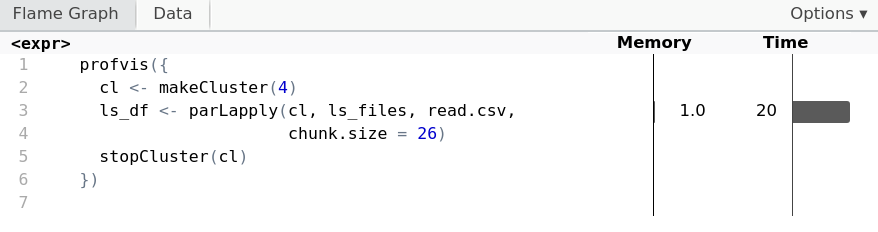
Monitoring and managing memory
Parallel Programming in R

Nabeel Imam
Data Scientist
The queue and the space

The parallel flow

The parallel flow

Profiling with two workers

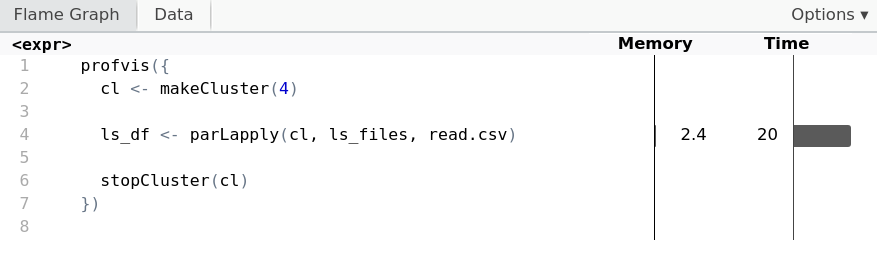
Profiling with four workers
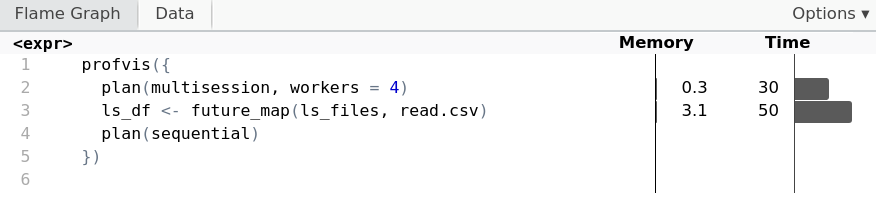
Behind the scenes
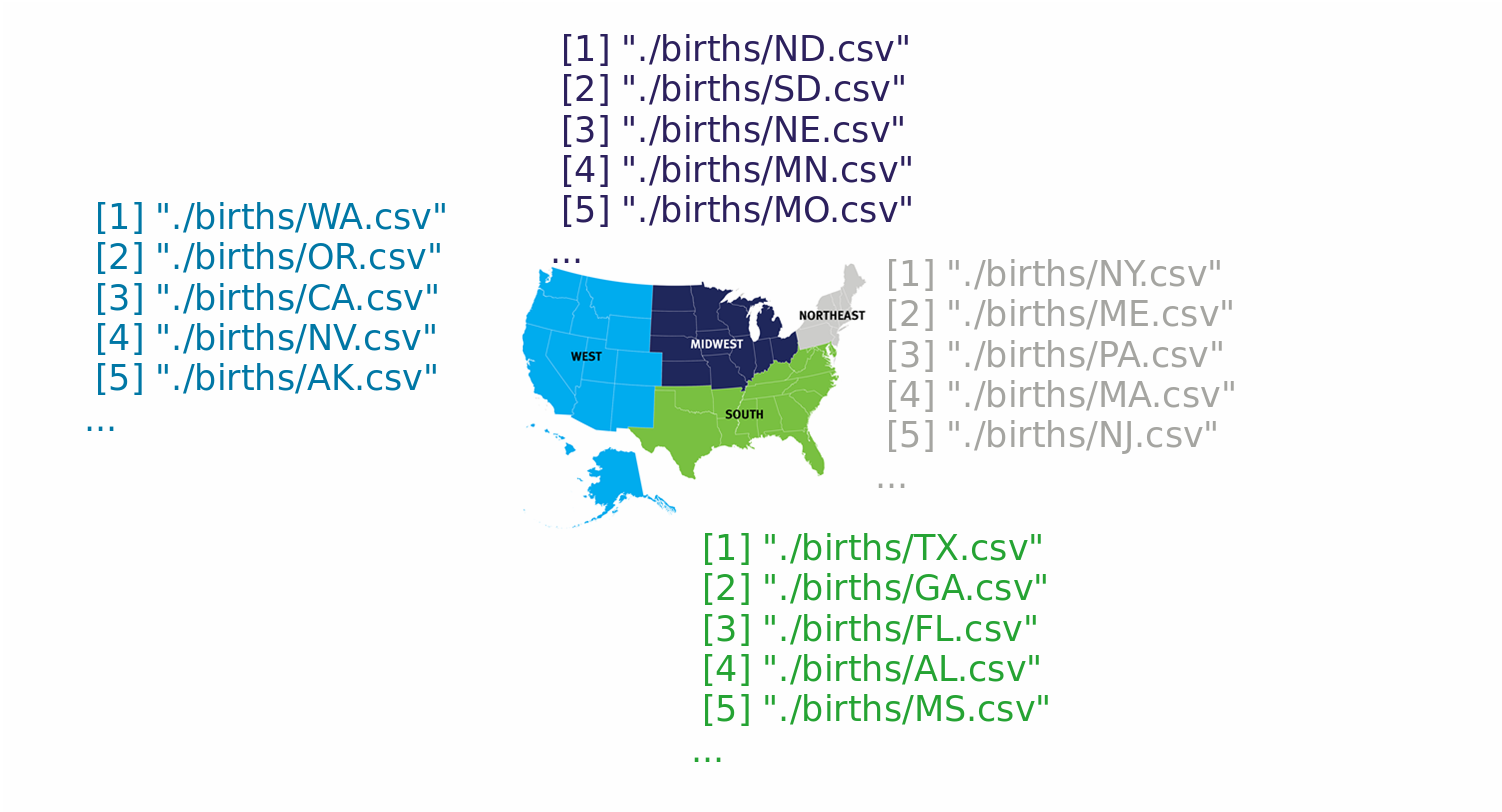
Managing memory by chunking
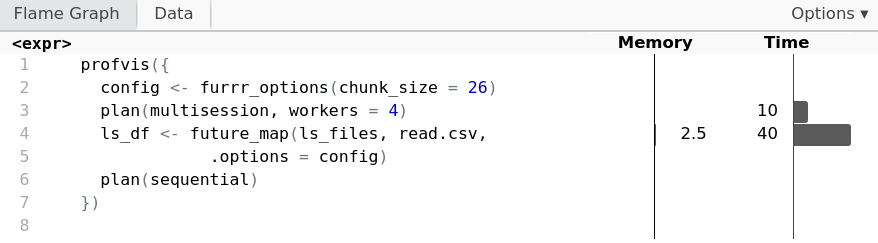
Chunking with parallel
Chunking with parallel
cl <- makeCluster(4) ls_df <- parLapply(cl, ls_files, read.csv,chunk.size = 26)stopCluster(cl)