Convolutional neural networks for text classification
Deep Learning for Text with PyTorch

Shubham Jain
Instructor
The convolution operation
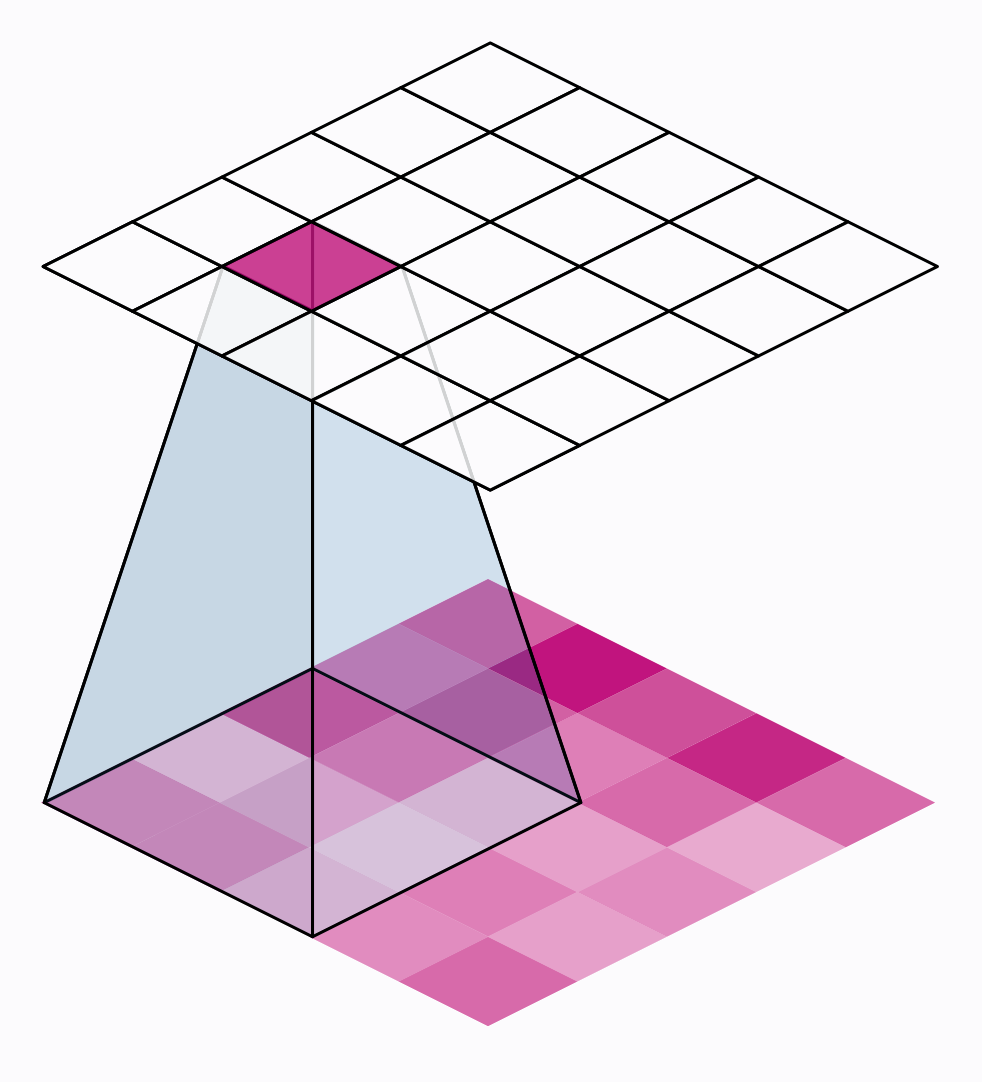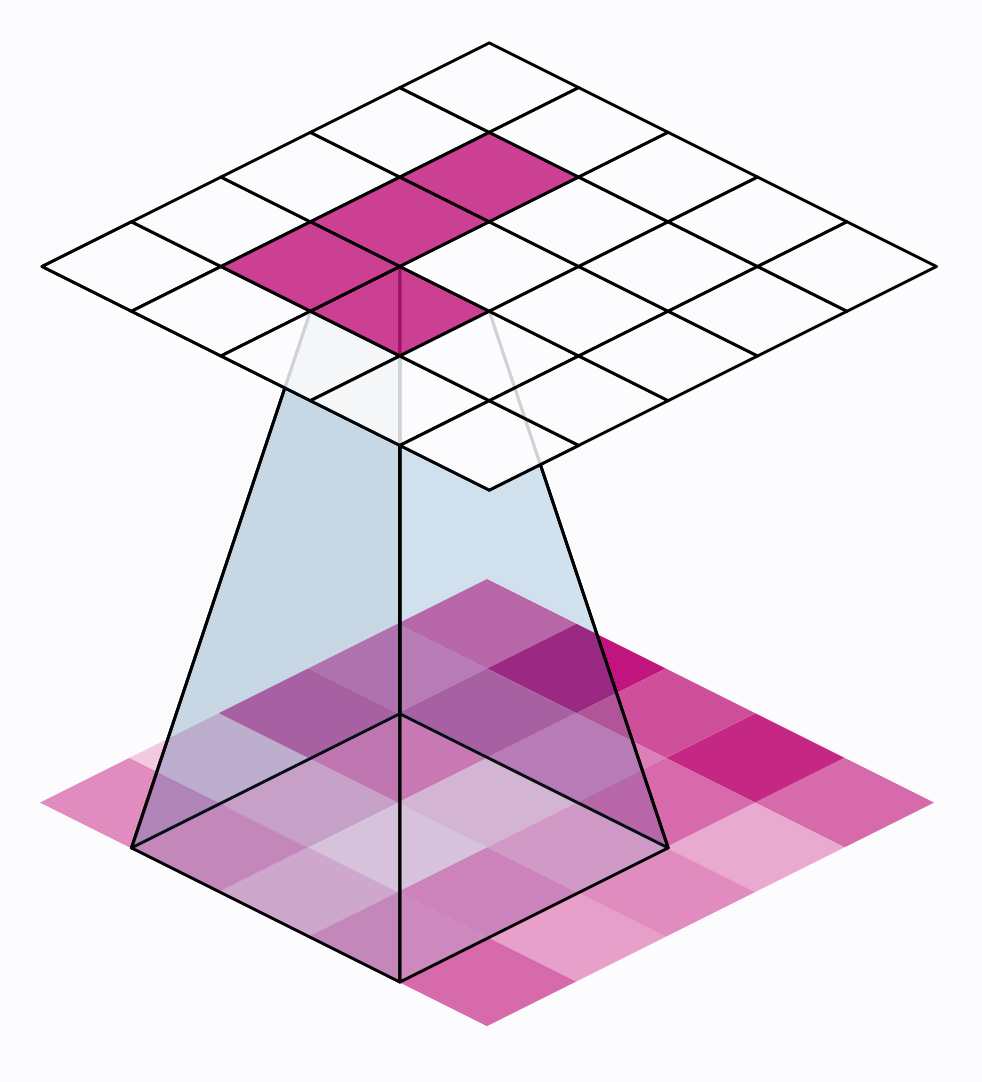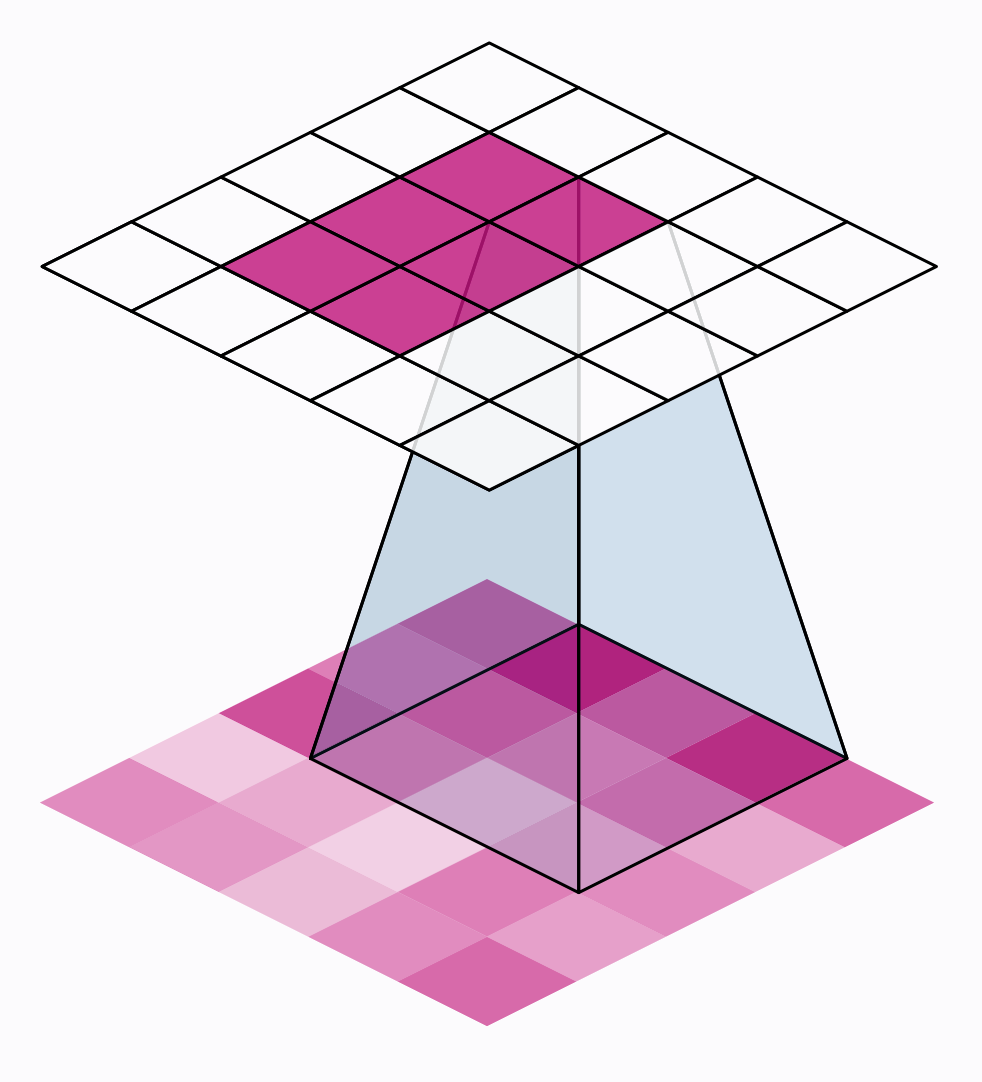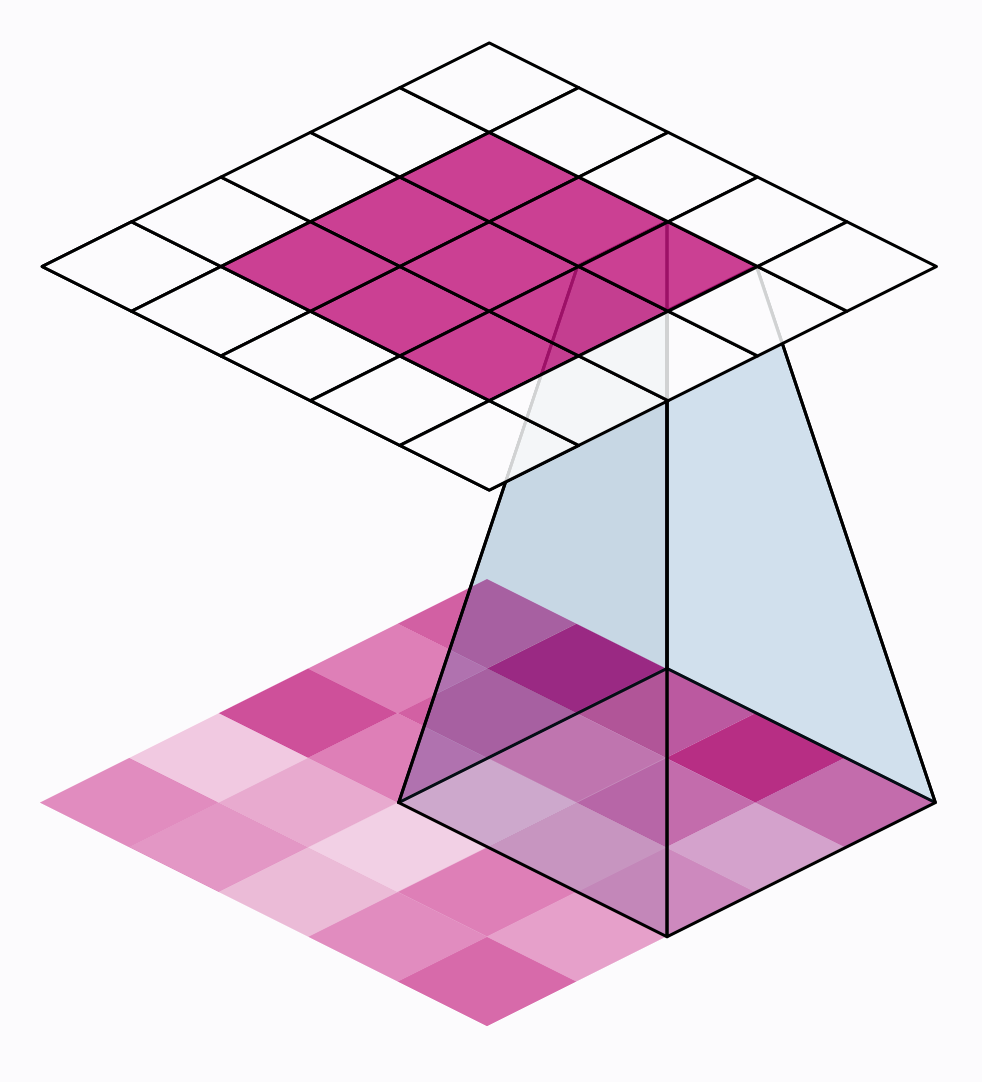
