Feature engineering and selection
End-to-End Machine Learning

Joshua Stapleton
Machine Learning Engineer
Feature engineering
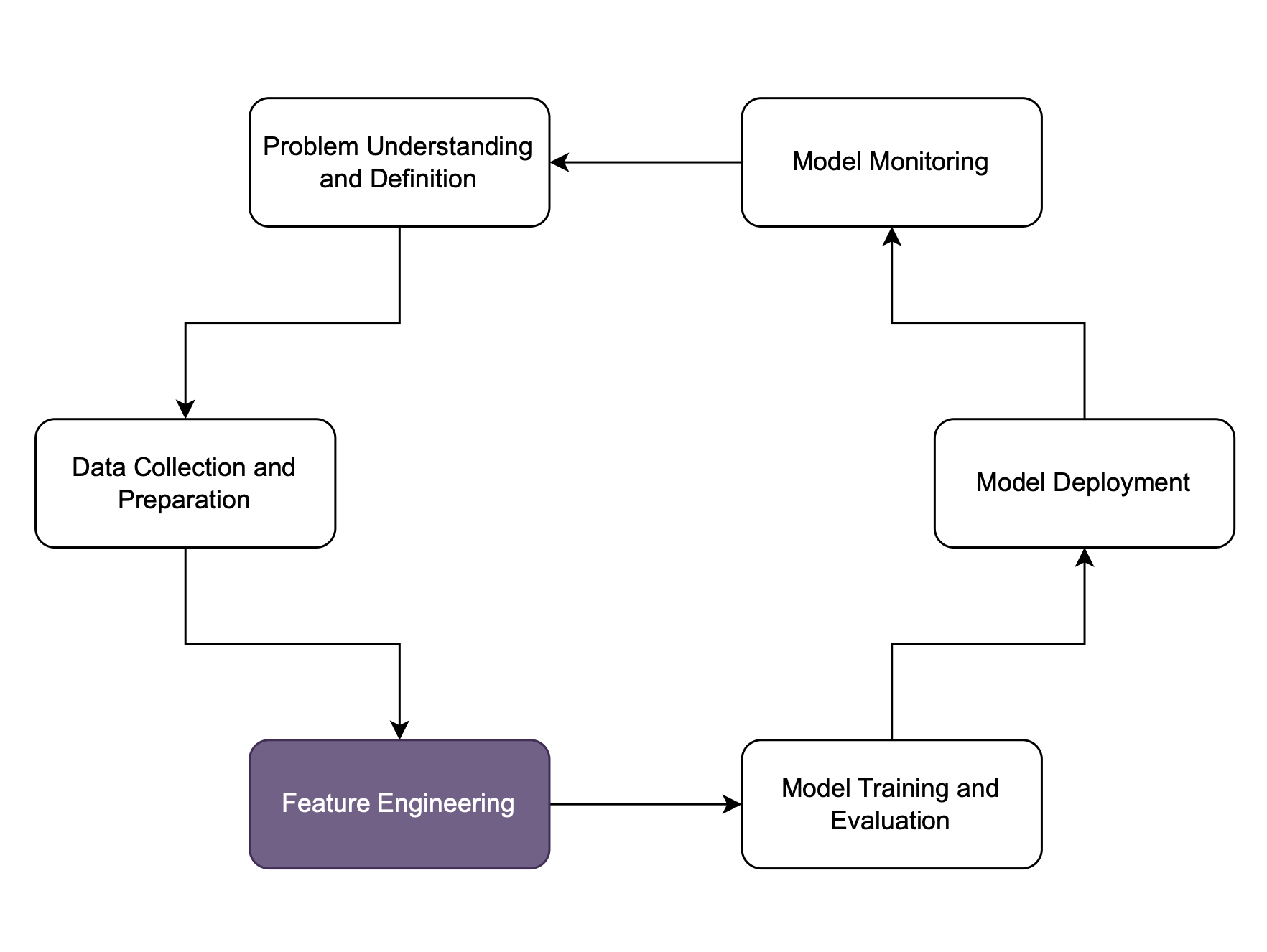
What constitutes a good feature?
- Use relevant features
- Weather on the day of patient appointment should have no bearing on diagnosis

- Use dissimilar (orthogonal) features
- Two features of age in months and age in years would not be helpful