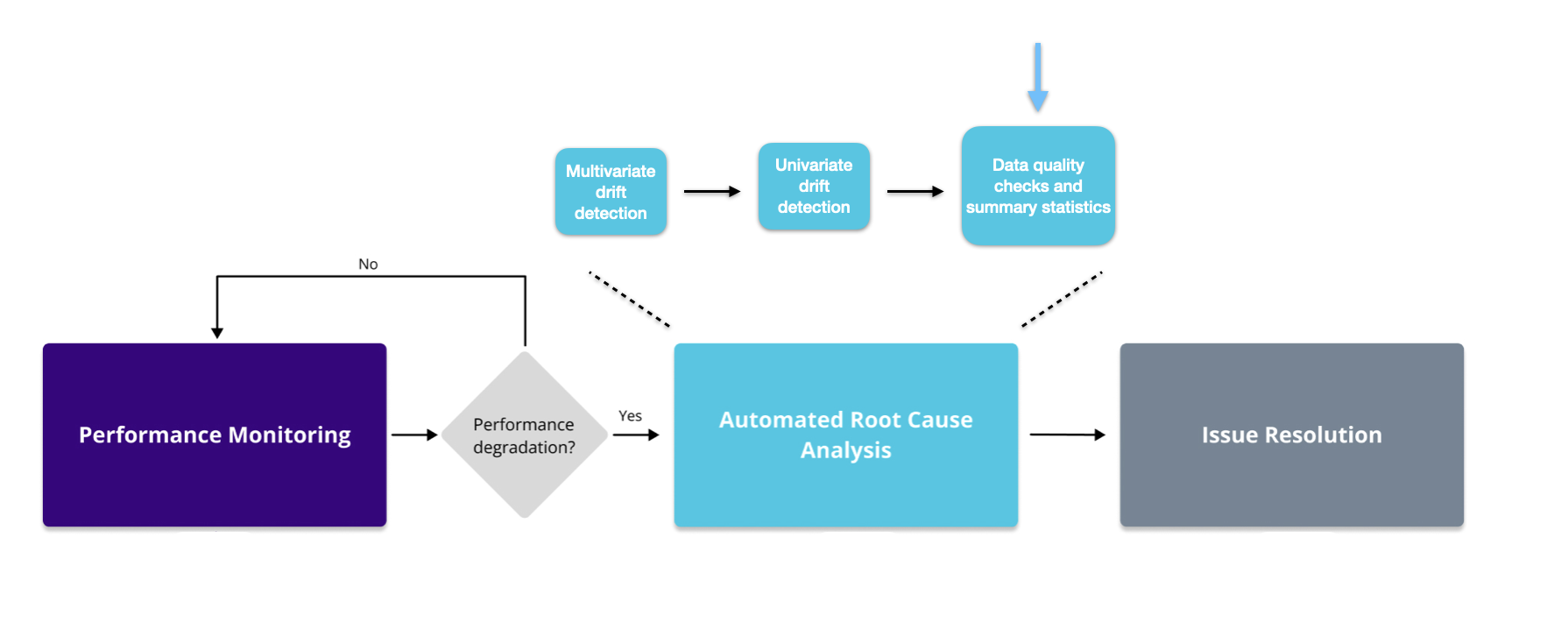
Data quality checks and summary statistics
Monitoring Machine Learning in Python

Hakim Elakhrass
Co-founder and CEO of NannyML
What are data quality checks and summary statistics?