1 Animation from Vincent Dumoulin, Francesco Visin
Filter and stride in CNNs
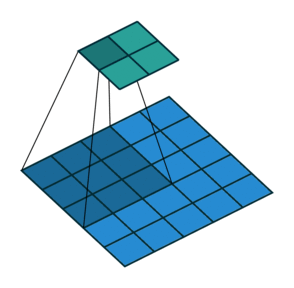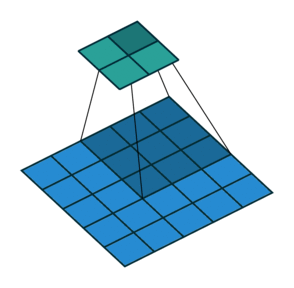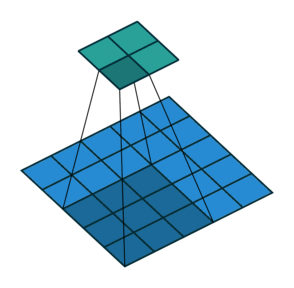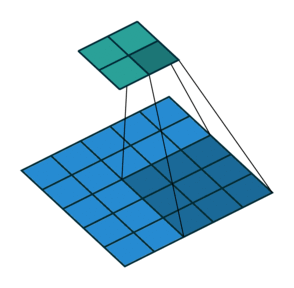
1 Animation from Vincent Dumoulin, Francesco Visin

