Investigating the vector space
Introduction to Embeddings with the OpenAI API

Emmanuel Pire
Senior Software Engineer, DataCamp
Example: Embedding headlines
articles = [
{"headline": "Economic Growth Continues Amid Global Uncertainty", "topic": "Business"},
{"headline": "Interest rates fall to historic lows", "topic": "Business"},
{"headline": "Scientists Make Breakthrough Discovery in Renewable Energy", "topic": "Science"},
{"headline": "India Successfully Lands Near Moon's South Pole", "topic": "Science"},
{"headline": "New Particle Discovered at CERN", "topic": "Science"},
{"headline": "Tech Company Launches Innovative Product to Improve Online Accessibility", "topic": "Tech"},
{"headline": "Tech Giant Buys 49% Stake In AI Startup", "topic": "Tech"},
{"headline": "New Social Media Platform Has Everyone Talking!", "topic": "Tech"},
{"headline": "The Blues get promoted on the final day of the season!", "topic": "Sport"},
{"headline": "1.5 Billion Tune-in to the World Cup Final", "topic": "Sport"}
]
Example: Embedding headlines

Embedding multiple inputs
headline_text = [article['headline'] for article in articles]
headline_text
["Economic Growth Continues Amid Global Uncertainty",
...,
"1.5 Billion Tune-in to the World Cup Final"]
response = client.embeddings.create(
model="text-embedding-3-small",
input=headline_text
)
response_dict = response.model_dump()
- Batching is more efficient than using multiple API calls
[...]
'data': [
{
"embedding": [-0.017142612487077713, ..., -0.0012911480152979493],
"index": 0,
"object": "embedding"
},
{
"embedding": [-0.032995883375406265, ..., -0.0028605300467461348],
"index": 1,
"object": "embedding"
},
...
]
[...]
Embedding multiple inputs
articles = [
{"headline": "Economic Growth Continues Amid Global Uncertainty", "topic": "Business"},
...
]
for i, article in enumerate(articles):article['embedding'] = response_dict['data'][i]['embedding']print(articles[:2])
[{'headline': 'Economic Growth Continues Amid Global Uncertainty',
'topic': 'Business',
'embedding': [-0.017142612487077713, ..., -0.0012911480152979493]}
{'headline': 'Interest rates fall to historic lows',
'topic': 'Business',
'embedding': [-0.032995883375406265, ..., -0.0028605300467461348]}]
How long is the embeddings vector?
- "Economic Growth Continues Amid Global Uncertainty"
len(articles[0]['embedding'])
1536
- "Tech Company Launches Innovative Product to Improve Accessibility"
len(articles[5]['embedding'])
1536
- Always returns 1536 numbers!
Dimensionality reduction and t-SNE
- Various techniques to reduce the number of dimensions
- t-SNE (t-distributed Stochastic Neighbor Embedding)
1 https://www.datacamp.com/tutorial/introduction-t-sne
Implementing t-SNE
from sklearn.manifold import TSNE import numpy as npembeddings = [article['embedding'] for article in articles]tsne = TSNE(n_components=2, perplexity=5)embeddings_2d = tsne.fit_transform(np.array(embeddings))
n_components: the resulting number of dimensionsperplexity: used by the algorithm, must be less than number of data points- Will result in information loss
1 https://www.datacamp.com/tutorial/introduction-t-sne
Visualizing the embeddings
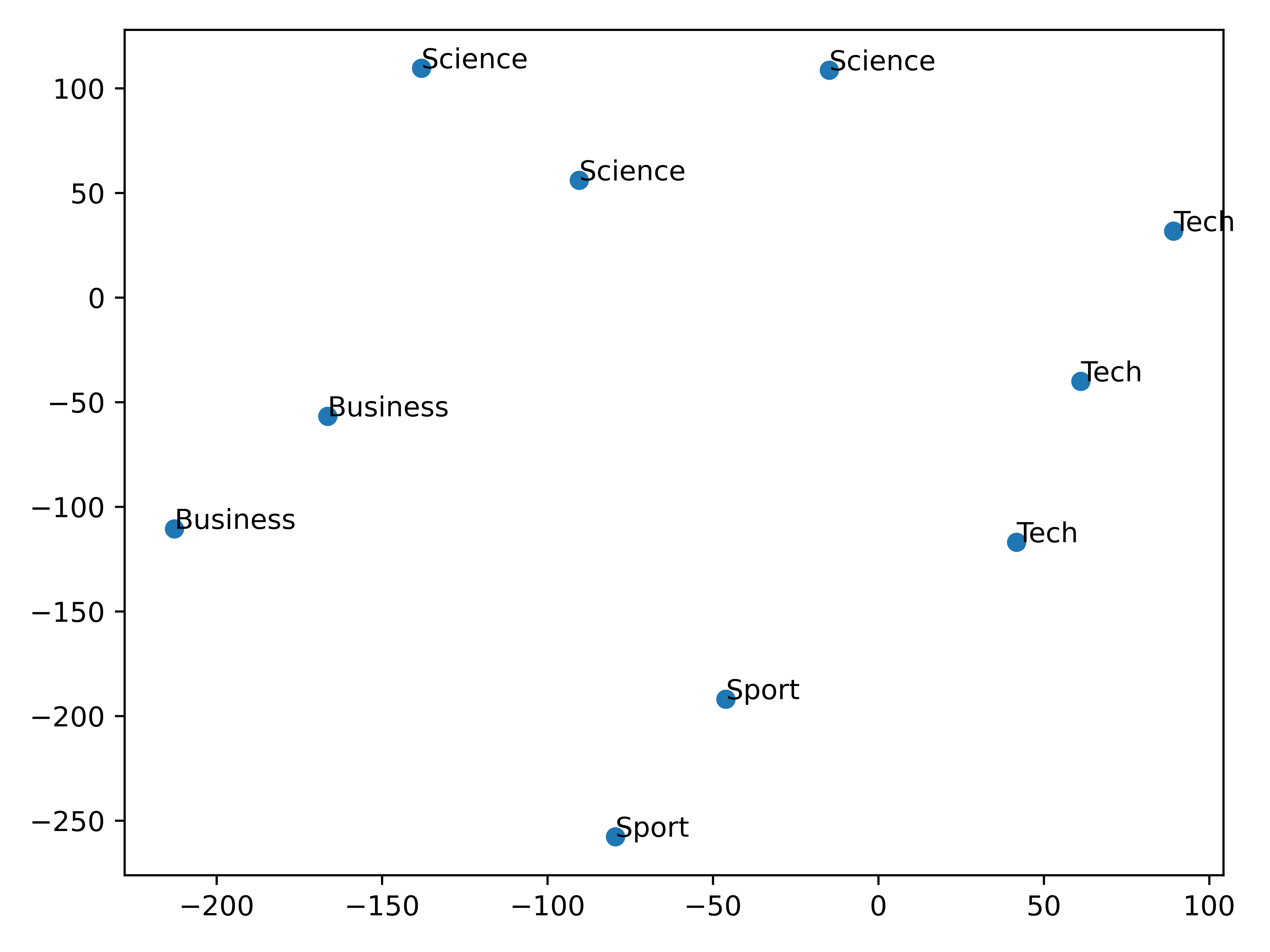
import matplotlib.pyplot as plt plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1])topics = [article['topic'] for article in articles] for i, topic in enumerate(topics): plt.annotate(topic, (embeddings_2d[i, 0], embeddings_2d[i, 1])) plt.show()
Visualizing the embeddings
- Similar articles are grouped together!
- Model captured the semantic meaning
- Coming up: Computing similarity
Let's practice!
Introduction to Embeddings with the OpenAI API

