Measuring semantic similarity with spaCy
Natural Language Processing with spaCy

Azadeh Mobasher
Principal Data Scientist
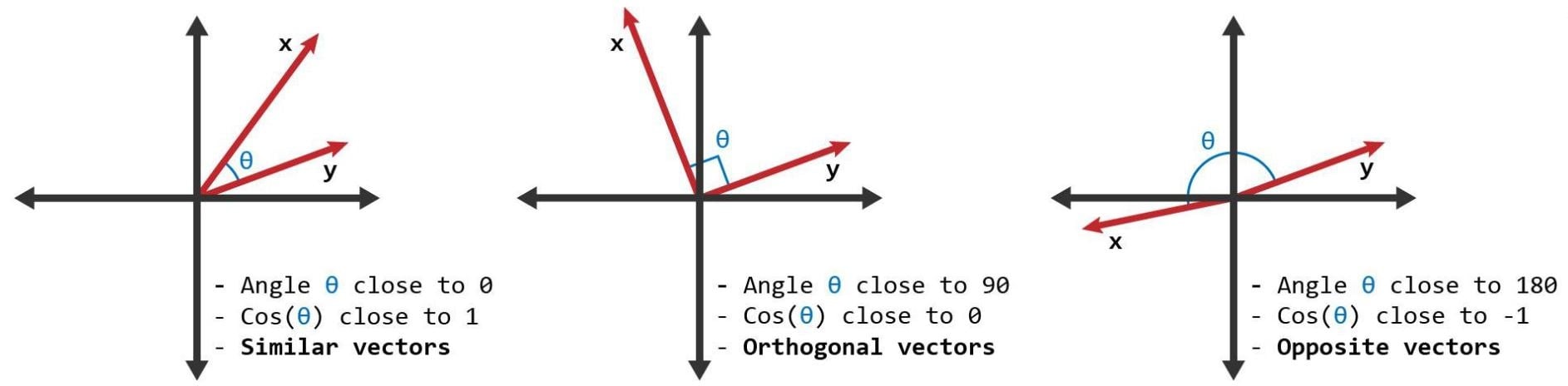
Similarity score
- A metric defined over texts
- To measure similarity use Cosine similarity and word vectors
- Cosine similarity is any number between 0 and 1