Using Databricks for machine learning
Databricks Concepts

Kevin Barlow
Data Practitioner
Machine Learning Lifecycle
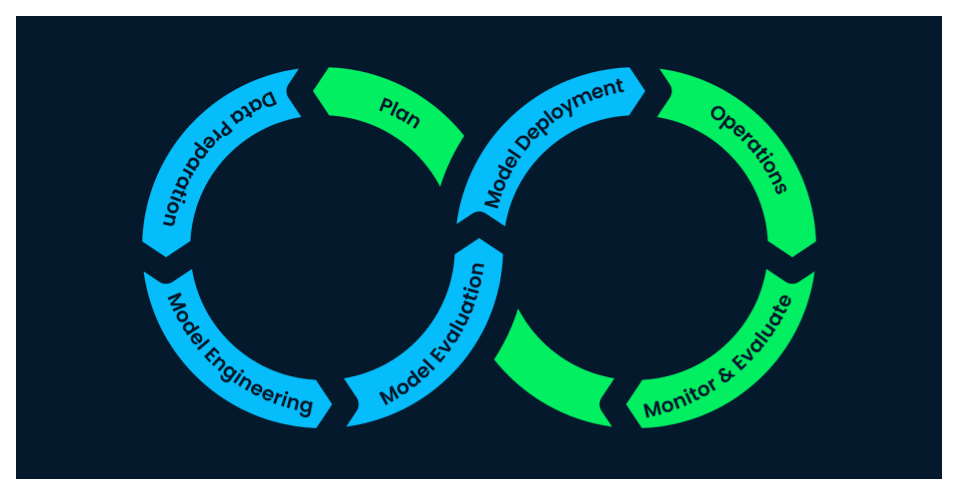
1 https://www.datacamp.com/blog/machine-learning-lifecycle-explained
Planning and preparation
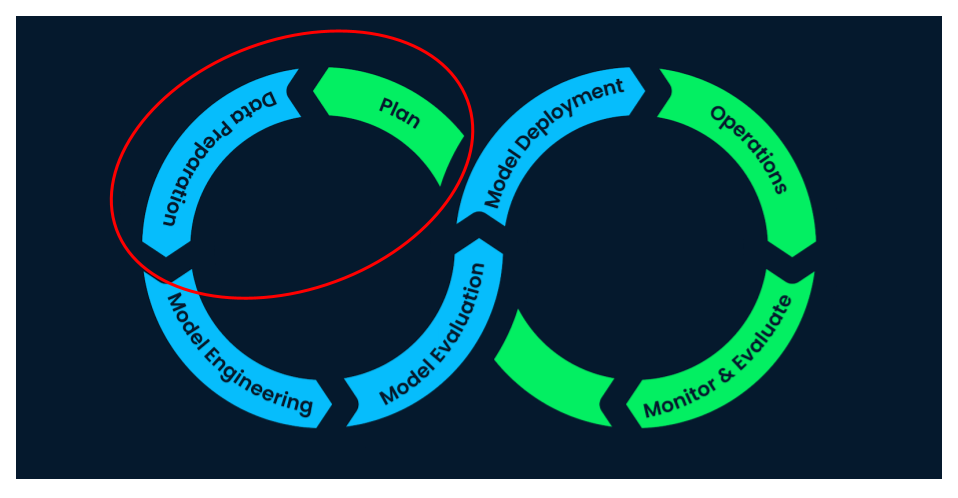
Planning for machine learning
What do I have?
- Data availability
- Business requirements
- Data scientists/data analysts

