Advanced foreach operations
Parallel Programming in R

Nabeel Imam
Data Scientist
The case of the enormous CSV
df <- read.csv("very_large.csv")
Error: cannot allocate vector of size 6286.7 Mb
In addition: There were 12 warnings (use warnings() to see them)
Iterators are it
library(iterators) it <- ireadLines("very_large.csv")nextElem(it)
"\"\",\"Date\",\"Price\",\"Company\""
nextElem(it)
[1] "\"1\",\"2015-01-02\",312.579987,\"Amazon\""
nextElem(it)
[1] "\"2\",\"2015-01-05\",307.01001,\"Amazon\""
- Read first line in CSV
- And the next
- And so on...
Iterators with foreach
foreach(line = ireadLines("very_large.csv"),
.combine = "rbind") %do% {
if (grepl("Tesla", line)) return(line)
}
result.2 "\"2011-01-03\",5.368,\"Tesla\""
result.3 "\"2011-01-04\",5.332,\"Tesla\""
result.4 "\"2011-01-05\",5.296,\"Tesla\""
result.5 "\"2011-01-06\",5.366,\"Tesla\""
result.6 "\"2011-01-07\",5.6,\"Tesla\""
...
%dopar% the CSV
cl <- makeCluster(4) registerDoParallel(cl)foreach(line = ireadLines("very_large.csv"), .combine = "rbind") %dopar% {if (grepl("Tesla", line)) {return( strsplit(gsub("\"", "", line), ",")[[1]] ) } } stopCluster(cl)
[,1] [,2] [,3]
result.2 "2011-01-03" "5.368" "Tesla"
result.3 "2011-01-04" "5.332" "Tesla"
result.4 "2011-01-05" "5.296" "Tesla"
result.5 "2011-01-06" "5.366" "Tesla"
result.6 "2011-01-07" "5.6" "Tesla"
...
Stock prices
head(df_stocks)
Amazon Apple Facebook Google Microsoft Netflix Tesla Uber Walmart Zoom
2015-01-02 312.58 27.8475 78.58 527.5616 46.66 49.15143 44.574 NA 86.27 NA
2015-01-05 307.01 27.0725 77.98 521.8273 46.37 49.25857 42.910 NA 85.72 NA
2015-01-06 302.24 26.6350 77.23 513.5900 46.38 47.34714 42.012 NA 85.98 NA
2015-01-07 297.50 26.8000 76.76 505.6118 45.98 47.34714 42.670 NA 86.78 NA
2015-01-08 300.32 27.3075 76.74 496.6265 46.75 47.12000 42.562 NA 89.21 NA
2015-01-09 301.48 28.1675 78.20 503.3780 47.61 47.63143 41.784 NA 90.32 NA
...
Three-day moving average
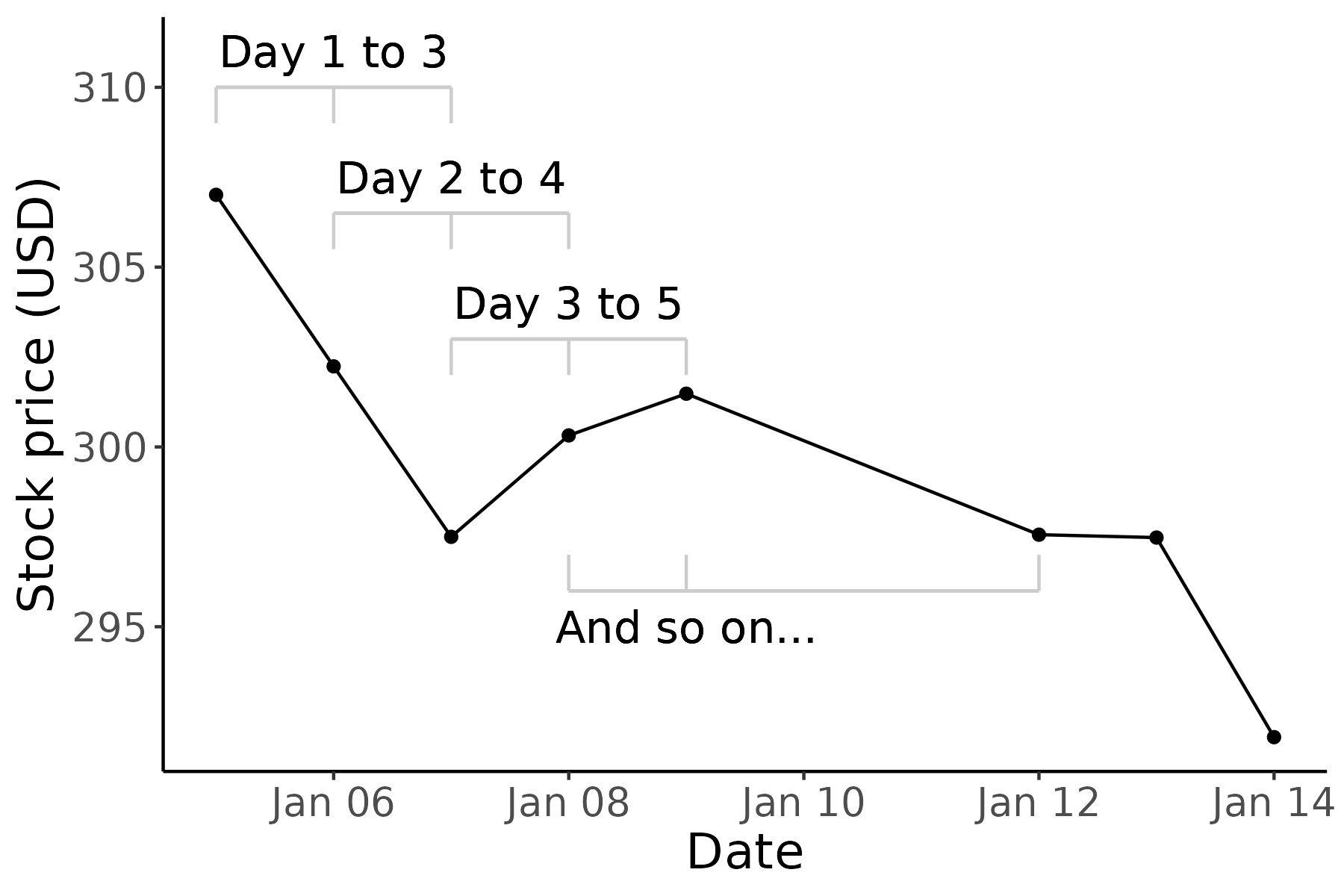
Three-day moving average for Tesla stock
df_tesla <- df_stocks %>%
