Wrap-up
Natural Language Processing with spaCy

Azadeh Mobasher
Principal data scientist
Chapter 1 - Introduction to NLP and spaCy
- Use
spaCy's text processing pipelines to extract linguistic features:

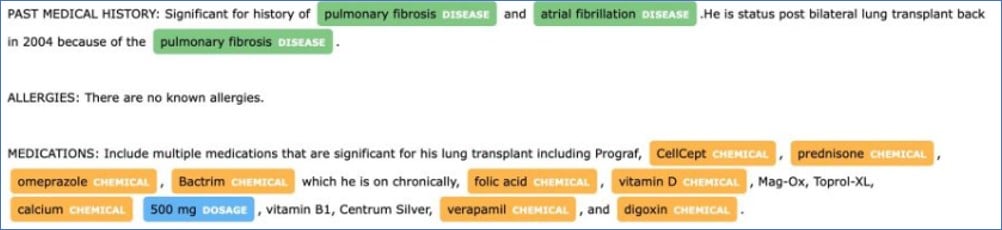
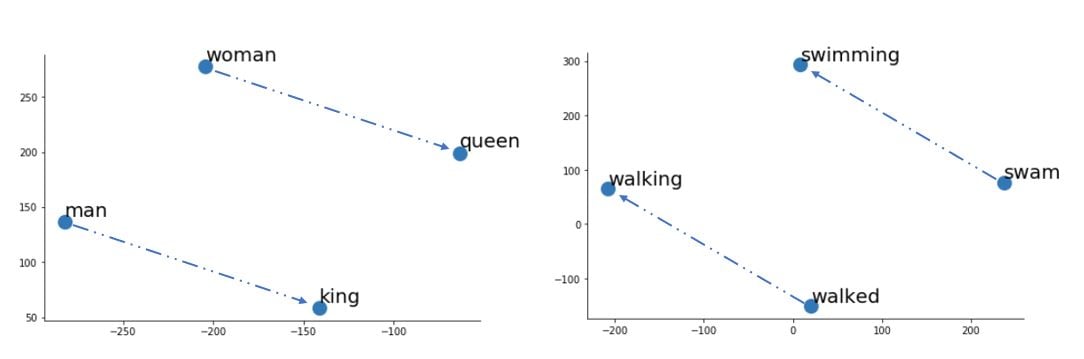
Chapter 2 - spaCy linguistic annotations and word vectors
- Work with
spaCy's classes such asDoc,TokenandSpanand predict semantic similarities using word vectors:
Chapter 4 - Customizing spaCy models
- Annotate and prepare our data for training
- Train
spaCymodels and use them at inference time