Overview of Text Classification
Deep Learning for Text with PyTorch

Shubham Jain
Instructor
Text classification defined
- Assigning labels to text
- Giving meaning to words and sentences
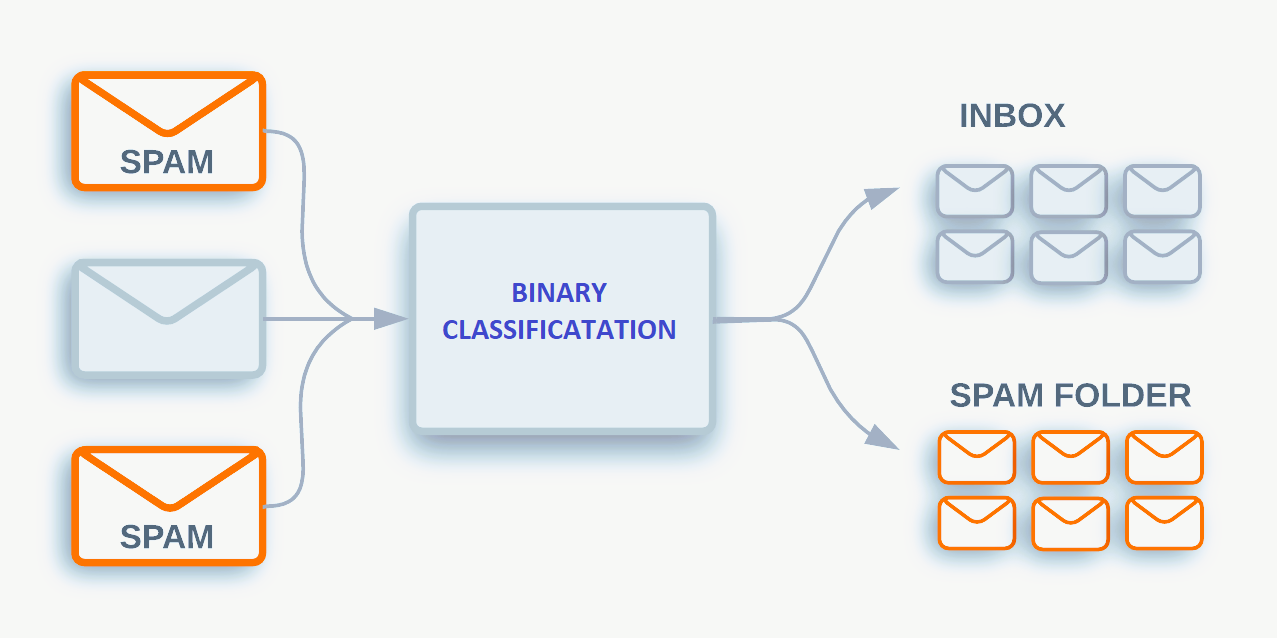
Binary classification
1 https://storage.googleapis.com/gweb-cloudblog-publish/images/image4_v2LFcq0.max-1200x1200.png
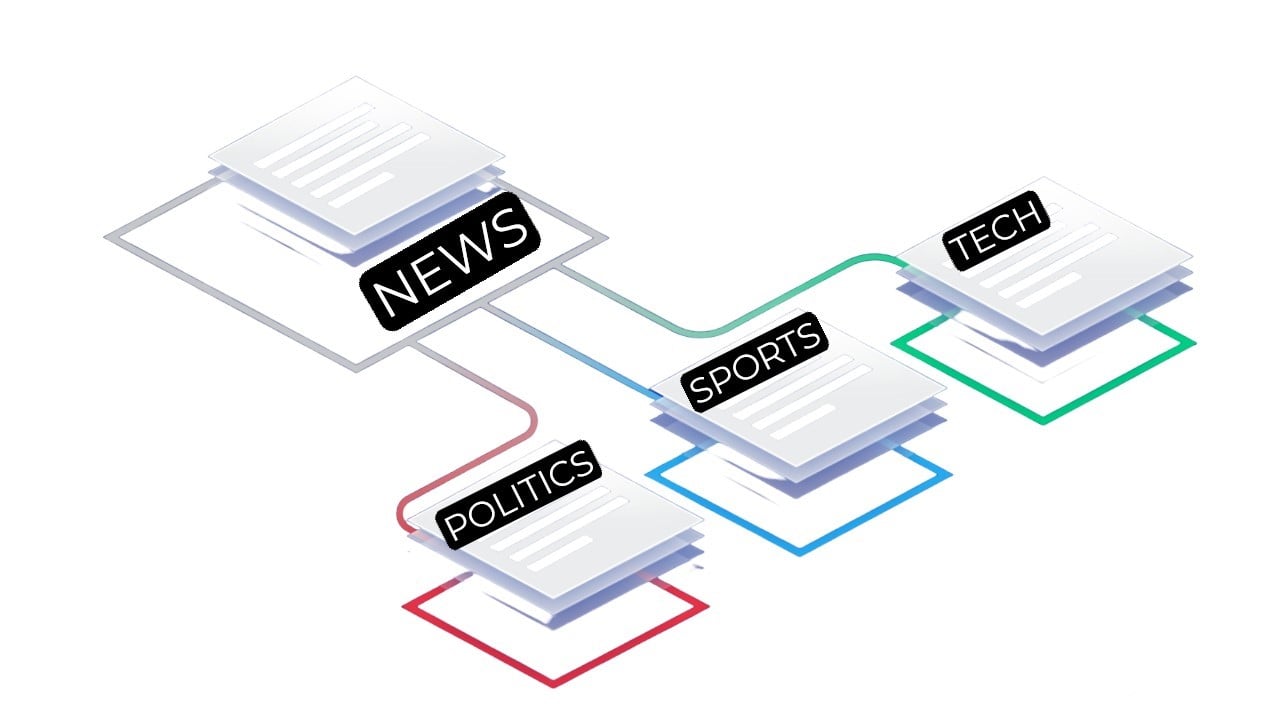
Multi-class classification
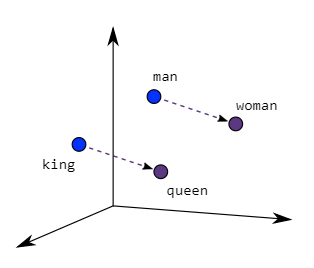
What are word embeddings