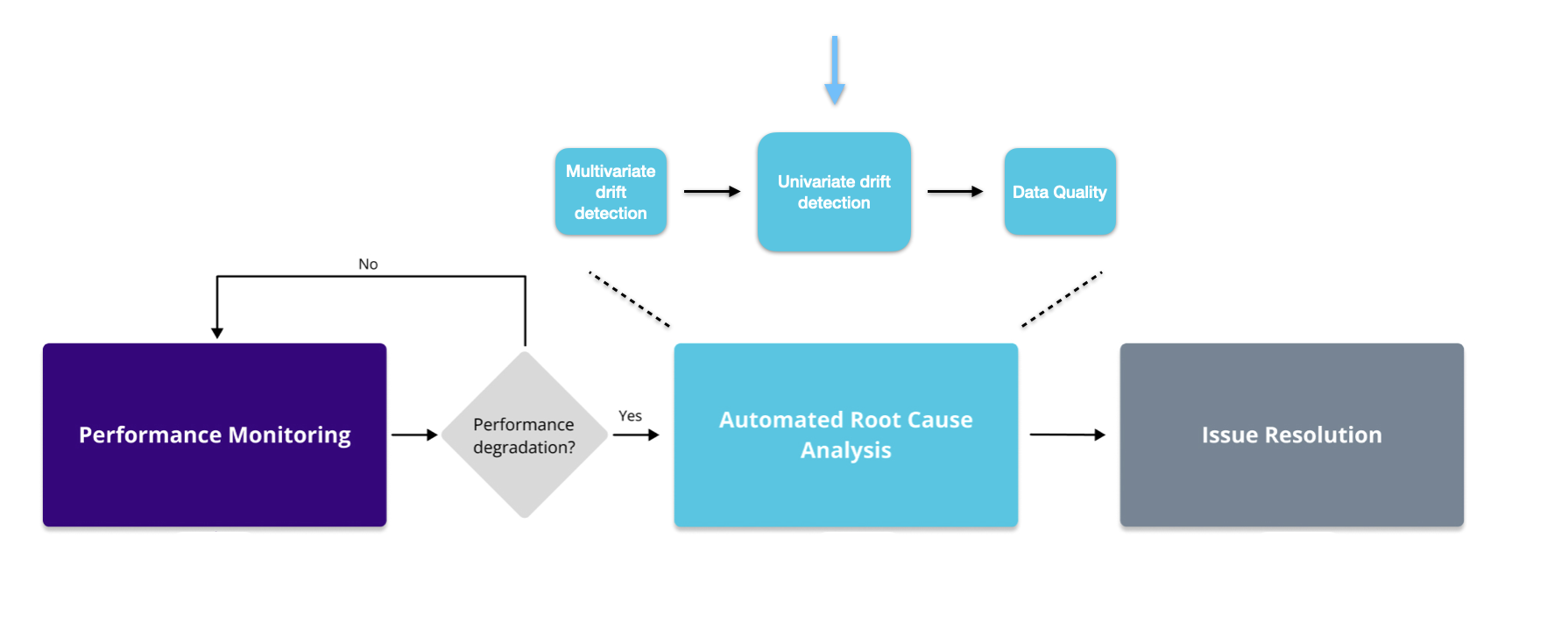
Univariate drift detection
Monitoring Machine Learning in Python

Hakim Elakhrass
CEO and co-founder
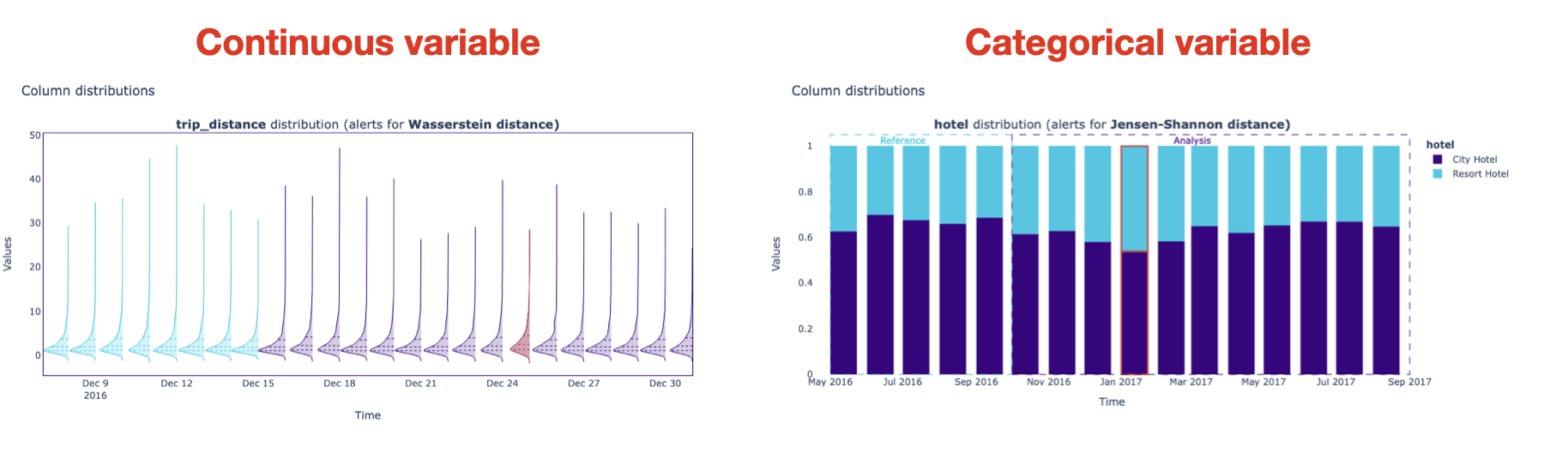
What is univariate drift detection?
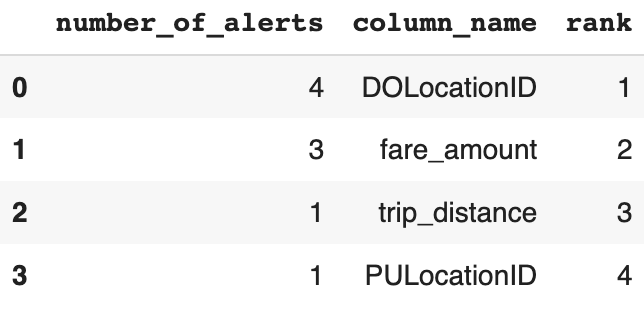
Alert count ranker
# Initialize the alert count ranker
alert_count_ranker = nannyml.AlertCountRanker()
alert_count_ranked_results = alert_count_ranker.rank(
uv_results,
