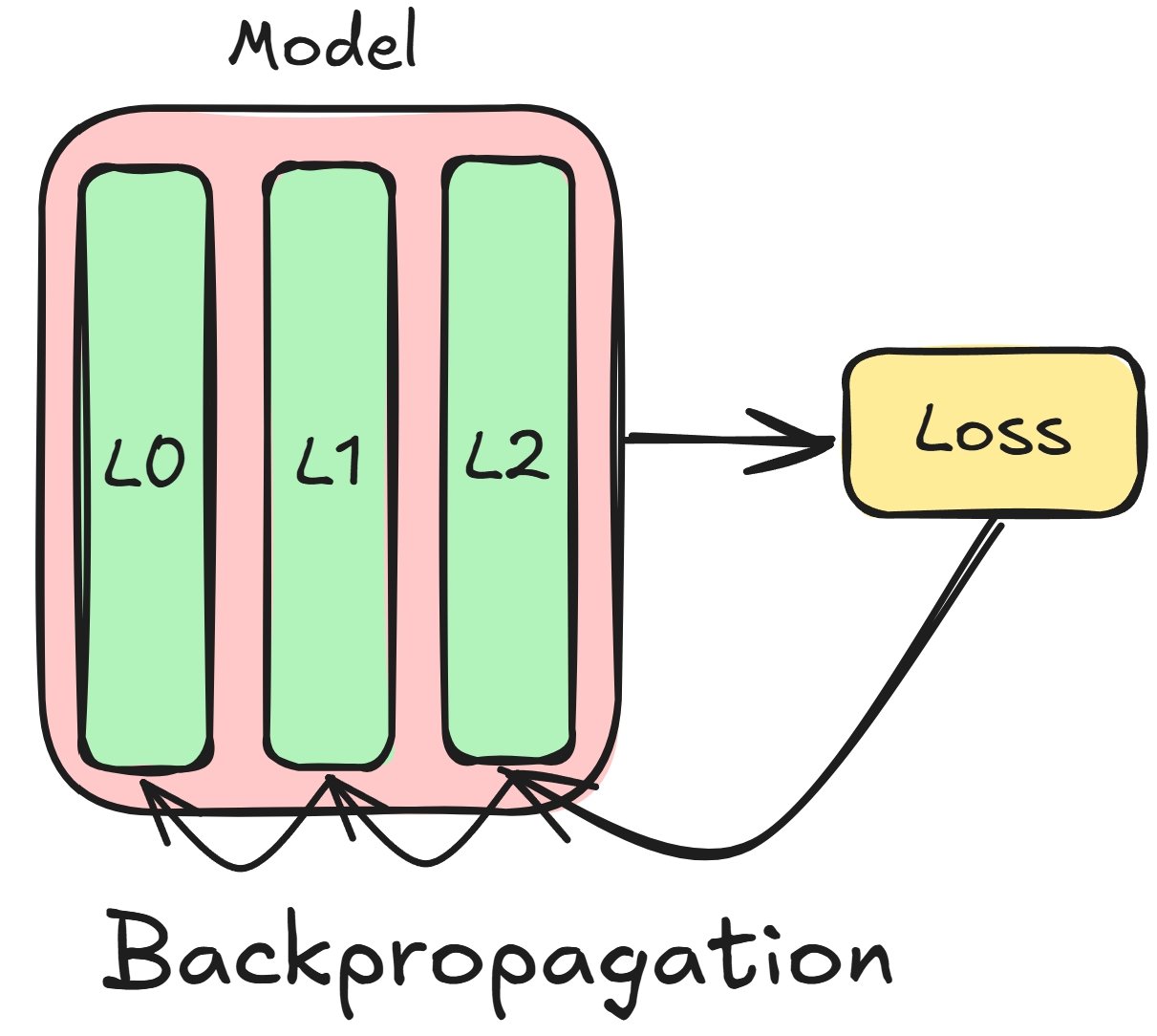
Using derivatives to update model parameters
Introduction to Deep Learning with PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
An analogy for derivatives
$$

Convex and non-convex functions