What do I want?
- Use cases
- Legal and security compliance
- Business outcomes

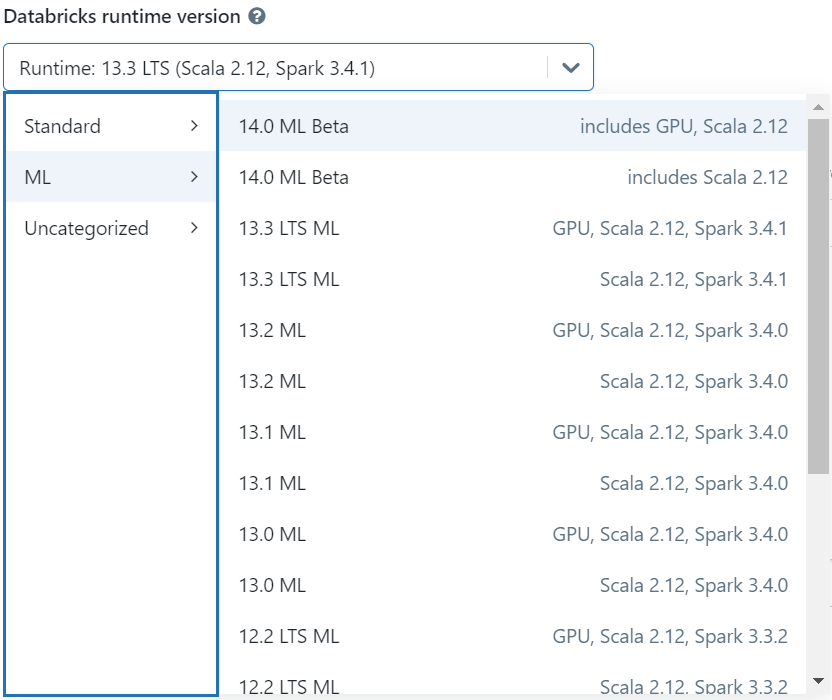
ML Runtime
Exploratory Data Analysis
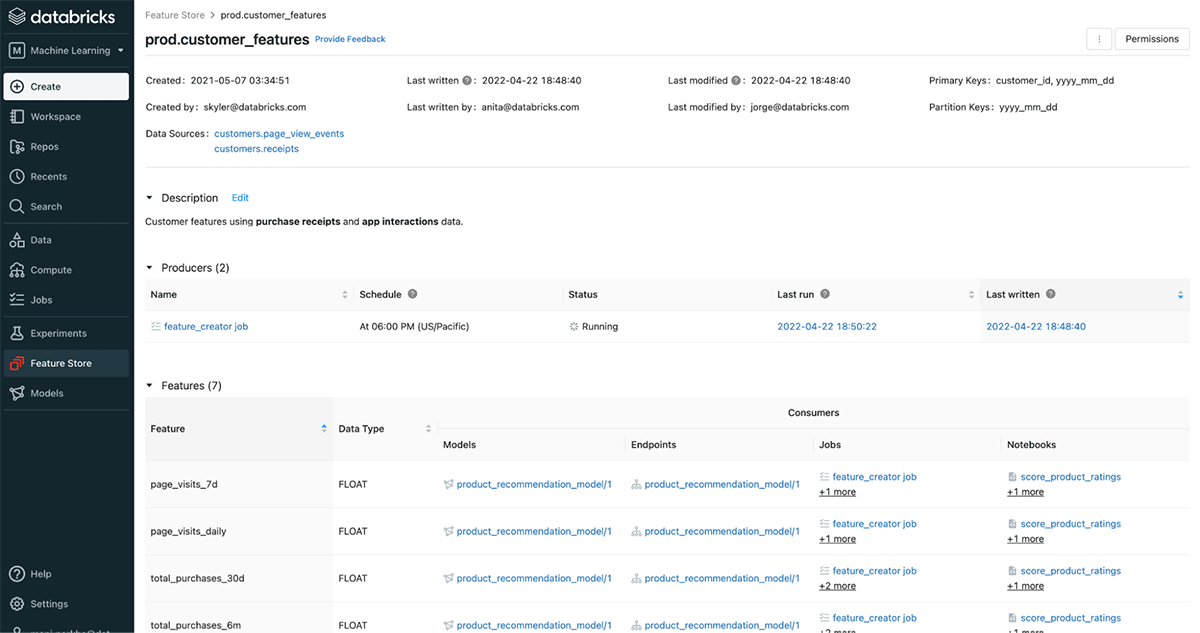
Databricks Feature Store
- Centralized storage for featurized datasets
- Easily discover and re-use features for machine learning models
- Upstream and downstream lineage