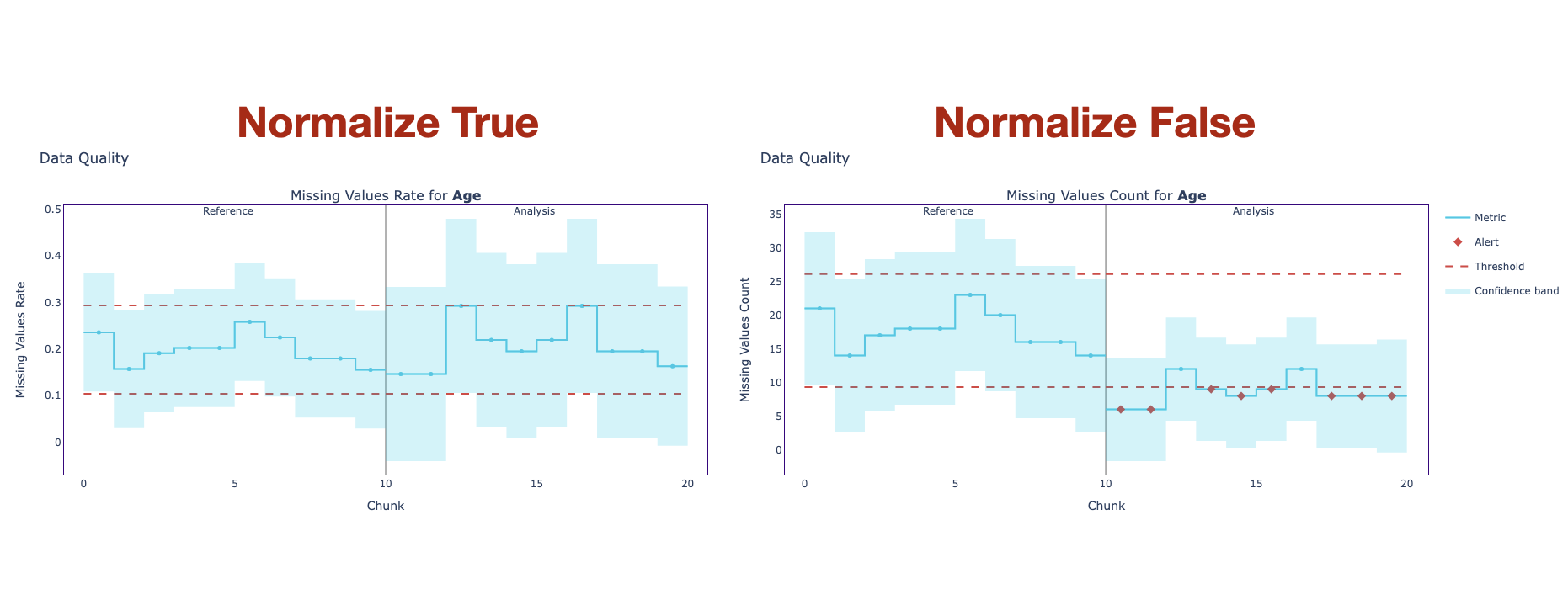
Missing values plot
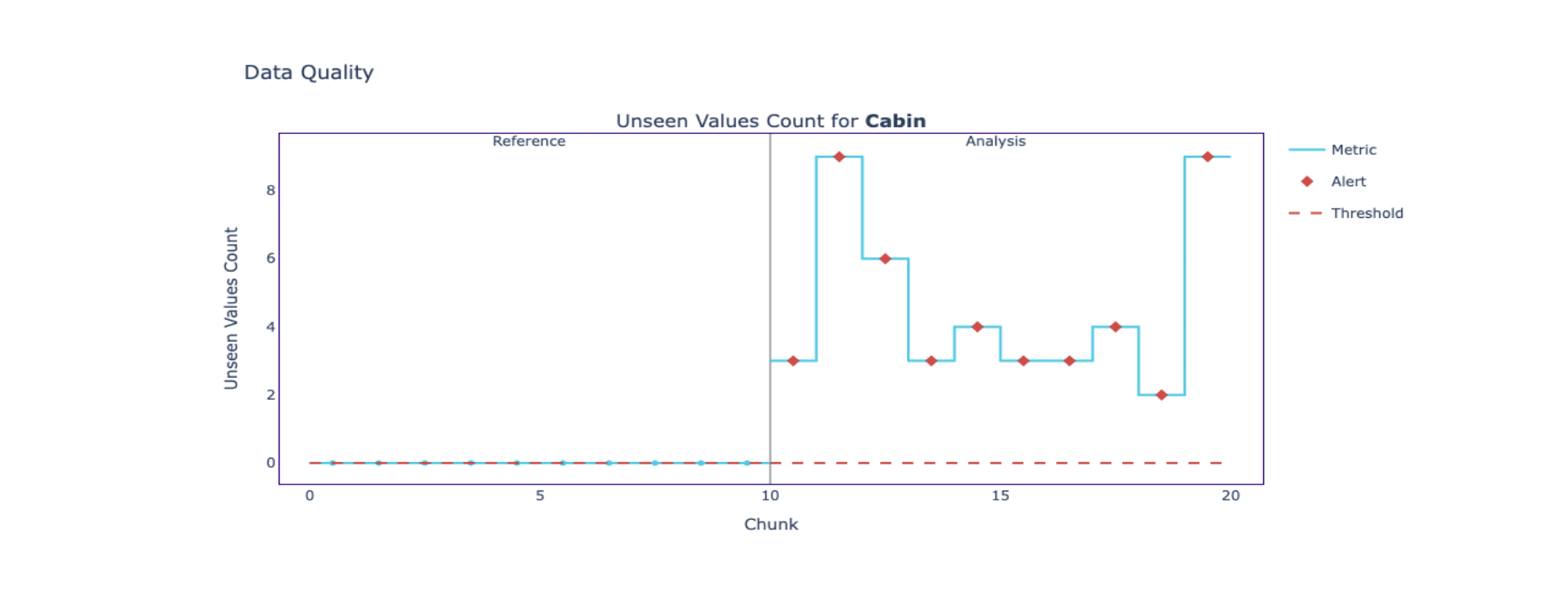
Unseen values detection
# Fit, calculate and plot the rate of the unseen values
us_calc.fit(reference)
us_results = us_calc.calculate(analysis)
us_results.plot()