Reducing dimensionality
Feature Engineering in R

Jorge Zazueta
Research Professor and Head of the Modeling Group at the School of Economics, UASLP
Zero variance features
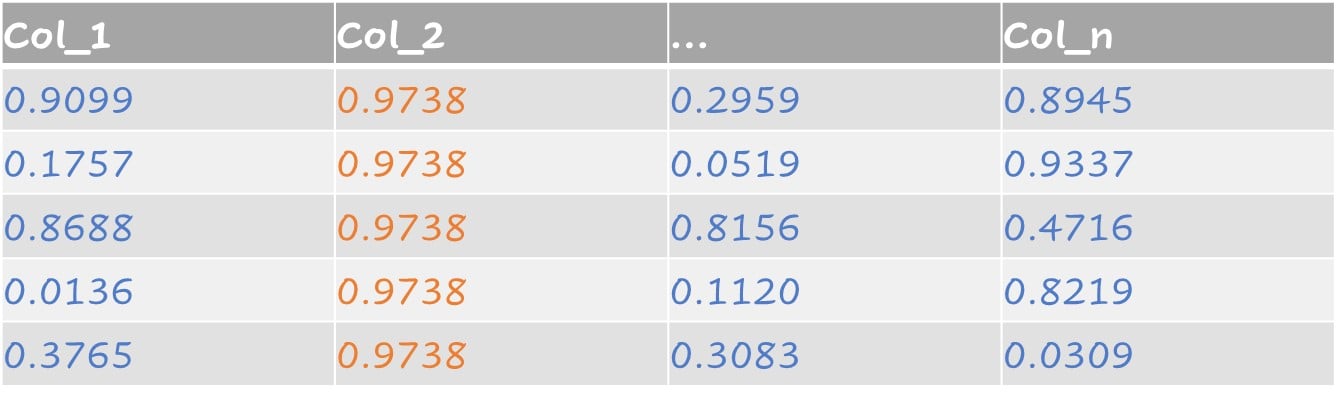
Principal Component Analysis (PCA)
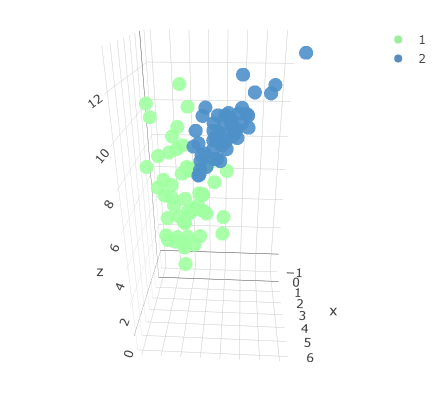
Original three-dimensional dataset with two associated classes.
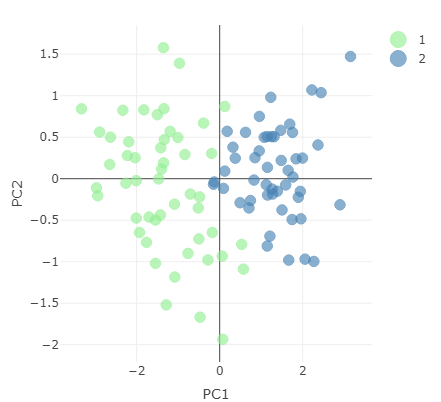
Reduced dataset representing data using first two principal components.
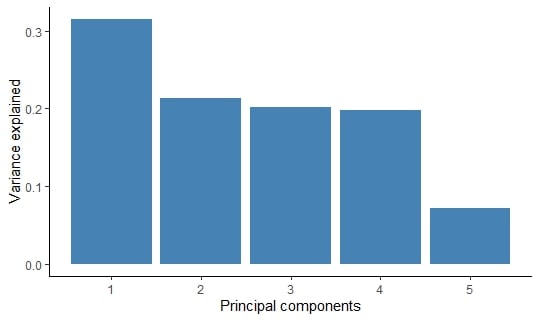
Visualizing variance explained
Variance explained by principal component.