only_drifting=False)
# Display the results
display(alert_count_ranked_results)
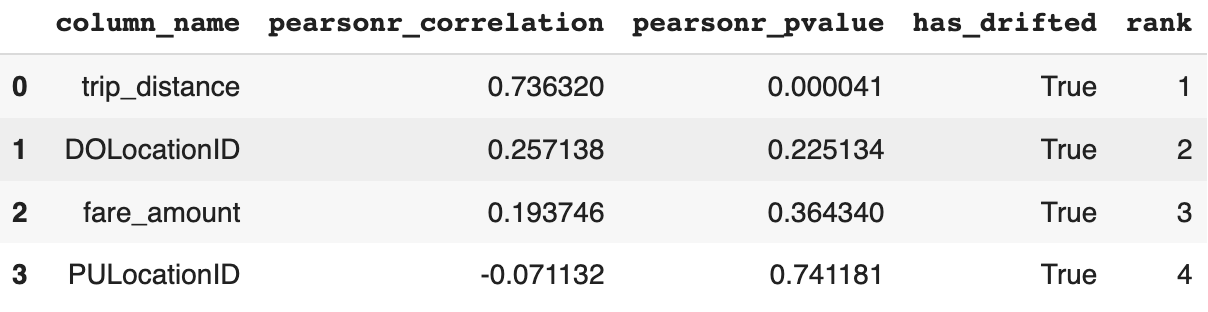
Correlation ranker
# Initialize the correlation ranker
correlation_ranker = nannyml.CorrelationRanker()
correlation_ranker.fit(perf_results.filter(period='reference'))
correlation_ranked_results = correlation_ranker.rank(uv_results, perf_results)
# Display the results
display(correlation_ranked_results)
Feature distribution plot