Creating vector databases with ChromaDB
Introduction to Embeddings with the OpenAI API

Emmanuel Pire
Senior Software Engineer, DataCamp
Installing ChromaDB
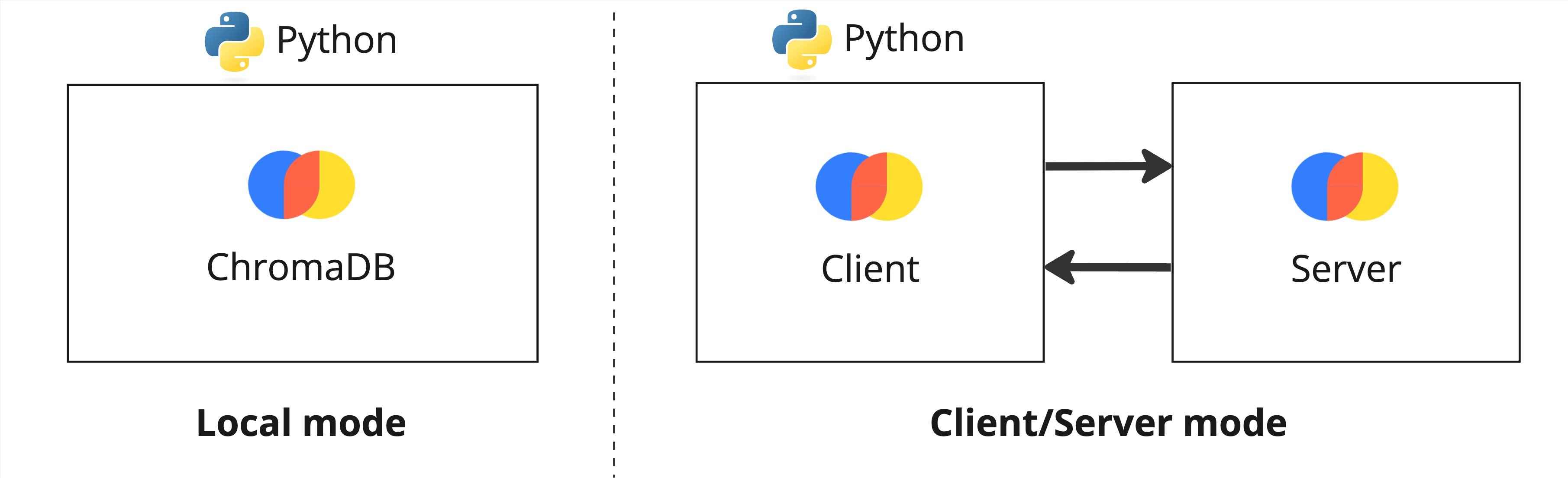
- ChromaDB is a simple yet powerful vector database
- Two flavors:
- Local: great for development and prototyping
- Client/Server: made for production