Encoding text data
Deep Learning for Text with PyTorch

Shubham Jain
Data Scientist
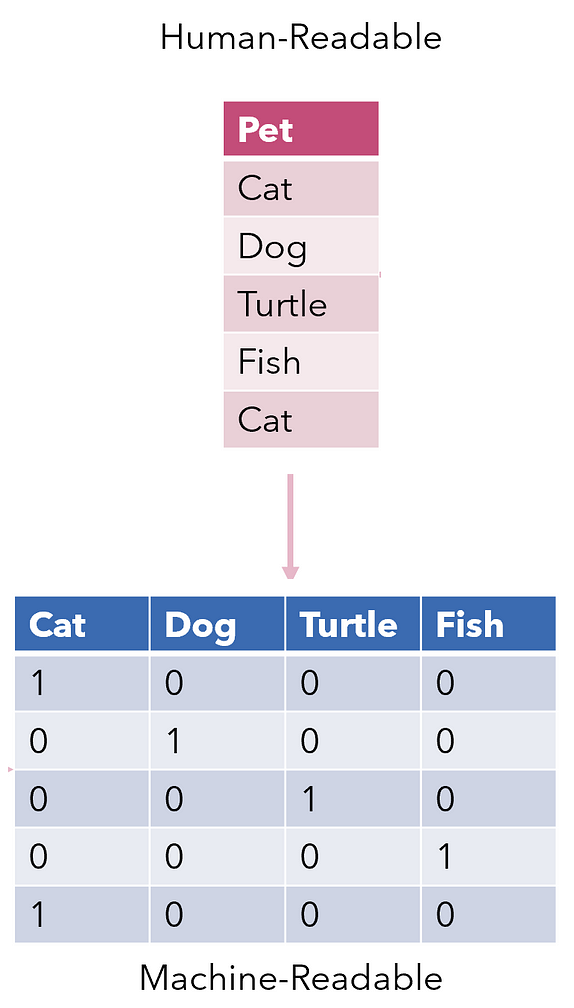
Text encoding

- Convert text into machine-readable numbers
- Enable analysis and modeling
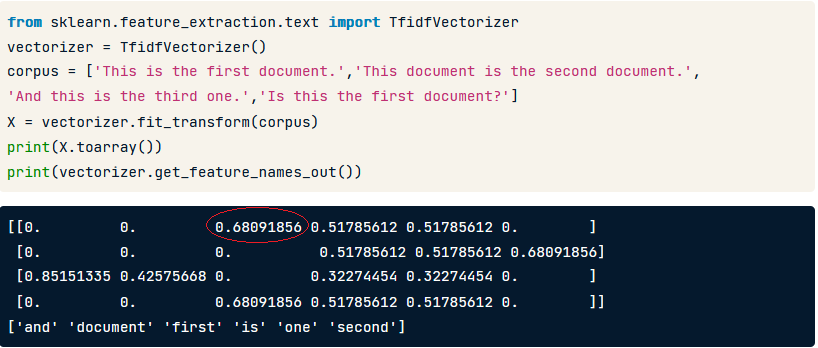
TfidfVectorizer
Deep Learning for Text with PyTorch
Shubham Jain
Data Scientist