dplyr::select(Tesla)
n_rows <- nrow(df_tesla) - 2
cl <- makeCluster(4) registerDoParallel(cl)tesla_ma3 <- foreach(row = 1:n_rows) %dopar% {mean(df_tesla$Tesla[row:(row + 2)]) } stopCluster(cl)
print(tesla_ma3)
[[1]]
[1] 43.16533
[[2]]
[1] 42.53067
[[3]]
[1] 42.41467
[[4]]
[1] 42.33867
...
Moving average for all columns
head(df_stocks)
Amazon Apple Facebook Google Microsoft Netflix Tesla Uber Walmart Zoom
2015-01-02 312.58 27.8475 78.58 527.5616 46.66 49.15143 44.574 NA 86.27 NA
2015-01-05 307.01 27.0725 77.98 521.8273 46.37 49.25857 42.910 NA 85.72 NA
2015-01-06 302.24 26.6350 77.23 513.5900 46.38 47.34714 42.012 NA 85.98 NA
2015-01-07 297.50 26.8000 76.76 505.6118 45.98 47.34714 42.670 NA 86.78 NA
2015-01-08 300.32 27.3075 76.74 496.6265 46.75 47.12000 42.562 NA 89.21 NA
2015-01-09 301.48 28.1675 78.20 503.3780 47.61 47.63143 41.784 NA 90.32 NA
- Loop over all columns
- Within each column iteration, loop over rows
Nested loops
n_rows <- nrow(df_stocks) - 2 n_cols <- ncol(df_stocks)cl <- makeCluster(4) registerDoParallel(cl)# Iterate over columns moving_avg <- foreach(col = 1:n_cols,.combine = "cbind") %:%# Iterate over rows foreach(row = 1:n_rows,.combine = "c") %dopar% {# Average from day n to n + 2 (3-days) mean(df_stocks[row:(row + 2), col]) } stopCluster(cl)
- Get dimensions to iterate over
- Set up the cluster
- Nest loops with
%:%
- Use
%dopar%for the inner-most loop; supplyc()to combine results into a vector
Moving averages
head(moving_avg)
result.1 result.2 result.3 result.4 result.5 result.6 result.7 ...
[1,] 307.2767 27.18500 77.93000 520.9930 46.47000 48.58571 43.16533 ...
[2,] 302.2500 26.83583 77.32334 513.6764 46.24333 47.98428 42.53067 ...
[3,] 300.0200 26.91417 76.91000 505.2761 46.37000 47.27143 42.41467 ...
[4,] 299.7667 27.42500 77.23333 501.8721 46.78000 47.36619 42.33867 ...
[5,] 299.7867 27.87500 77.59333 497.8631 47.26000 47.28048 41.65200 ...
[6,] 298.8400 28.05833 77.75667 498.1457 47.33333 46.91428 41.01933 ...
...
Let's practice!
Parallel Programming in R

