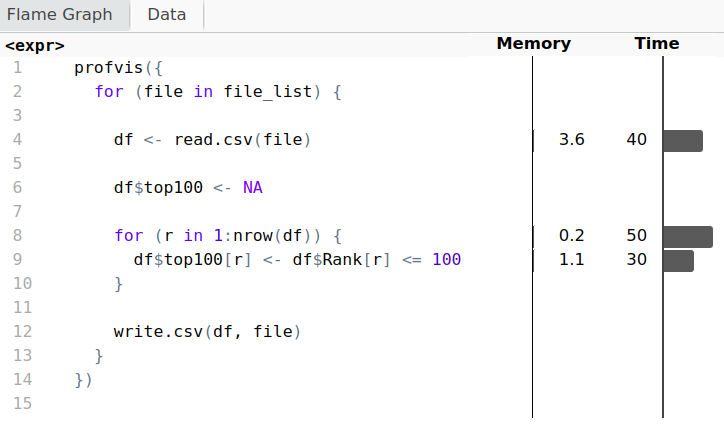
A practical example
The data
print(file_list)
[1] "./uni_data_country/Argentina.csv"
[2] "./uni_data_country/Armenia.csv"
[3] "./uni_data_country/Australia.csv"
[4] "./uni_data_country/Austria.csv"
[5] "./uni_data_country/Azerbaijan.csv"
[6] "./uni_data_country/Bahrain.csv"
[7] "./uni_data_country/Bangladesh.csv"
[8] "./uni_data_country/Belarus.csv"
[9] "./uni_data_country/Belgium.csv"
[10] "./uni_data_country/Bolivia.csv"
...