Putting it all together
Feature Engineering in R

Jorge Zazueta
Research Professor. Head of the Modeling Group at the School of Economics, UASLP
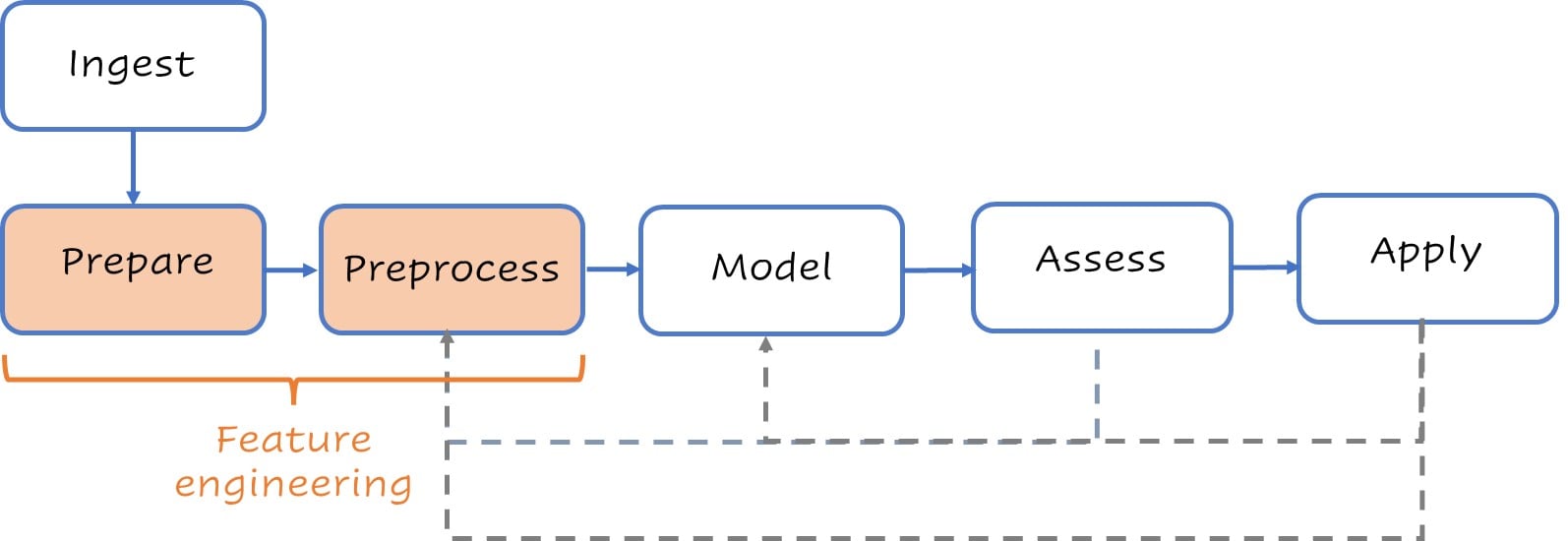
A stylized process modeling flow
Typical high-level modeling steps.
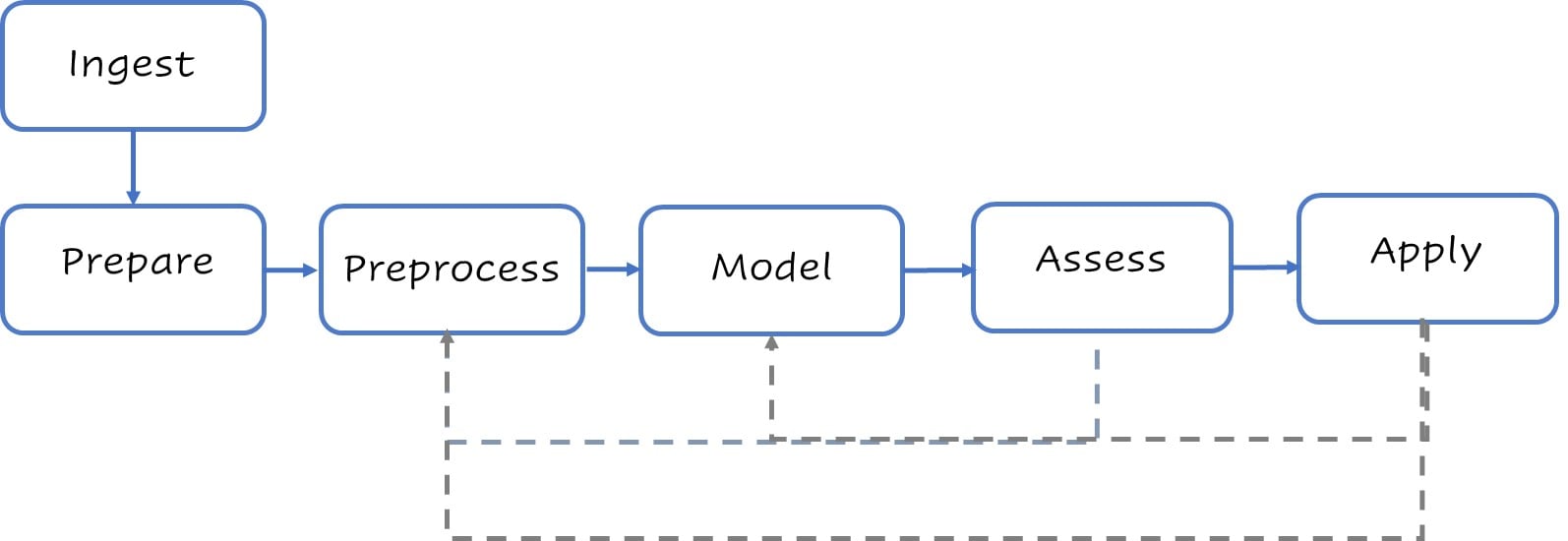
A stylized process modeling flow
Typical high-level modeling steps.
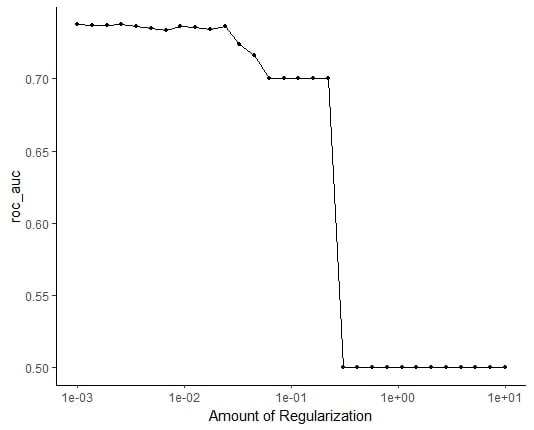
Assess
ROC_AUC vs. Regularization