Why transform existing features?
Feature Engineering in R

Jorge Zazueta
Research Professor. Head of the Modeling Group at the School of Economics, UASLP
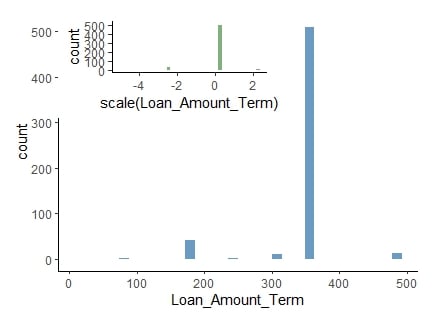
Log transformation
log-transformed loan amount data
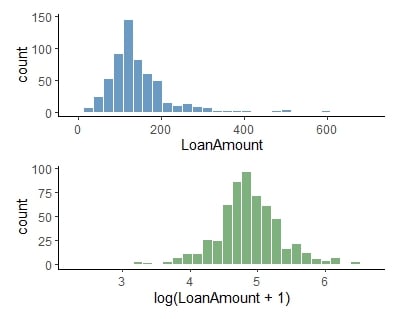
Normalization
e.g., loan amount term values shown vary significantly
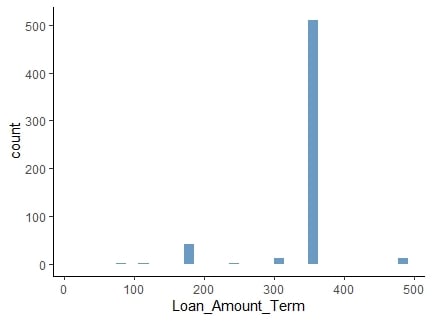
Normalization
Normalized values preserve distribution, but contain variation.