Adversarial attacks on text classification models
Deep Learning for Text with PyTorch

Shubham Jain
Instructor
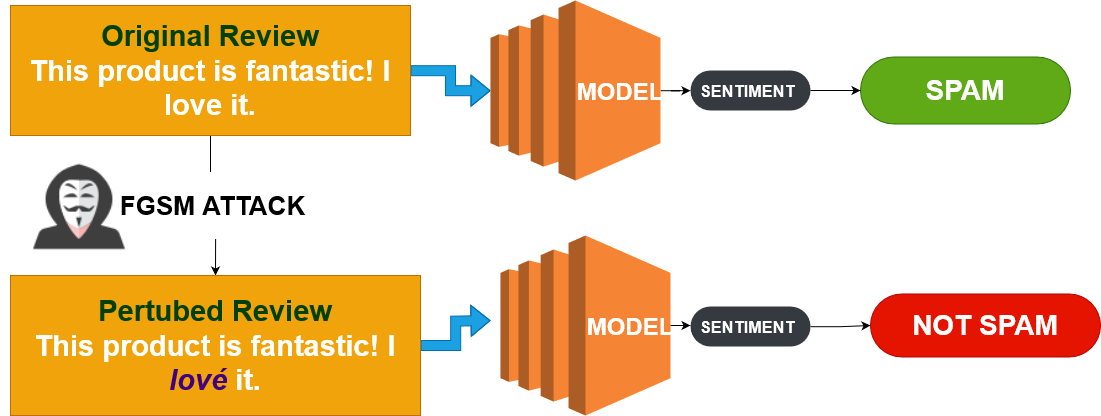
Fast Gradient Sign Method (FGSM)
- Exploits the model's learning information
- Makes the tiniest possible change to deceive the model
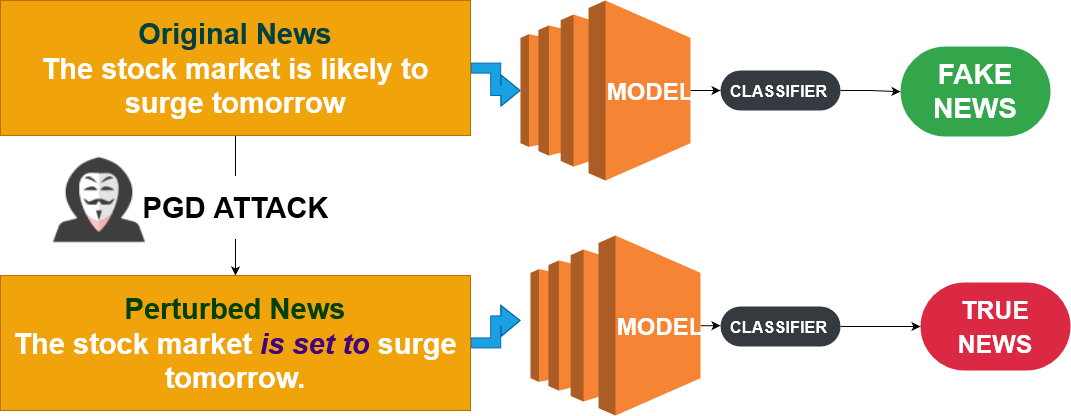
Projected Gradient Descent (PGD)
- More advanced than FGSM: it's iterative
- Tries to find the most effective disturbance
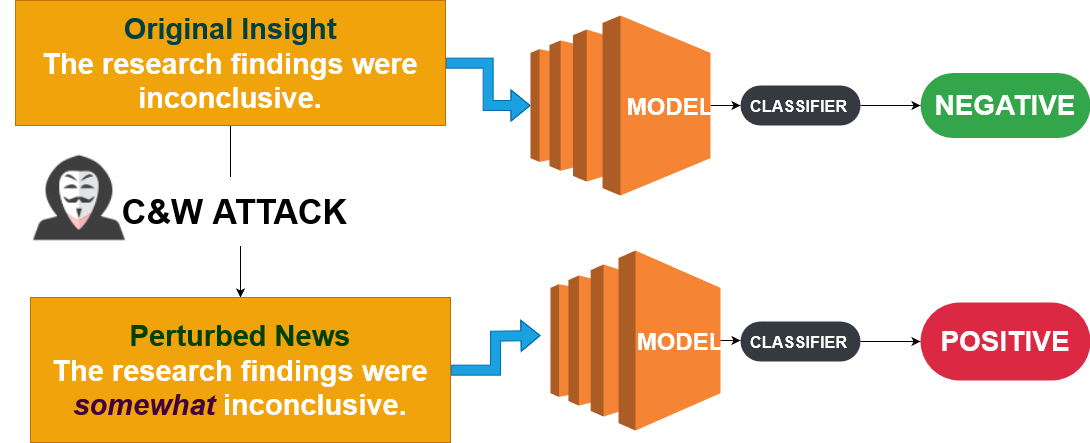
The Carlini & Wagner (C&W) attack
- Focuses on optimizing the loss function
- Not just about deceiving but about being undetectable
Building defenses: strategies
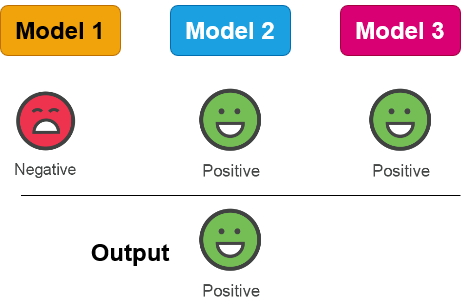
Building defenses: tools & techniques


1 https://adversarial-robustness-toolbox.readthedocs.io/en/latest/, https://stock.adobe.com/ie/contributor/209161356/designer-s-circle