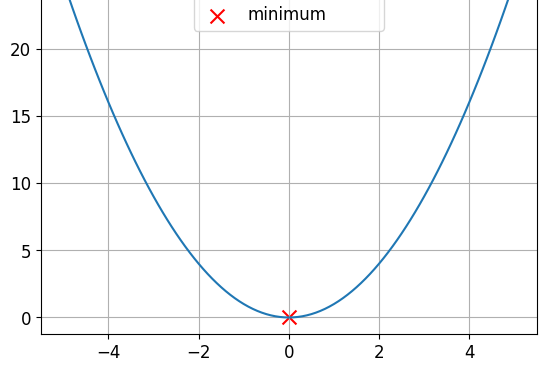
This is a convex function
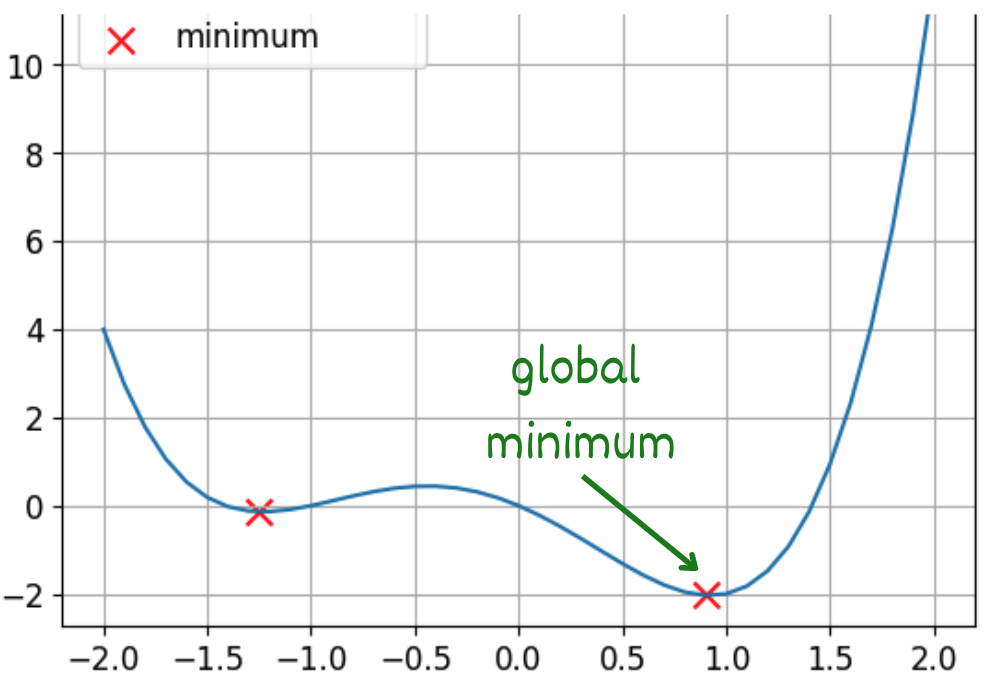
This is a non-convex function
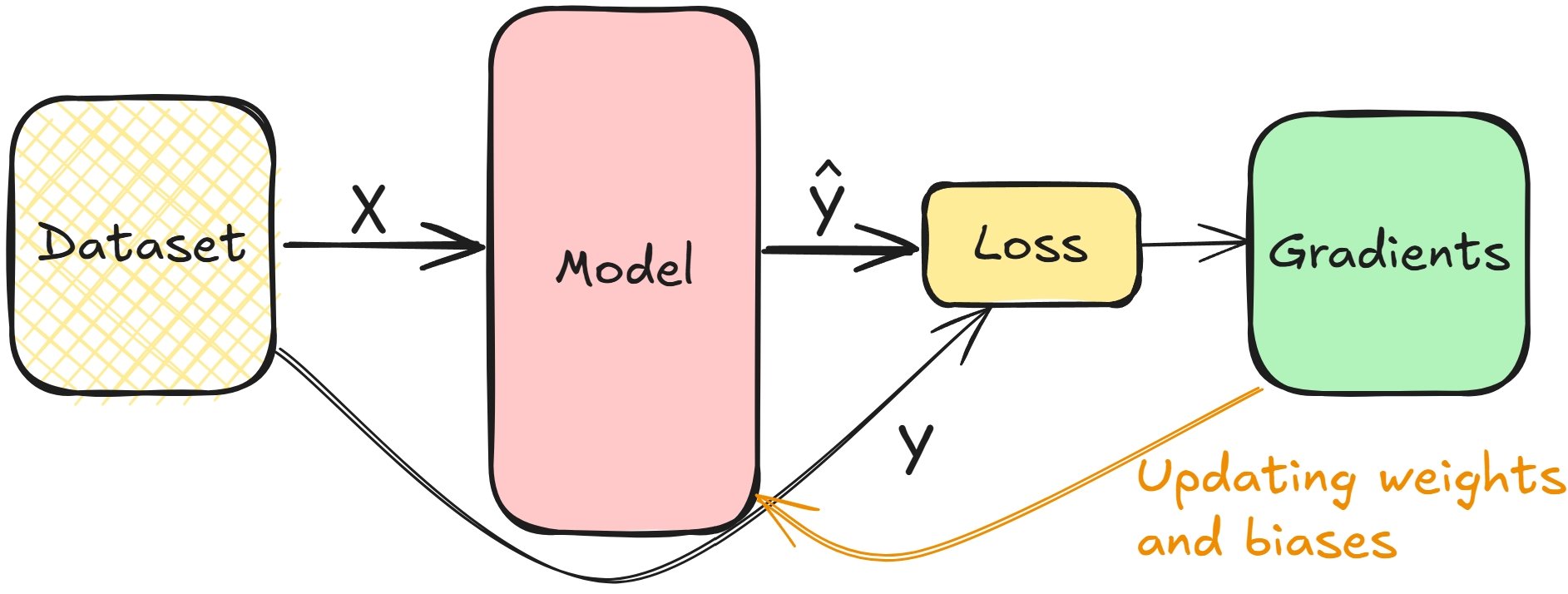
Connecting derivatives and model training
