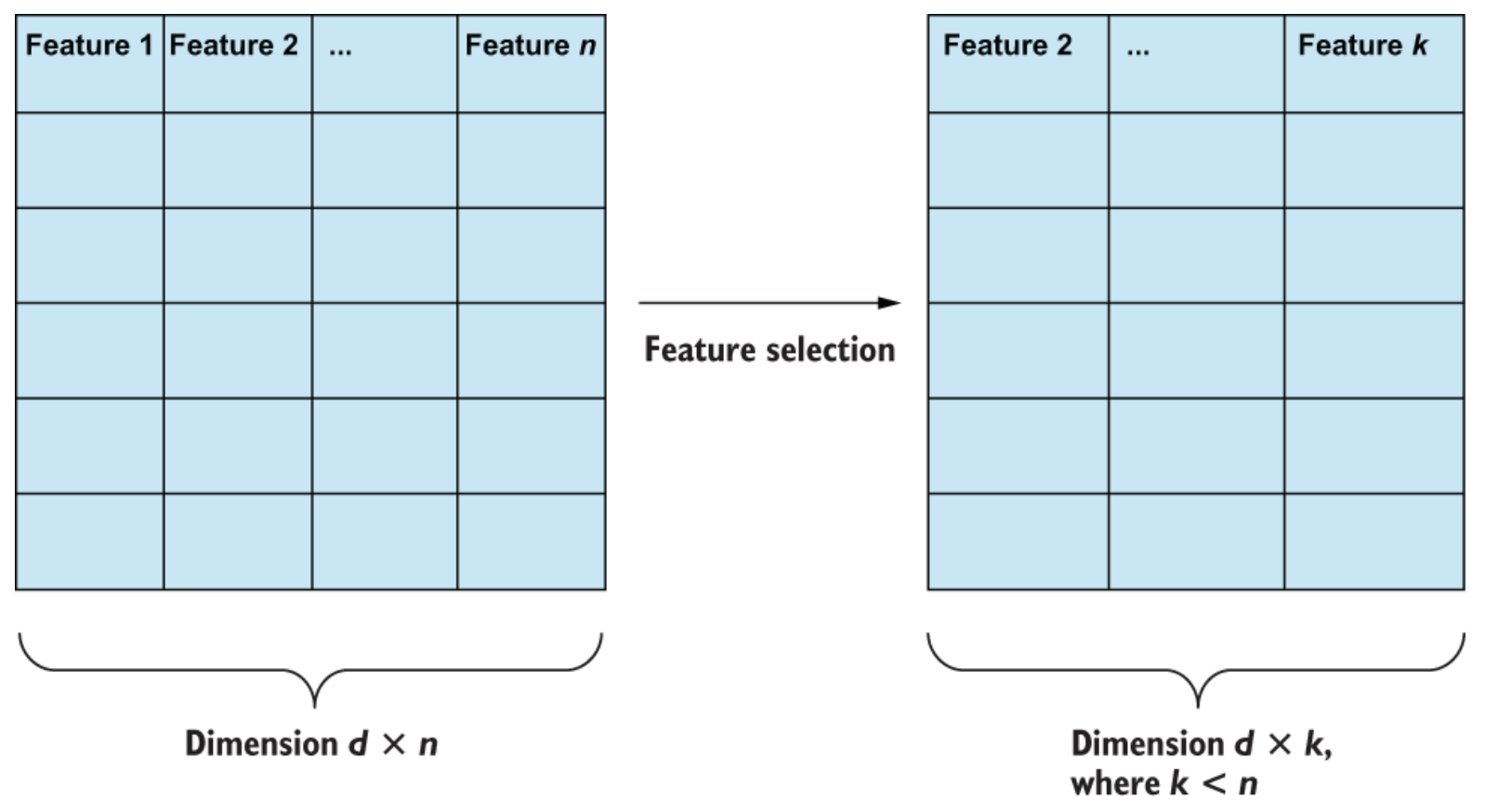
Feature selection
1 https://www.manning.com/books/feature-engineering-bookcamp
Learn more about feature engineering