- Compute the loss in the forward pass during training
$$
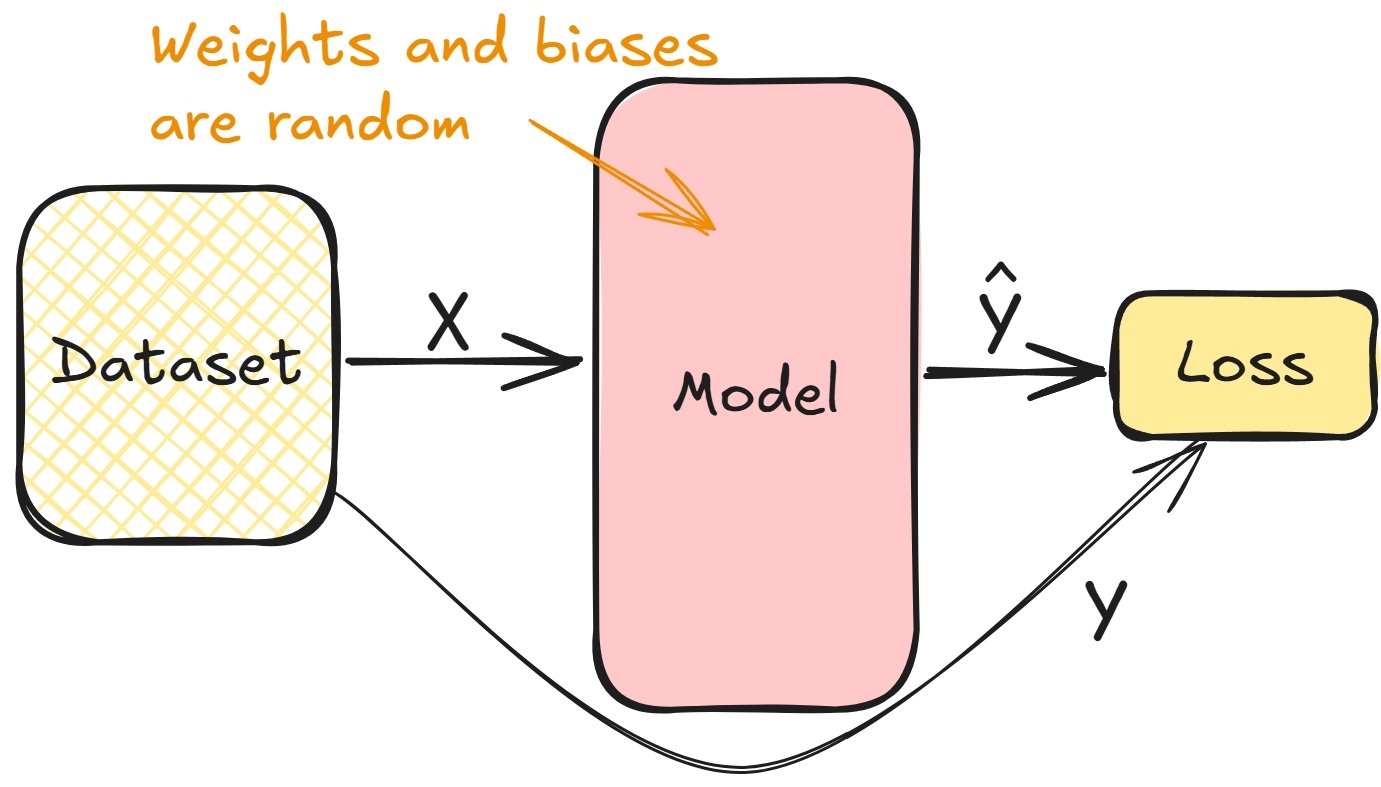
Connecting derivatives and model training
- Gradients help minimize loss, tune layer weights and biases
- Repeat until the layers are tuned
$$
Backpropagation concepts